惭愧啊,读研的时候学得正是模式识别;当看着书本上都是公式推导、博士师兄们也都在公式推导研究新算法的时候,排斥心理到了顶点,从此弃疗。
工作三年,重新捡起
因为重视实际操作,所以选择了《python 深度学习》这本书,辅助Andrew Ng视频+博客,希望能够从应用的角度去使用机器学习这门工具,不重蹈覆辙
在此,记录自己的学习过程。
不想老生常谈,别人讲得很好的,就直接引用了;所以这会是一个很“草率”的系列...
一、 线性回归, logistic 回归,梯度下降算法
参考 Andrew Ng 机器学习视频的chap2, chap5, chap7, 截图均来自课程中的slides
多变量线性回归:


logistic 回归:

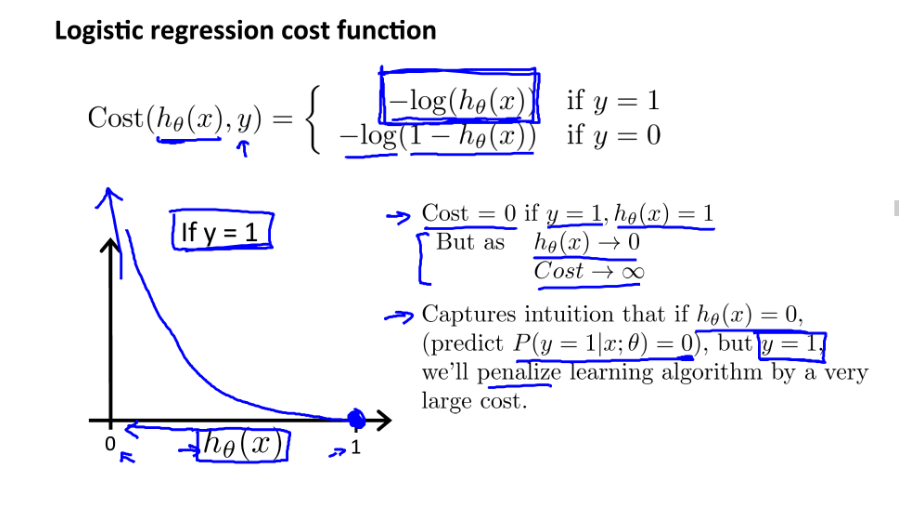
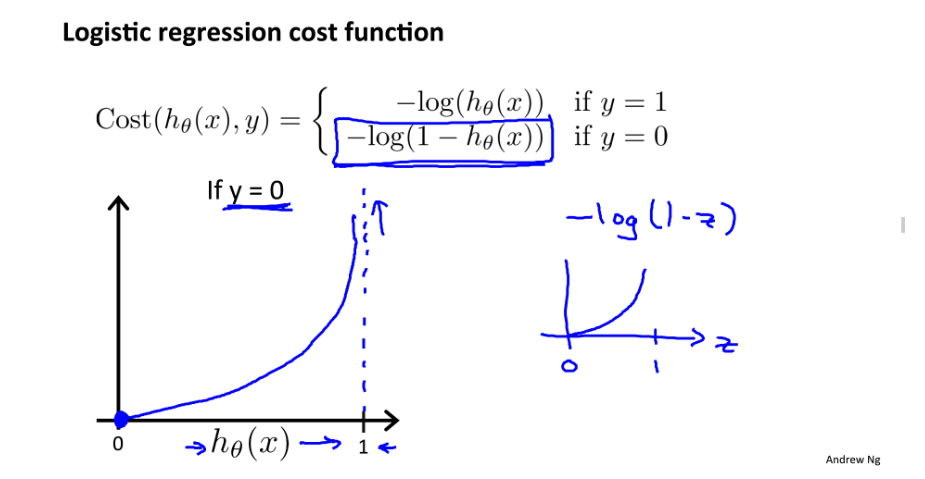

梯度下降算法细节:
1. 梯度下降的直观理解
想象你在山上的某一点,要以最快的速度下山。 学习率相当于步长,偏导数相当于方向,偏导数越接近于0,越接近一个局部最小点。
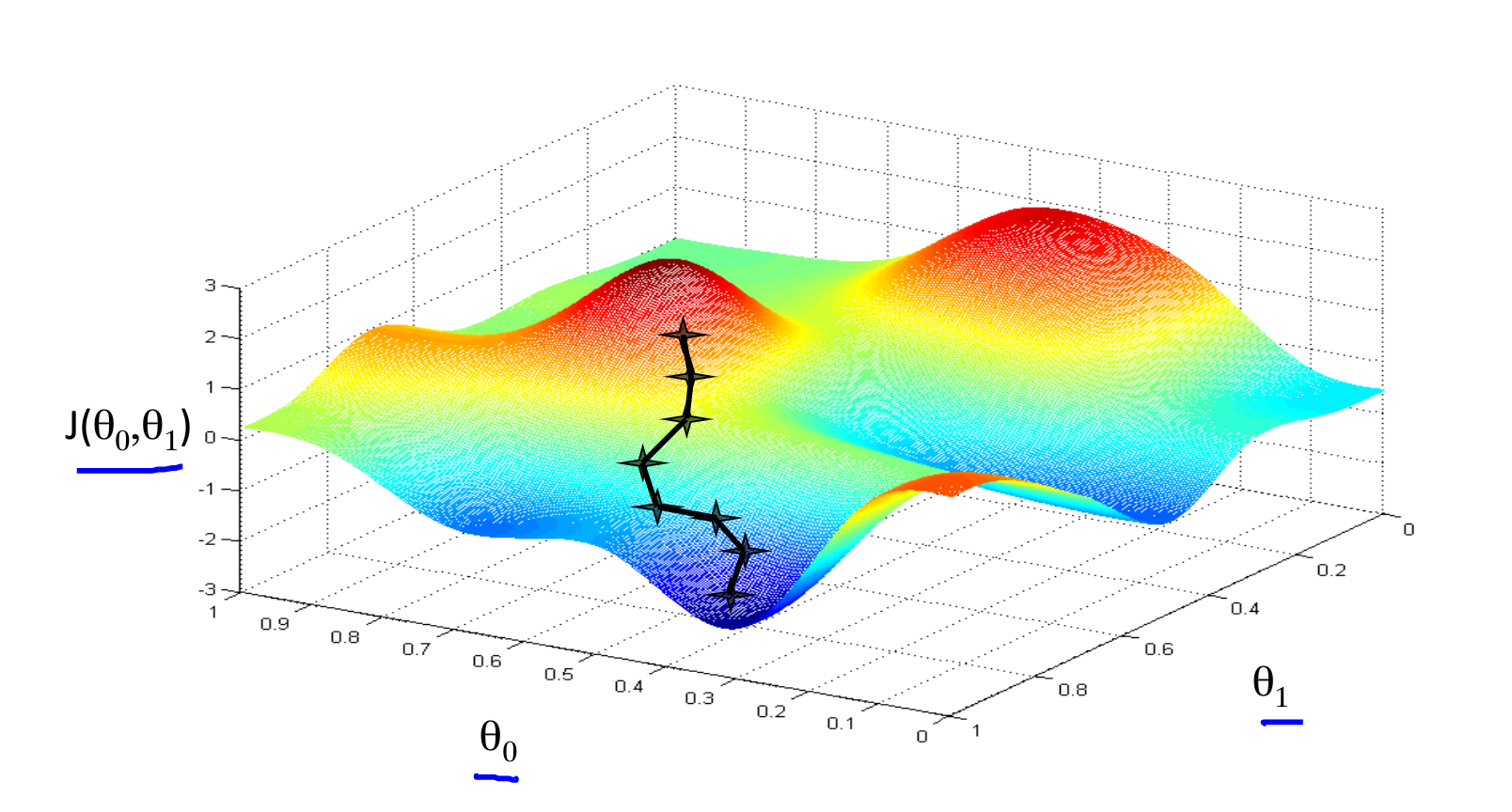
初始位置选择不一样,到达的局部最优值也不同
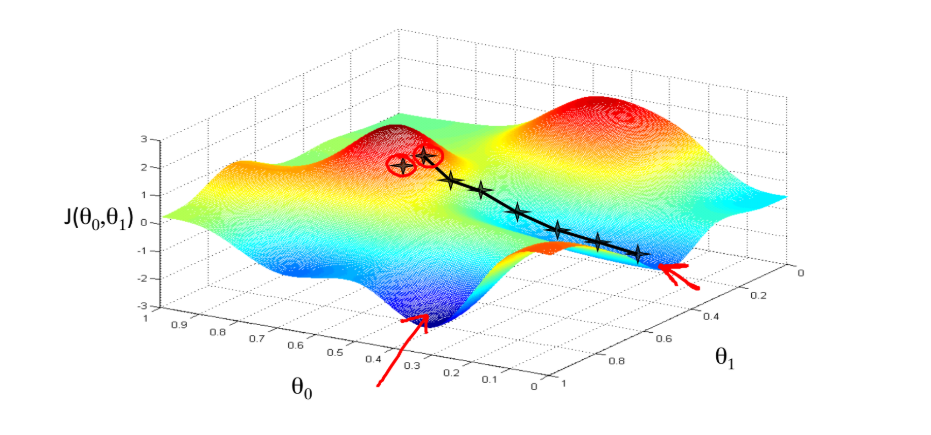
2. 学习率对梯度下降收敛的影响


3. 特征缩放与均值归一化, 有利于梯度下降算法的收敛
