目录
Advanced optimization technology
链接:
http://speech.ee.ntu.edu.tw/~tlkagk/courses/MLDS_2015_2/Lecture/RNN%20training%20(v6).pdf
Problem
the error surface is rough
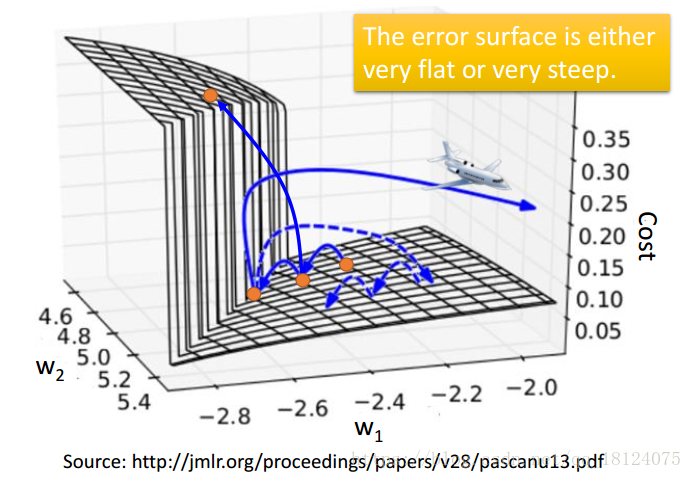
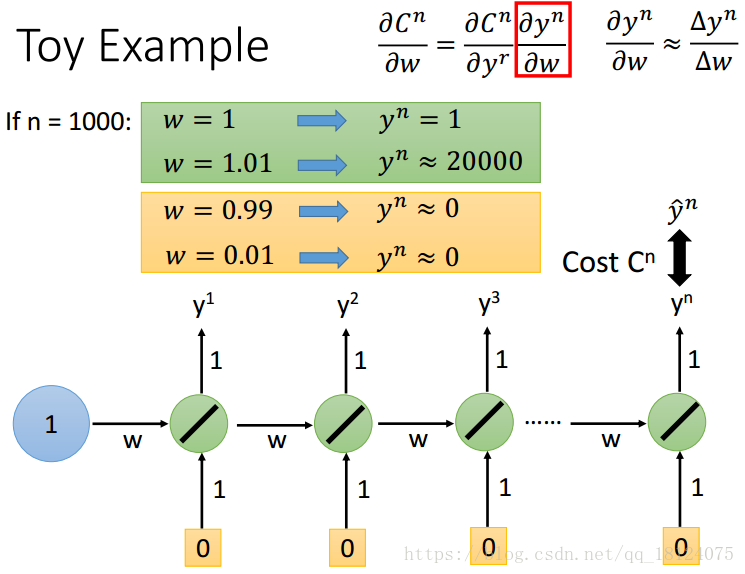
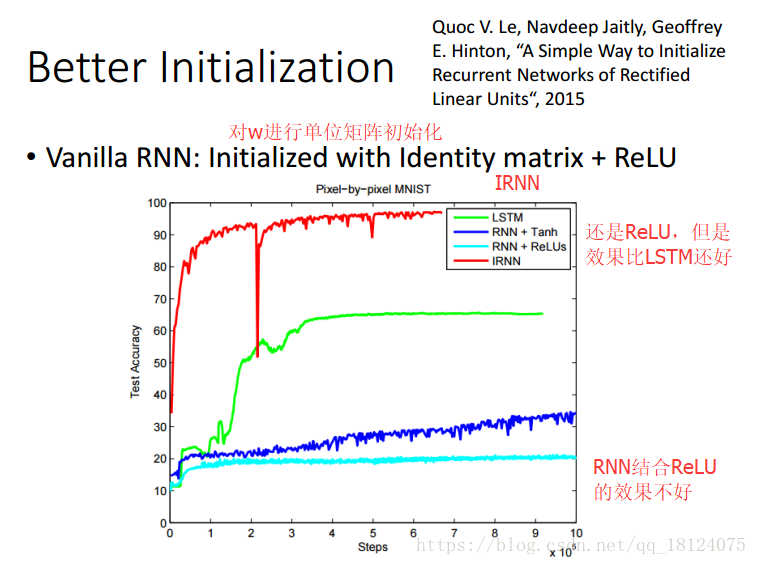
误差表面凹凸不平,可能上一步很高,下一步就会跌得很深。RNN就是一个很深的DNN,在第二张图可以知道,对于RNN来说使用Relu并不是一个比较好的结果,一般采取的激活函数是tanh或者sigmoid。而且这个输出的值也是可大可小。
Clipping the gradients
