刚开始了解知识图谱的时候,视频中主要介绍的是用deepdive工具从文本中抽取关系,deepdive的环境不太好配,卡在那里很久,后来感觉deepdive用在粮食领域关系抽取中不是太合适,主要是因为:
① deepdive属于监督学习,它通过已知有关系的实体对和文本去训练模型,然后预测关系。而我们是利用粮食大辞典中内容抽取关系,没有标注数据,没法进行监督训练。
② deepdive是对一种关系进行训练,如两个公司的交易关系,如果换成其他关系,就需要重新选取特征文本,重写其中的一些代码。而粮食领域关系多且没有确定性。
③ deepdive的环境不好配,运行速度慢。
但是deepdive确实提供了一个很好的思路,有很多可以借鉴的地方,如特征的选择、梯度下降的目标,我们也可以根据它的原理利用其它机器学习算法构建自己的抽取器 。
它的关系抽取过程大致如下(以公司交易为例):
1. 数据准备,包括带抽取关系的文本、已知有关系的实体对。
文本:
泛海控股股份有限公司以272,961.98万元的价格收购控股股东中国泛海控股集团有限公司所持有的中国民生信托有限公司59.65%股权。 深圳市中洲投资控股股份有限公司以总价人民币360万元向深圳中洲集团有限公司及深圳市振洲实业有限公司收购其分别持有的深圳市中洲物业管理有限公司51%和49%股权。
......
已知关系实体对:


2. 文本处理:分词、命名实体识别、词性标注、句法分析。这些都是用NLP工具完成的。
3. 生成候选实体对。规则是同时出现在一个句中的有组织机构(ORG)标签的两个词。
如上面第一句中的 “泛海控股股份有限公司” 与 “中国民生信托有限公司” 。
第一个词会被分为 “泛海”、“控股”、“股份”、“有限”、“公司” ,这些词的标签都是ORG,将连续的标签时ORG的词连接起来就是一个公司实体。
4. 特征抽取:在含有实体对的句子中选取可能表征两者关系的词,作为实体对的特征。
以第一句为例,分词结果:
泛海,控股,股份,有限,公司,以,272,,,961.98万,元,的,价格,收购,控股,股东,中国,泛海,控股,集团,有限,公司,所持,有的,中国,民生,信托,有限,公司,59.65%,股权
红色是一个实体对,它的特征是:两词中间的词、两词左右n个词、两词中间词的个数、中间左右词的词性、是否存在特征词典中的词 等。
下图是deepdive抽取的特征表:
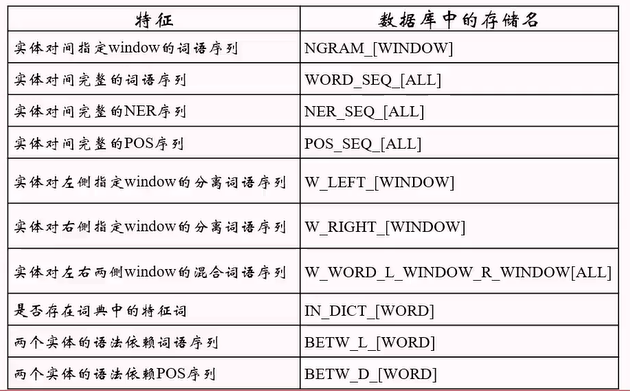
5. 根据特征构建因子图,迭代梯度下降训练特征的权重,然后通过权重生成某个实体对有关系的概率。
放弃了deepdive后寻找适合我们的关系抽取方法。
分析辞典内容发现有以下特点:
- 没有标注数据,没法通过监督学习抽取关系。(监督学习的方法就如deepdive的原理)
- 文本是通过OCR从辞典图片提取的,不能保证100%的正确率,可能有错字。
- 粮食辞典中有一些生僻的名词,如:“化学药剂防霉” 、“玉米赤霉烯酮” 等,可能会导致分词错误,虽然可以将这些词语当做自定义辞典添加进去,但是也不能全部正确分词。
- 因为是辞典内容,词语解释的句子很多语法不规范,往往省略主语,如:
“适温区:亦称有效温区。(适温区是)昆虫能够进行正常生命活动的温度区域。(适温区)可分为高适温区、最适温区和低适温区。”
这种省略如果不添加上主语会影响句法分析和句子特征提取。将主语补上再进行后续操作会更准确。
不过一般省略主语的句子的主语也就是这个句子所解释的词语,在分析的时候可以将主语设置为被解释词。 - 目录是树状结构,根据目录就可以生成一个属于...的关系。
- 目录的顺序上挨着或离得近的词语大部分是同类的,也算是一个现成的关系。
- 辞典的内容是 一个名词+名词的解释,所以解释中出现的名词(实体)有很大可能与被解释名词有某些关系,如:
爆米花@pop rice@以大米为原料制作的膨化小食品。制作方法有:将大米在密闭容器中加热加压后,瞬间离开容器; 或用砂炒法膨胀大米或阴米;或用油炸法膨胀大米或阴米。香脆可口,加人糖、盐、奶油等又可形成多种独特口味。 用白糖、饴糖等将其粘在一起可制成米花糖等食品。
在“爆米花” 的解释中就可以推测出 “大米”、“膨化食品”、“白糖” 等与之有关系,但是并不能确定关系的类型。
综合多方面原因,打算尝试以下几种方法抽取关系:
- 根据句法分析从主谓宾中抽取关系,同时可以自定义一些文本规则选取关系(如 “分布于”、“以....为食” 等关键字)。