特征缩放:将每个特征都缩放到近似的范围,一般是[-1, 1]
均值归一化:通过 (x-u)/(max-min) 运算,使每个特征的均值都近似于0
二、神经网络概念与反向传播算法
基本上也是看了Andrew Ng机器学习视频的chap9 chap10,但他直接给出了方向传播算法的更新过程,不是很理解
可以参考这篇推导过程,写得很好,关键是用到了链式法则
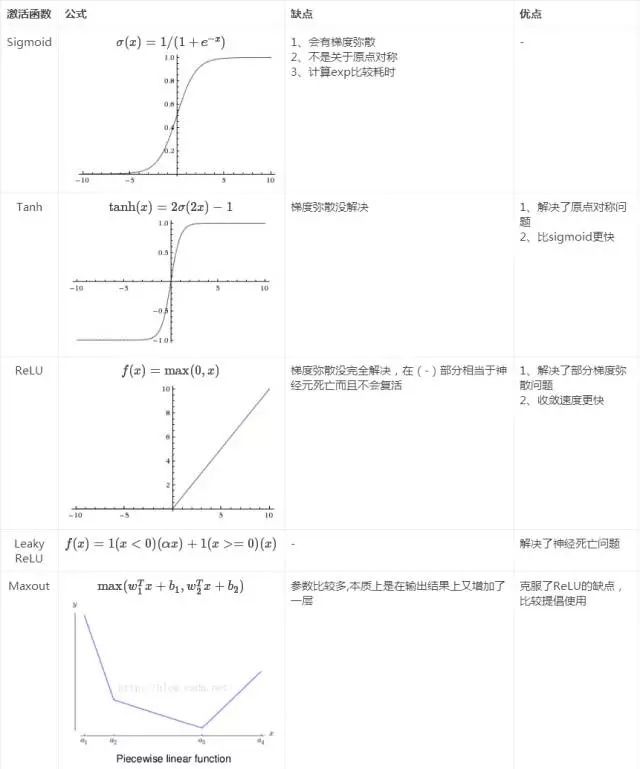
三、神经网络激活函数的选择
激活函数给神经网络引入了非线性因素,关于如何选择激活函数可参考
现在一般推荐ReLU, 如果效果不好再使用LeakyReLU, Maxout
图片转自知乎, Maxout曲线那里有歧义,建议详细看下Maxout的解释: