版权声明:笔者博客文章主要用来作为学习笔记使用,内容大部分来自于自互联网,并加以归档整理或修改,以方便学习查询使用,只有少许原创,如有侵权,请联系博主删除! https://blog.csdn.net/qq_42642945/article/details/88853076

01_案例一:鸢尾花数据SVM分类
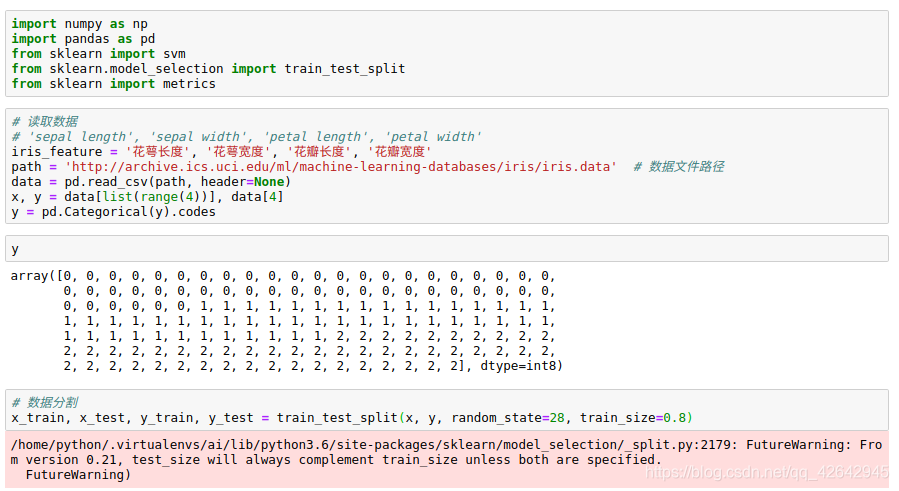
import numpy as np
import pandas as pd
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.datasets import load_iris
# 读取数据
# 'sepal length', 'sepal width', 'petal length', 'petal width'
iris_feature = '花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度'
path = 'http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data' # 数据文件路径
data = pd.read_csv(path, header=None)
x, y = data[list(range(4))], data[4]
y = pd.Categorical(y).codes
# 数据分割
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=28, train_size=0.8)
svm.SVC API说明:
- 功能:使用SVM分类器进行模型构建
- 参数说明:
- C: 误差项的惩罚系数,默认为1.0;一般为大于0的一个数字,C越大表示在训练过程中对于总误差的关注度越高,也就是说当C越大的时候,对于训练集的表现会越好,
- 但是有可能引发过度拟合的问题(overfiting)
- kernel:指定SVM内部核函数的类型,可选值:linear、poly、rbf、sigmoid、precomputed(基本不用,有前提要求,要求特征属性数目和样本数目一样);默认是rbf;
- degree:当使用多项式函数作为svm内部的函数的时候,给定多项式的项数,默认为3
- gamma:当SVM内部使用poly、rbf、sigmoid的时候,核函数的系数值,当默认值为auto的时候,实际系数为1/n_features
- coef0: 当核函数为poly或者sigmoid的时候,给定的独立系数,默认为0
- probability:是否启用概率估计,默认不启动,不太建议启动
- shrinking:是否开启收缩启发式计算,默认为True
- tol: 模型构建收敛参数,当模型的的误差变化率小于该值的时候,结束模型构建过程,默认值:1e-3
- cache_size:在模型构建过程中,缓存数据的最大内存大小,默认为空,单位MB
- class_weight:给定各个类别的权重,默认为空
- max_iter:最大迭代次数,默认-1表示不限制
- decision_function_shape: 决策函数,可选值:ovo和ovr,默认为None;推荐使用ovr;(1.7以上版本才有)
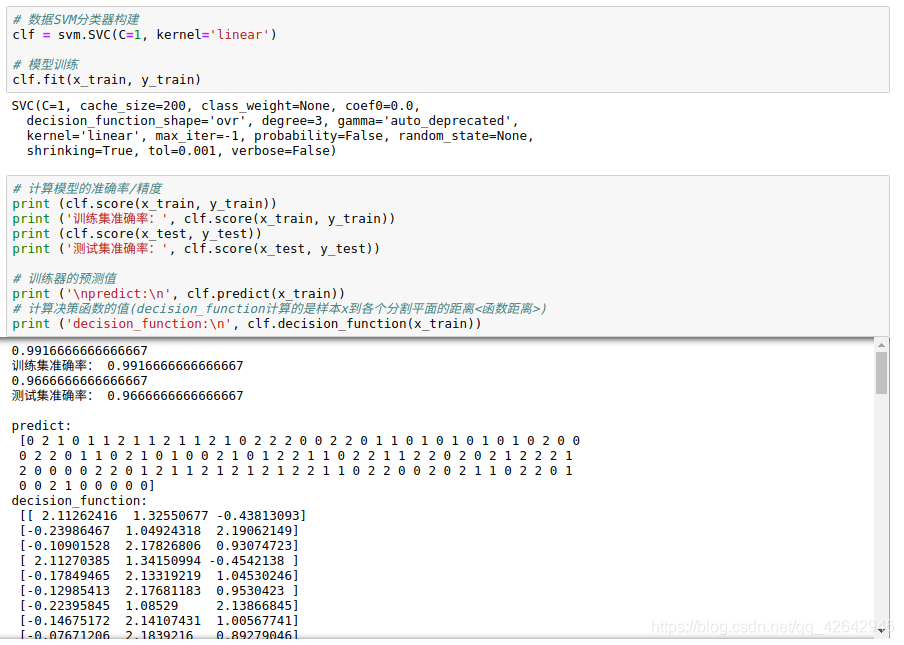
# 数据SVM分类器构建
clf = svm.SVC(C=1, kernel='linear')
# 模型训练
clf.fit(x_train, y_train)
# 计算模型的准确率/精度
print (clf.score(x_train, y_train))
print ('训练集准确率:', clf.score(x_train, y_train))
print (clf.score(x_test, y_test))
print ('测试集准确率:', clf.score(x_test, y_test))
# 训练器的预测值
print ('\npredict:\n', clf.predict(x_train))
# 计算决策函数的值(decision_function计算的是样本x到各个分割平面的距离<函数距离>)
print ('decision_function:\n', clf.decision_function(x_train))
02_案例二:不同SVM核函数效果比较
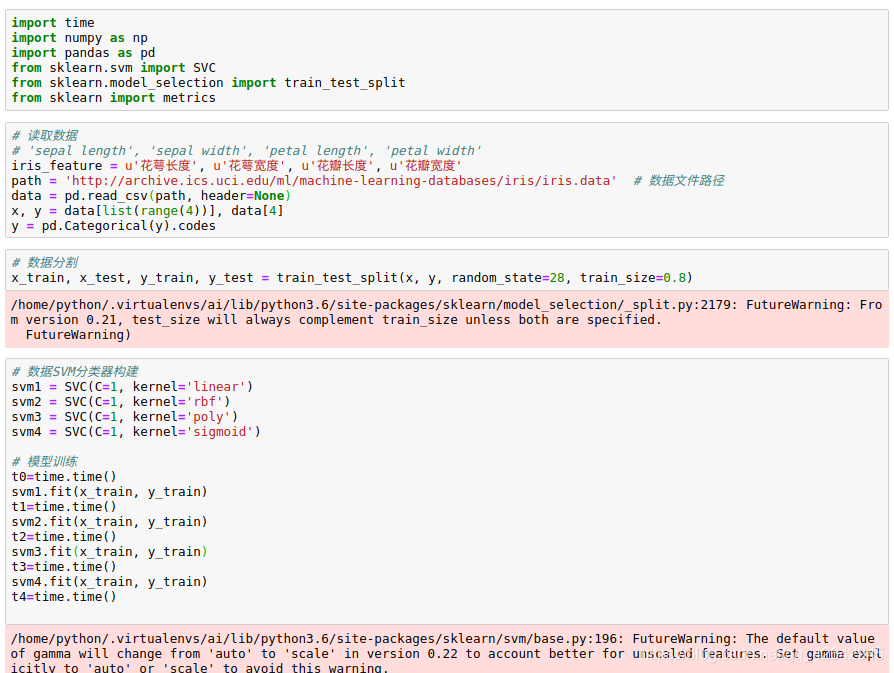
import time
import numpy as np
import pandas as pd
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn import metrics
# 读取数据
# 'sepal length', 'sepal width', 'petal length', 'petal width'
iris_feature = u'花萼长度', u'花萼宽度', u'花瓣长度', u'花瓣宽度'
path = 'http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data' # 数据文件路径
data = pd.read_csv(path, header=None)
x, y = data[list(range(4))], data[4]
y = pd.Categorical(y).codes
# 数据分割
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=28, train_size=0.8)