- 通过和word2vec和TF-IDF寻找相似性高的词语。
- 直接通过词语解释中出现的辞典目录中的词语生成候选实体对。
- 在词语解释中用hanlp或其他分词工具提取关键词,与本单词组成候选实体对,因为在词语解释中出现的实体有很大可能与主词语有关系。
- 选取上面两条生成的候选实体对在句中的特征,根据特征进行无监督分类,观察结果(猜想会将“属于”、“分布于”、等关系分类出来)。
- 通过半监督学习:手动添加一些关系,如 “小家鼠-分布于-田埂” ,将同时出现小家鼠和田埂的句子都认为是分布于的关系,可以在文本中找出表征 “分布于” 这一关系的句子,其他关系同理。
仔细想想这种方法不可行,根据辞典的特点,文本量少、句子类型不广泛、同时出现一个实体对的句子很少,所以不好自动生成监督数据。
具体实现:
分词
在进行分析前首先对文本进行分词,采用的是Jieba分词模块,将辞典目录中的词语作为自定义辞典加入分词模块中,没有过滤停用词,因为可能有些词有用,需要过滤的时候在进行过滤也不麻烦。
为了避免文本读取时编码错误,所有文件都使用 “UTF-8无BOM” 编码。


import jieba jieba.load_userdict('辞典正文目录.txt') # 加载自定义词典 txt = open("辞典正文内容.txt", "r",encoding='utf-8') new_file = open('辞典分词结果.txt','w',encoding='utf-8') content = txt.readlines() for i in content: words = jieba.lcut(i) # 对每行进行分词 new_file.writelines(' '.join(words)) # 分词后将每行都写入新文件 txt.close() new_file.close()
自定义规则抽取关系
自定义规则主要有两方面:根据主谓宾、根据关键字,句法分析用的是Hanlp分词工具,因为它在分词的同时具有分析句法的功能,但是它自定义分词词典比较麻烦,并且自定义的词也不一定能够分成一个词,所以有些地方还要用Jieba分词工具。根据主谓宾句法就是抽取出 [主语-谓语-宾语] 三元组。
以下面句子为例:
“半知菌亦称不完全菌类。半知菌是真菌门的一类。半知菌的菌丝多为多细胞,半知菌有多种形状的无性孢子。大多数半知菌是子囊菌的不完全期,某些不孕菌丝和极少数半知菌是担子菌的不完全期。半知菌是一个人为的分类,并未表示自然的亲缘系统关系。半知菌种类繁多。”
因为是为了测试效果,这句话手动添加了省略的主语。
将解释按句号分割成多句话,下面是前两句的句法分析的结果:


可以看出有的长词被分开了,但是被分开后句法关系是有的,如 “状中结构”、“定中关系” 等,
“不完全菌类”中 ,“不” 修饰 “完全”,“完全” 修饰 “菌类” ;
“半知菌的菌丝” 中,中心词是 “菌丝”,通过 “的” 连接到一块;
可以根据这些句法依存关系将被分开的词合到一块,连接到一块后如下:


由于只将形容词、状语连接到了中心词上,所以形容词和状语的部分直接置空就行。
根据主谓关系、核心关系、动宾关系、介宾关系(主要是宾语),可以抽取出三元组,规则是先找到句子主语,再找到宾语,通过宾语找到谓语,将主谓宾形成三元组,如上面的第一句话;
如果有与三元组中并列关系的词,就用并列的词替换掉三元组中的词形成新的三元组,如 “小明喜欢篮球、足球” ,足球与篮球是并列关系,就可以生成[小明,喜欢,篮球]、[小明,喜欢,足球]。
部分结果如下:
[['半知菌', '亦称', '不完全菌类']]
[['半知菌', '是', '一类']]
[['半知菌', '多为', '多细胞'], ['半知菌', '有', '多种形状'], ['半知菌', '无性孢子', '多细胞']]
[['半知菌', '是', '人为的分类'], ['半知菌', '并未表示', '亲缘系统关系'], ['半知菌', '并未表示', '人为的分类']]
['半知菌', '并未表示', '人为的分类']这个三元组是因为 “并未表示” 与 “是” 是并列关系。
可以看出,句法简单的句子还行,句法复杂、有多个主语、有复杂的并列关系 的时候结果不尽人意。
根据关键字的规则需要分析某种关系在句子中是怎么表达的,这里没有做尝试。