为了解决凹凸不平的悬崖问题,我们让飞出去的gradient,设定一个阈值,超过了就只能在这个值范围内。如果在悬崖边,我们也可以向前多走一步。
Advanced optimization technology
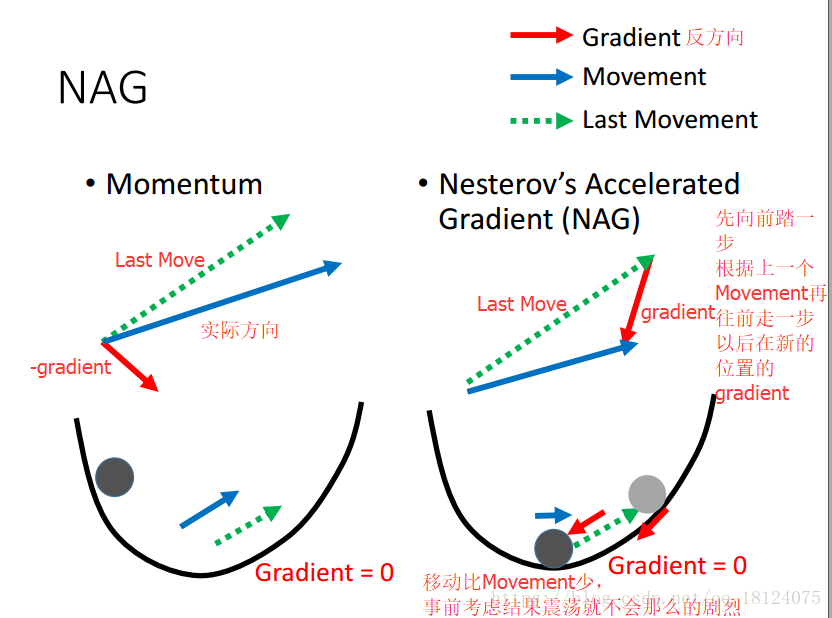
NAG (NAG是Momentum的进化版)
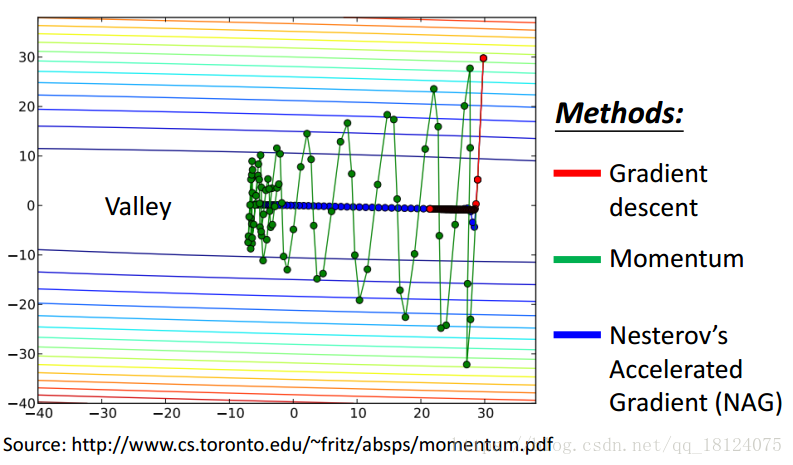
RMSprop (RMSprop是Adagrad进化版)
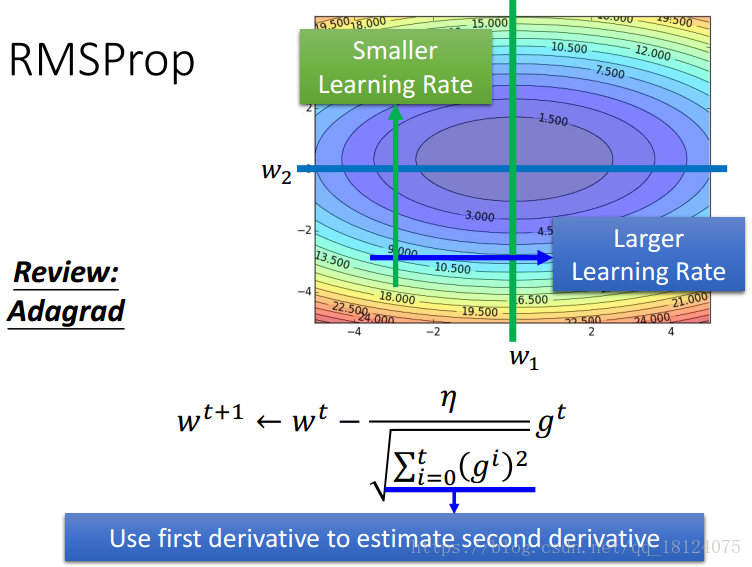

其实RMSProp的形式和Adagrad差不多,不同之处在于过去的gradient会乘以一个权值,越向前对当前的gradient影响越小。
Try LSTM (or other variants)
LSTM can address the gradient vanishing problem.
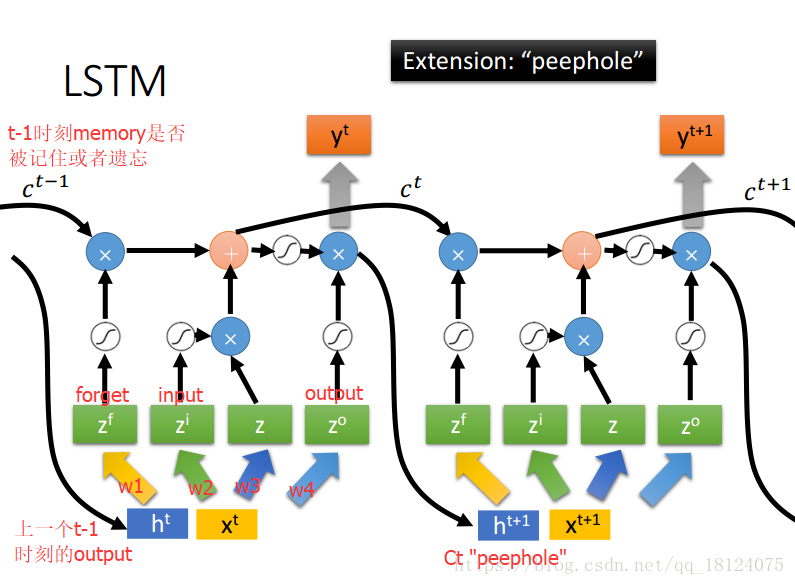
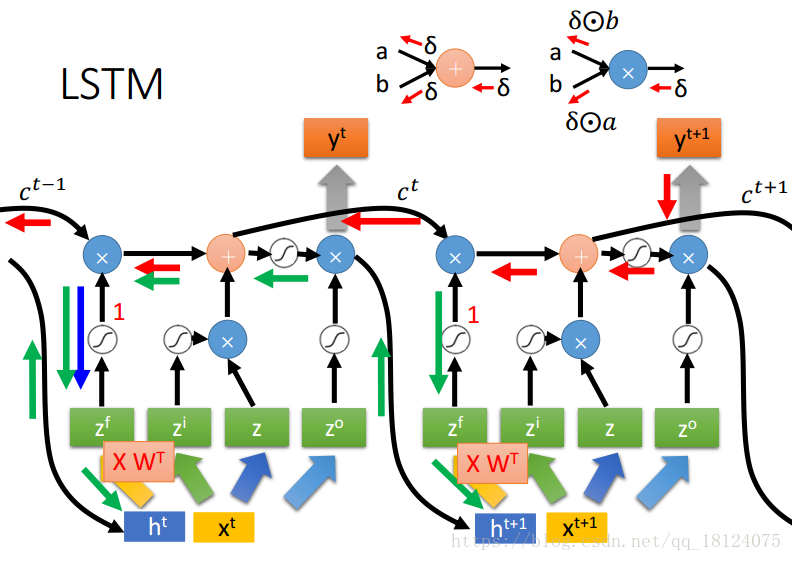
RNN和LSTM对待Memory的本质不同导致了LSTM能够解决梯度消失问题。在LSTM的加法计算中,微分为1;在乘法计算中,如果forget gate=1,一路畅通无阻(常数),所以微分为Constant Error Carrousol (CEC), 红色箭头为error signal,由CEC可知,error signal的值保证不会小,但是不能保证太大,所以不能够解决梯度爆炸问题;而且由绿线可知,XWT可大可小,可小无所谓,error signal本来就很大。但是如果XWT很大,就会出现梯度爆炸的问题。
其他的变形:
GRU: Cho, Kyunghyun, et al. "Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation“, EMNLP, 2014.
SCRN: Mikolov, Tomas, et al. "Learning longer memory in recurrent neural networks“, ICLR 2015.