# 数据SVM分类器构建
svm1 = SVC(C=1, kernel='linear')
svm2 = SVC(C=1, kernel='rbf')
svm3 = SVC(C=1, kernel='poly')
svm4 = SVC(C=1, kernel='sigmoid')
# 模型训练
t0=time.time()
svm1.fit(x_train, y_train)
t1=time.time()
svm2.fit(x_train, y_train)
t2=time.time()
svm3.fit(x_train, y_train)
t3=time.time()
svm4.fit(x_train, y_train)
t4=time.time()
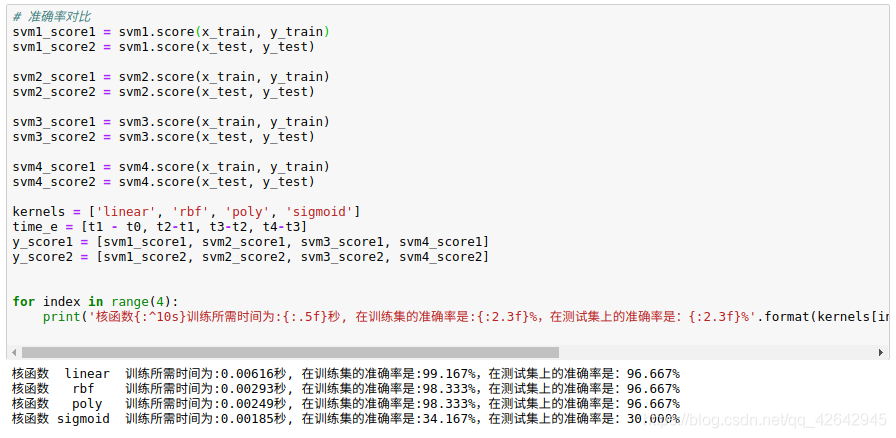
# 准确率对比
svm1_score1 = svm1.score(x_train, y_train)
svm1_score2 = svm1.score(x_test, y_test)
svm2_score1 = svm2.score(x_train, y_train)
svm2_score2 = svm2.score(x_test, y_test)
svm3_score1 = svm3.score(x_train, y_train)
svm3_score2 = svm3.score(x_test, y_test)
svm4_score1 = svm4.score(x_train, y_train)
svm4_score2 = svm4.score(x_test, y_test)
kernels = ['linear', 'rbf', 'poly', 'sigmoid']
time_e = [t1 - t0, t2-t1, t3-t2, t4-t3]
y_score1 = [svm1_score1, svm2_score1, svm3_score1, svm4_score1]
y_score2 = [svm1_score2, svm2_score2, svm3_score2, svm4_score2]
for index in range(4):
print('核函数{:^10s}训练所需时间为:{:.5f}秒, 在训练集的准确率是:{:2.3f}%,在测试集上的准确率是:{:2.3f}%'.format(kernels[index], time_e[index], y_score1[index] * 100, y_score2[index] * 100))
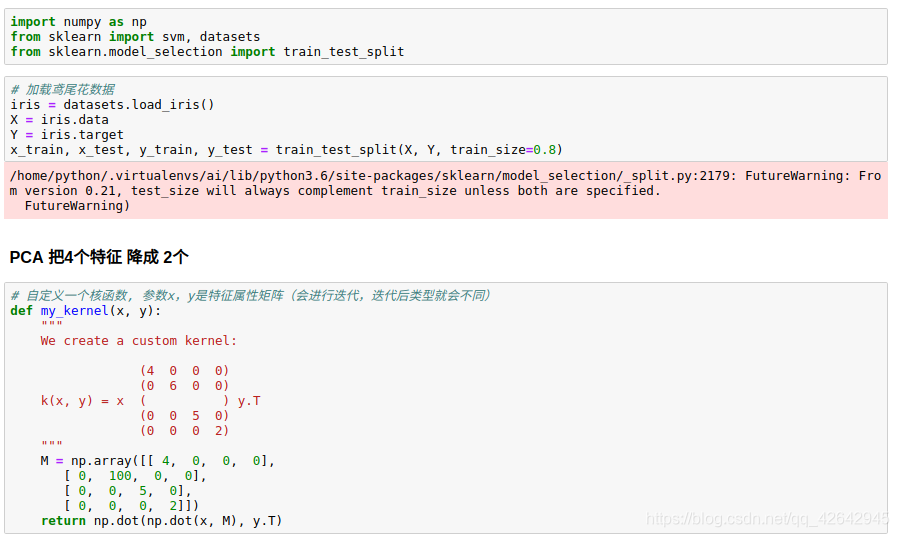
03_案例三:自定义SVM内部核函数
import numpy as np
from sklearn import svm, datasets
from sklearn.model_selection import train_test_split
# 加载鸢尾花数据
iris = datasets.load_iris()
X = iris.data
Y = iris.target
x_train, x_test, y_train, y_test = train_test_split(X, Y, train_size=0.8)
# PCA 把4个特征 降成 2个
# 自定义一个核函数, 参数x,y是特征属性矩阵(会进行迭代,迭代后类型就会不同)
def my_kernel(x, y):
"""
We create a custom kernel:
(4 0 0 0)
(0 6 0 0)
k(x, y) = x ( ) y.T
(0 0 5 0)
(0 0 0 2)
"""
M = np.array([[ 4, 0, 0, 0],
[ 0, 100, 0, 0],
[ 0, 0, 5, 0],
[ 0, 0, 0, 2]])
return np.dot(np.dot(x, M), y.T)
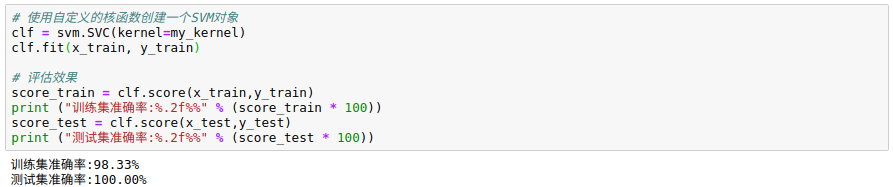
# 使用自定义的核函数创建一个SVM对象
clf = svm.SVC(kernel=my_kernel)
clf.fit(x_train, y_train)
# 评估效果
score_train = clf.score(x_train,y_train)
print ("训练集准确率:%.2f%%" % (score_train * 100))
score_test = clf.score(x_test,y_test)
print ("测试集准确率:%.2f%%" % (score_test * 100))
04_案例四:手写数字识别
from sklearn import datasets, svm, metrics
import matplotlib.pyplot as plt
# 设置字体变出现中文乱码
plt.rcParams['font.family'] = ['Arial Unicode MS']
# 加载数字图片数据
digits = datasets.load_digits()
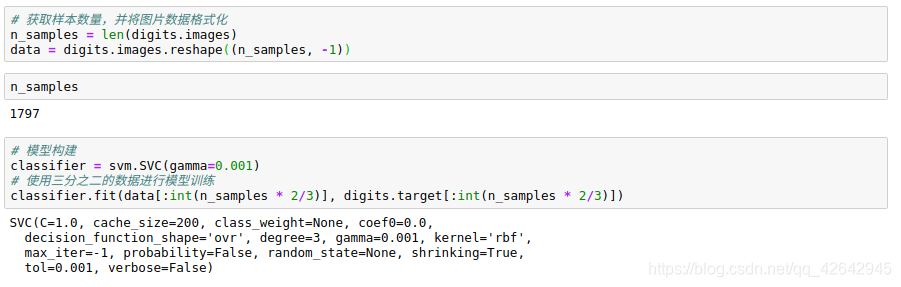
# 获取样本数量,并将图片数据格式化
n_samples = len(digits.images)
data = digits.images.reshape((n_samples, -1))
# 模型构建
classifier = svm.SVC(gamma=0.001)
# 使用三分之二的数据进行模型训练
classifier.fit(data[:int(n_samples * 2/3)], digits.target[:int(n_samples * 2/3)])
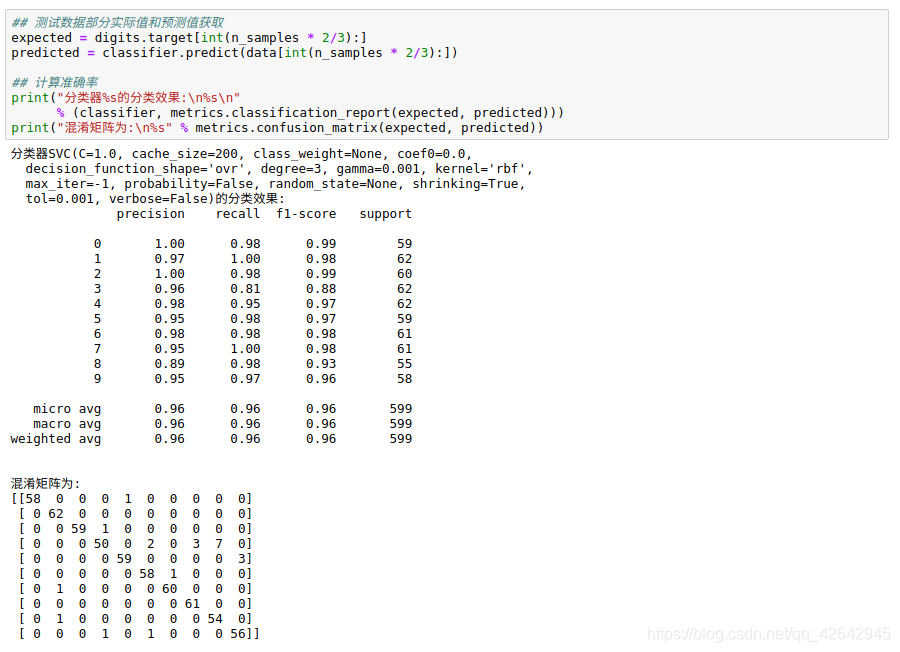