from pyhanlp import * ''' ID FORM LEMMA CPOSTAG POSTAG FEATS HEAD DEPREL PHEAD PDEPREL ——————————————————————————— 只用到前8列,其含义分别为: 1 ID 当前词在句子中的序号,1开始. 2 FORM 当前词语或标点 3 LEMMA 当前词语(或标点)的原型或词干,在中文中,此列与FORM相同 4 CPOSTAG 当前词语的词性(粗粒度) 5 POSTAG 当前词语的词性(细粒度) //6 FEATS 句法特征,在本次评测中,此列未被使用,全部以下划线代替。 7 HEAD 当前词语的中心词 8 DEPREL 当前词语与中心词的依存关系 ''' #CustomDictionary = JClass("com.hankcs.hanlp.dictionary.CustomDictionary") #CustomDictionary.add("酶活力单位") # 动态增加 s ='半知菌亦称不完全菌类。半知菌是真菌门的一类。半知菌的菌丝多为多细胞,半知菌有多种形状的无性孢子。大多数半知菌是子囊菌的不完全期,某些不孕菌丝和极少数半知菌是担子菌的不完全期。半知菌是一个人为的分类,并未表示自然的亲缘系统关系。半知菌种类繁多。' s_list = s.split('。') #keywordList = HanLP.extractKeyword(s, 10) #sentenceList = HanLP.extractSummary(s, 3) #print(sentenceList) #print(keywordList) # 将Hanlp句法分析结果转为dict类型 def word2dic(wordarray): word_dict = { 'ID' : wordarray.ID, 'LEMMA' : wordarray.LEMMA, 'CPOSTAG' : wordarray.CPOSTAG, 'POSTAG' : wordarray.POSTAG, 'HEAD' : wordarray.HEAD.ID, 'DEPREL' : wordarray.DEPREL } return word_dict def extract(s): parse = HanLP.parseDependency(s) print(parse) wordarray = parse.getWordArray() con = [] for i in wordarray: con.append(word2dic(i)) #print(con) # 将原应是一个词的多个词拼接在一起 for t,dic in enumerate(con): if dic['DEPREL'] == '定中关系' and dic['HEAD'] == t+2: con[t+1]['LEMMA'] = dic['LEMMA']+con[t+1]['LEMMA'] dic['LEMMA'] = '' if dic['DEPREL'] == '状中结构' and dic['HEAD'] == t + 2: con[t + 1]['LEMMA'] = dic['LEMMA'] + con[t + 1]['LEMMA'] dic['LEMMA'] = '' if dic['DEPREL'] == '右附加关系' and con[t-1]['DEPREL'] == '定中关系' and con[t-1]['HEAD'] == t+2: con[t + 1]['LEMMA'] = con[t-1]['LEMMA']+dic['LEMMA']+con[t + 1]['LEMMA'] dic['LEMMA'] = '' con[t - 1]['LEMMA']='' if dic['DEPREL'] == '动补结构': con[t - 1]['LEMMA'] = con[t - 1]['LEMMA'] + dic['LEMMA'] dic['LEMMA'] = '' zhuyu = '' result = [] for i in con: print(i) # if i['DEPREL']=='主谓关系' or i['DEPREL']=='核心关系' : # r_2.append(i['LEMMA']) # if i['DEPREL']=='动宾关系': # result.append(r_2+[i['LEMMA']]) if i['DEPREL'] == '主谓关系': zhuyu = i['LEMMA'] # 通过宾语找谓语,与主语形成三元组 for i in con: if