1 任务描述
本实验是训练一个双向LSTM,并在IMDB数据集上完成情感分类任务
2 具体实现
(1)引入必要的包
from __future__ import print_function
import numpy as np
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense,Dropout,Embedding,LSTM,Bidirectional
from keras.datasets import imdb(2)设置一些常量
# 设置最大特征的数量,对于文本,就是处理的最大单词数量。若被设置为整数,则被限制为待处理数据集中最常见的max_features个单词
max_features=20000
# 设置每个文本序列的最大长度,当序列的长度小于maxlen时,将用0来进行填充,当序列的长度大于maxlen时,则进行截断
maxlen=100
# 设置训练的轮次
batch_size=32(3)加载数据
在Keras的数据集中有IMDB数据集,因此只需要按照格式加载即可
print("loading data ...")
# 加载数据
(x_train,y_train),(x_test,y_test)=imdb.load_data(num_words=max_features)
# 查看数据大小
print(len(x_train),'train sequences')
print(len(x_test),'test sequences')loading data ...
25000 train sequences
25000 test sequences
(4)数据处理
首先查看数据格式
print(x_train[0])[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 19193, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 10311, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 12118, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]
可以看出,每一条文本都已经处理成了序列形式。在序列中,每一个单词都用其字典中对应的索引表示。因此这里省去了很多文本基本预处理的步骤。
接下来查看标签数据格式
print(y_train[:10])[1 0 0 1 0 0 1 0 1 0]
看来是极性情感分类,积极,消极两种情感。
由于训练集中的文本已经表示成了序列模型,因此只需要利用pad_sequences将每个序列整理成相同长度即可。
print('Pad sequences (samples x time)')
# 将文本序列处理成长度相同的序列
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
print('x_train shape:', x_train.shape)
print('x_test shape:', x_test.shape)
y_train = np.array(y_train)
y_test = np.array(y_test)Pad sequences (samples x time)
x_train shape: (25000, 100)
x_test shape: (25000, 100)
(5)创建模型及训练
# 创建网络结构
model=Sequential()
model.add(Embedding(max_features,128,input_length=maxlen))
model.add(Bidirectional(LSTM(64)))
model.add(Dropout(0.5))
model.add(Dense(1,activation='sigmoid'))
# 编译模型
model.compile('adam','binary_crossentropy',metrics=['accuracy'])
# 训练模型
print('Train...')
model.fit(x_train, y_train,batch_size=batch_size,epochs=4,validation_data=[x_test, y_test])Train...
Train on 25000 samples, validate on 25000 samples
Epoch 1/4
25000/25000 [==============================] - 72s 3ms/step - loss: 0.4298 - acc: 0.8014 - val_loss: 0.3477 - val_acc: 0.8498
Epoch 2/4
25000/25000 [==============================] - 71s 3ms/step - loss: 0.2295 - acc: 0.9122 - val_loss: 0.4055 - val_acc: 0.8426
Epoch 3/4
25000/25000 [==============================] - 71s 3ms/step - loss: 0.1345 - acc: 0.9510 - val_loss: 0.4588 - val_acc: 0.8368
Epoch 4/4
25000/25000 [==============================] - 71s 3ms/step - loss: 0.0791 - acc: 0.9731 - val_loss: 0.5615 - val_acc: 0.8232
(6)可视化网络结构
from keras.utils import plot_model
plot_model(model,to_file="./imdb_bidirectional_lstm.png")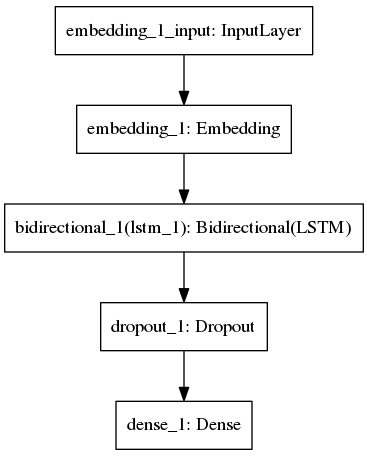
3 小结
大概半个月没写这一类代码了,有些方法的使用有点模糊了,通过这个例子,可以快速的回忆起相关的知识点来,于是也把相关的知识点又重新整理了下。在本例子中,主要的知识点有以下几点:
(1)填充序列pad_sequences
方法原型:
keras.preprocessing.sequence.pad_sequences(sequences,maxlen=None, dtype=’int32’,padding=’pre’, truncating=’pre’, value=0.)
其主要功能就是将sequences列表中的每个序列填充或截断成maxlen的长度,填充的位置由padding参数决定,截断的位置由truncating参数决定。
(2)嵌入层 Embedding
方法原型:
keras.layers.embeddings.Embedding(input_dim, output_dim, embeddings_initializer=’uniform’, embeddings_regularizer=None, activity_regularizer=None, embeddings_constraint=None, mask_zero=False, input_length=None)
其主要功能是将正整数(下标)转化为具有固定大小的向量。该层只能作为模型的第一层。
参数:
①input_dim:字典长度,即输入数据的最大下标+1,针对本实验,由于在读取数据时,就限制了所要保留的单词个数为max_features个,因此,本实验室的input_dim=max_features
②output_dim:代表全连接嵌入的维度,通俗一点就是词向量的维度。
③input_length:当输入序列的长度固定是,该值为其长度。也就是每个序列的长度(由于一般情况下都会将所有序列的长度填充成相同长度了)如果要在该层后接Flatten层,然后接Dense层,则必须指定该参数,否则Dense层的输出维度无法自动推断。
(3)文本预处理-分词器Tokenizer
尽管本实验中没有涉及到文本预处理部分,但是对于和文本打交道,这些文本预处理方法是必须掌握的,于是这里也一并贴出来。
利用Keras提供的文本预处理方法貌似非常方便,可以简单的归纳为四步:
①创建分词器:tokenizer=Tokenizer(filters=’!”#$%&()*+,-./:;<=>?@[\]^_`{|}~\t\n’,lower=True,split=” “)
②用文本列表来训练分词器:tokenizer.fit_on_texts(X)
③建立词汇表,并为每个单词或字符串创建对应的索引:vocab=tokenizer.word_index
④将训练集文本和测试集文本都映射成单词id组成的序列:tokenizer.texts_to_sequences(x_train)
Tokenizer是一个用于向量化文本,或将文本转换为序列的类。能过满足文本处理需求,具体可以见官方文档:https://keras-cn.readthedocs.io/en/latest/preprocessing/text/