Genre Separation Network with Adversarial Training for Cross-genre
Relation Extraction
Abstract
论文的动机来源与主流关系抽取模型在不同的领域甚至是不同的数据集上性能的参差不齐。论文中提出了一种领域分离网络,其含有基于本领域独立的编码器,和基于领域共享的编码器。该网络可以抽取特定类型和类型未知的两种类型特征。
Approach
Overview
这篇轮文的主要任务如下:
![]()
si代表一个由若干单词组成的句子,ei1和ei2代表句子中的两个实体,ri代表这两个实体在句子中表达的某种关系。我们对源类型数据S建立模型,最后要将此模型应用到其他不同类型的领域当中去。
Genre Separation Network (GSN)

如图一所示,我们的目标就是去区分出不可知特征(如图中红色矩形),具体特殊特征(如图中蓝色和绿色)。我们用一个源类型私有CNN去抽取具体明确的私有特征fsp,用一个共享CNN去抽取类型未知的特征fsc。相同的我们同样的从其他目标类型领域中去抽取ftp和ftc。
对于一个源类型句子![]() ,s中的每个单词wi可以被向量化的表示为 vi=
,s中的每个单词wi可以被向量化的表示为 vi=![]() 。
。
这里vi是一个预训练好的词向量,pi代表句子中两个实体的位置embedding,ti代表句子中两个实体的类型embedding,ci是分类embedding,ηi代表是否word对于实体e1 e2 有最短路径(具体可以参阅http://aclweb.org/anthology/D17-1274)。
为了区分出这四种不同类型的特征,我们使用loss(squared Frobenius norm)来区分。
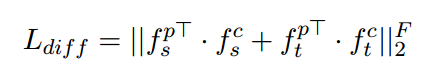
为了将各种类型的类型不可知特征限制为共享特征空间,我们使用对抗网络来训练。
论文中将源领域和目标领域的genre-agnostic features送到GRL(http://jmlr.org/papers/volume17/15-239/15-239.pdf)层中,同过GRL层的处理模型将不能区分出输入特征是来自于源领域还是目标领域。
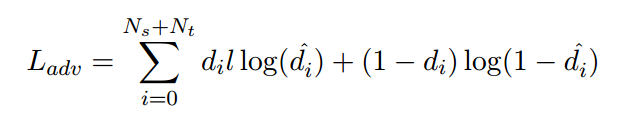
这里di取值{0,1}用以区分样例是来自于源领域还是目标领域,Ns和Nt分布代表源领域和目标领域中的样例数目,di^代表样例来自于源领域的可能性(通过一个线性分类器得出的类型分类结果)。
Genre Reconstruction
对于每个类型的enre-specific feature和genre-agnostic feature,我们用fs来代表两种特征的加和。我们吧fs当做输入送进一个无池化层的DCNN(https://papers.nips.cc/paper/5485-deep-convolutional-neural-network-for-image-deconvolution.pdf)中,分别用![]() 和
和![]() 来代表DCNN的输入和输出。重构loss如下所示
来代表DCNN的输入和输出。重构loss如下所示

Cross Genre Relation Extraction

将fs送入一个全连接层来获得一个稠密向量,然后应用一个线性分类器来或得一个关系类型:

最后我们将loss函数线性结合用于多关系类型的关系分类:

Experiments
具体实验结果详见论文(http://nlp.cs.rpi.edu/paper/relation2018.pdf)