i['DEPREL']=='动宾关系': result.append([zhuyu,con[i['HEAD']-1]['LEMMA'],i['LEMMA']]) if i['DEPREL']=='介宾关系': # 下面三元组第二个比较复杂,就是通过宾语的介词 找到动词在哪,如:分布在中国,中国是‘在’的介宾,通过在找到分布 result.append([zhuyu, con[con[i['HEAD'] - 1]['HEAD']-1] ['LEMMA'], i['LEMMA']]) # 将并列词添加相同的关系 for i in con: if i['DEPREL']=='并列关系': preword = con[i['HEAD']-1]['LEMMA'] # 与哪个词并列 # 找出并列的哪个词有没有已有的关系三元组 pre_guanxi=[] for j in result: if preword in j: pre_guanxi = j # 已有关系的三元组 break if pre_guanxi: new_guanxi = [c.replace(preword, i['LEMMA']) for c in pre_guanxi] result.append(new_guanxi) else: pass print(result) for i in s_list: extract(i) 根据句法抽取关系代码
通过和word2vec和TF-IDF寻找相似性高的词语
两个相似的词语在解释上会有相似的地方,两词前后的词也会有相同的地方。两词的相似性越高,就会有一些联系,可以用来生成候选关系实体对,代码使用的是gensim工具包中的训练方法。
word2vec是是谷歌提出基于上下文语境来获取词向量表示词语的方法,它可以较好地表达不同词之间的相似和类比关系,word2vec原理就不介绍了(估计我也介绍不好),可以通过两个词向量的余弦值表示两个两个词的相似度,就像下图,余弦越小向量就越相近,这只是二维的向量,多维向量与之相同。

1 from gensim.models import word2vec 2 sentences=word2vec.Text8Corpus('辞典分词结果.txt') 3 model=word2vec.Word2Vec(sentences, min_count=1,size=100) 4 y2=model.similarity(u"粮食", u"小麦") #两个词语的相关性 5 print(y2) 6 word = '玉米' 7 print(model[word]) # 某个词的向量表示 8 9 print('与 '+word+' 相关的:') 10 for i in model.most_similar(word): 11 print(i[0],i[1])
下面是比较结果:



因为此方法是基于统计的,对高频词语结果还行,对一些不常见的词效果就明显不好了。
TF-IDF(term frequency–inverse document frequency 词频-逆文档频率)称为 “逆文档频率”,也是一个将文本转化为数字的常用方法,因为只有将文本转为数字才能通过程序计算嘛。它与词语顺序无关,只与词语频率有关。通常出现频率越高的词语越重要,但是像 “的”、“只是” 这些无关紧要的词出现的频率往往很高,TF-IDF的目的就是解决这个问题,具体公式实现网上很多,可自行了解,简单来说一个词在总文本中出现的频率不高而在本句话中出现的频率很高,那这个词在本句话中TF-IDF值就高,如果一个词在总文本中出现的频率很高,在某句中频率也高,它在这句中TF-IDF值也不一定高。 经常用来提取句子或文章的关键词。但是TF-IDF的词频是针对词的,如何比较相似性呢?对于粮食大辞典,比较两个词相似度就可以转为比较两词的解释的句子的相似度,将解释的句子用每个词的TF-IDF总体表示,然后进行余弦比较。详细原理见:https://blog.csdn.net/lom9357bye/article/details/73136117