## 测试数据部分实际值和预测值获取
expected = digits.target[int(n_samples * 2/3):]
predicted = classifier.predict(data[int(n_samples * 2/3):])
## 计算准确率
print("分类器%s的分类效果:\n%s\n"
% (classifier, metrics.classification_report(expected, predicted)))
print("混淆矩阵为:\n%s" % metrics.confusion_matrix(expected, predicted))
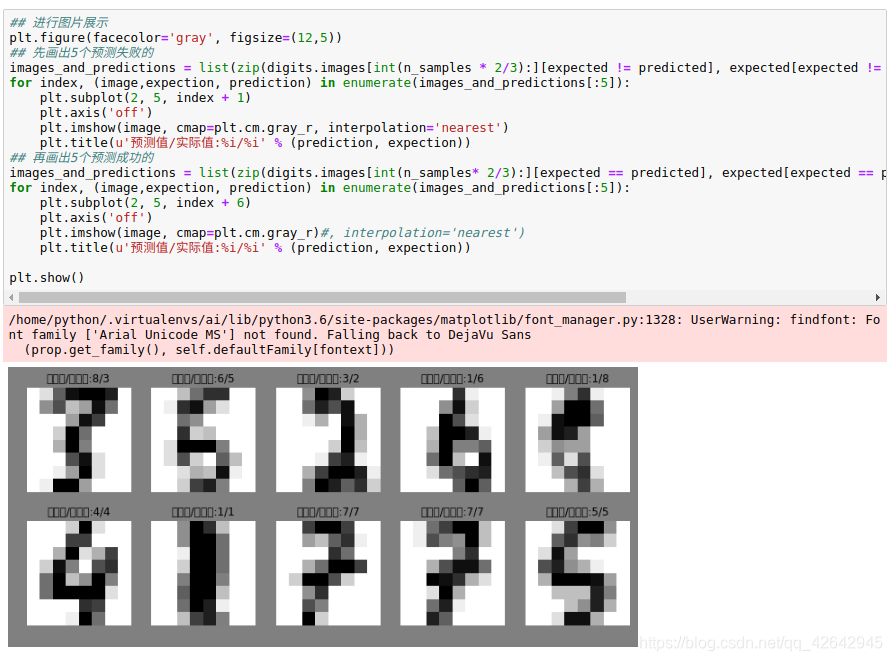
## 进行图片展示
plt.figure(facecolor='gray', figsize=(12,5))
## 先画出5个预测失败的
images_and_predictions = list(zip(digits.images[int(n_samples * 2/3):][expected != predicted], expected[expected != predicted], predicted[expected != predicted]))
for index, (image,expection, prediction) in enumerate(images_and_predictions[:5]):
plt.subplot(2, 5, index + 1)
plt.axis('off')
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
plt.title(u'预测值/实际值:%i/%i' % (prediction, expection))
## 再画出5个预测成功的
images_and_predictions = list(zip(digits.images[int(n_samples* 2/3):][expected == predicted], expected[expected == predicted], predicted[expected == predicted]))
for index, (image,expection, prediction) in enumerate(images_and_predictions[:5]):
plt.subplot(2, 5, index + 6)
plt.axis('off')
plt.imshow(image, cmap=plt.cm.gray_r)#, interpolation='nearest')
plt.title(u'预测值/实际值:%i/%i' % (prediction, expection))
plt.show()