# coding=gbk from gensim import corpora, models, similarities #文档 f = open('辞典分词结果.txt','r',encoding='utf-8') documents = f.readlines() f.close() ## 分词、过滤停用词操作,得到每个文档的词: (这一步省略操作) texts = [s.split(' ') for s in documents] # 创建辞典(单词与编号之间的映射) dictionary = corpora.Dictionary(texts) #print(dictionary) #print(dictionary.token2id) # 将一篇分词后的文档通过上面的字典转换为向量 new_s = '吸式风选器 @ aspirator , air - suction separator @ 亦 称 吸风分离器 。 负压 状态 下 , 用 气流 将 物料 进行 分选 的 设备 。 根据 物料 之间 悬浮 速度 和 飞行 系数 的 差异 , 利用 气流 对 物料 进行 除杂 或 分级 。 主要 工作 机构 是 垂直 风选 槽 和 轻杂 沉降室 。 常见 风选 设备 之一 , 用途 较广 。 ' new_doc = new_s.split() new_vec = dictionary.doc2bow(new_doc) print("例句的词语TF-IDF表示:") print(new_vec) #[(0, 1), (1, 1)] (0,1)表示字典中的第一个词出现的一次,(1,1)是字典中第二个词出现了一次,interaction不在字典中所以没有 #建立语料库,将每一篇文档通过dictionary转换为向量 corpus = [dictionary.doc2bow(text) for text in texts] #print(corpus) # 初始化tfidf模型,是将词的个数转换为该词在文档中的tfidf值 tfidf = models.TfidfModel(corpus) test_doc_bow = [(0, 1), (1, 1)] #print(tfidf) print(tfidf[test_doc_bow]) #将整个语料库转为tfidf表示方法 corpus_tfidf = tfidf[corpus] # for doc in corpus_tfidf: # print(doc) #创建索引 index = similarities.MatrixSimilarity(corpus_tfidf) #相似度计算 new_vec_tfidf=tfidf[new_vec]#将要比较文档转换为tfidf表示方法 #print(new_vec_tfidf) #[(0, 0.7071067811865476), (2, 0.7071067811865476)] print('---------------------') #计算要比较的文档与语料库中每篇文档的相似度 print(type(index)) sims = index[new_vec_tfidf] #index[xxx] 调用内置方法 __getitem__() 来计算ml_lsi print(sims) # 相似度列表 sort_sims = sorted(enumerate(sims), key=lambda item: -item[1]) # 将相似度列表排序 print(sort_sims[0:10]) #相似度前十个 print("与“"+new_s.split('@')[0]+"”相似度高的词:") for i in sort_sims[0:10]: print(texts[i[0]][0]) #相似度第一的是哪个文档,i[0]是句子索引,texts[i[0]]是这句话,texts[i[0]][0]是这句话的第一个词 TF-IDF+余弦比较相似度
结果如下:



因为是比较句子的余弦,对不常见词语的效果比word2vec好。
在词条的解释中抽取候选实体对
每个词语的解释都是描述这个词语的一些特性,在解释中出现的实体一般都与这个词条有关系,实体就一粮食大辞典目录中所有词语作为集合,当然这样做会忽略掉一些不是辞典词条中的一些词,如 “丛林”、“全国大部分地区”,这些词不会作为词条出现,但也是关键词。
如:“虫卵@egg@成熟的雌性 生殖细胞。昆虫生活周期中的第一个发育阶段。一般呈球形或卵圆形,由卵壳、卵黄膜、原生质、卵黄、卵细胞核等部分构成。受精卵经一系列变化形成胚胎,再发育为幼虫孵化出来。卵对杀虫剂的抵抗能力高于幼虫和成虫等活动虫态。”
提取害虫部分词语解释中作为词条出现的实体:
f_content = open('害虫内容.txt','r',encoding='utf-8') # 害虫辞典解释的文本 f_in_content = open('害虫内容出现的词语.txt','w',encoding='utf-8') # 保存结果的文本 f_mulu = open('目录总和.txt','r',encoding='utf-8') # 目录词条集合 content = f_content.readlines() dic_haichong = {} mulu_all = f_mulu.readlines() for i in content: l = i.split("@") #print(i) has = [] for j in mulu_all: j=j.strip().strip() # 删除词语尾部换行 if j in i and j != l[0]: # 判断是否出现 has.append(j) f_in_content.writelines(l[0]+'@'+' '.join(has)+'\n') f_content.close() f_in_content.close() f_mulu.close() 词条解释中选取候选实体对代码
结果如下:

“@” 后面的词与 “@” 前面的词组成候选实体对,结果还算可以,毕竟在解释中出现的词语都是与词条有所相关的。
另外还可以用分词工具选取解释中关键词,然后将其与词条一块作为候选实体对。
提取害虫词条解释中的关键词:
from pyhanlp import * f_content = open('害虫内容.txt','r',encoding='utf-8') # 害虫辞典解释的文本 f_in_content = open('害虫解释中的关键词.txt','w',encoding='utf-8') # 保存结果的文本 f_mulu = open('目录总和.txt','r',encoding='utf-8') # 目录词条集合 content = f_content.readlines() dic_haichong = {} mulu_all = f_mulu.readlines() for i in content: l = i.split("@") keywordList = HanLP.extractKeyword(l[1], 10) #print(i) f_in_content.writelines(l[0]+'@'+' '.join(keywordList)+'\n') f_content.close() f_in_content.close() f_mulu.close()
结果如下,选取了 10个关键词,关键程度是依次排列的:

这结果就一般了,它依赖于分词,如果分词结果不好所生成的结果也不好,可以添加自定义词典试试(我没有去试,因为尝试添加自定义词典后对分词并没用,可能hanlp对python支持的没有java全面,然而不会java)。
为上面生成的候选实体对选择特征,根据特征将关系分类
因为没有标注数据,只能根据特征对实体对进行分类操作,“属于...”、“分布于...”、这些关系在句法上都有明显的区别,所以只要选择好特征就能通过SVM、K-means等算法进行分类。
这个方法的重点在特征的选择,选择能表征这些关系的特征就能实现分类。因为是对关系分类,所以 “在”、“以”、“一种” 等这些词不能舍弃(网上很多分类就将这些词舍弃掉了),而一些实体名词,如 “小麦”、“装置” 等这些词对关系特征是没有贡献的,可以过滤掉,可通过过滤辞典词条中的实体名词进行过滤。
特征选择如下:
1. 两个实体词距中心谓词的距离
2. 两个词左右的词语的和它们的词性
3. 两词与中心谓词是否有句法关系及关系类型
4. 两词的词性,类型
5. 句中是否有预定义词典中的词(一些有明显关系的词,如 “亦称”、“由...组成”、“分布”),这个词谓语两实体词的中间还是左右侧
6. 两词中间、左右是否有介词,以及介词的分布
这些特征加上权重效果会更好,如第5条和第6可给予较高的权重。
暂时想到上面这几种特征,以后想到可以再补充。
需要将这些特征转化为数字特征,才能进行运算,但是还没有找到如何转化的有效方法,后面的步骤以后有时间再具体尝试实现。
手动标注数据进行监督学习分类关系
这种方法应该会比无监督分类更准确,因为前面已经生成了候选实体对,定义好具体关系类型后手动分类也不麻烦,然后通过标注好的数据进行关系分类。
此方法以后有时间再尝试。
这些过程中有一些可以优化的地方,如候选实体对的选择,可以添加一些词性判断得到更准确的实体对,无关系的噪声实体对少的话对后面的分类也会提高准确率。