什么是pyspider
一个国人编写的强大的网络爬虫系统并带有强大的WebUI。采用Python语言编写,分布式架构,支持多种数据库后端,强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器
爬取目标

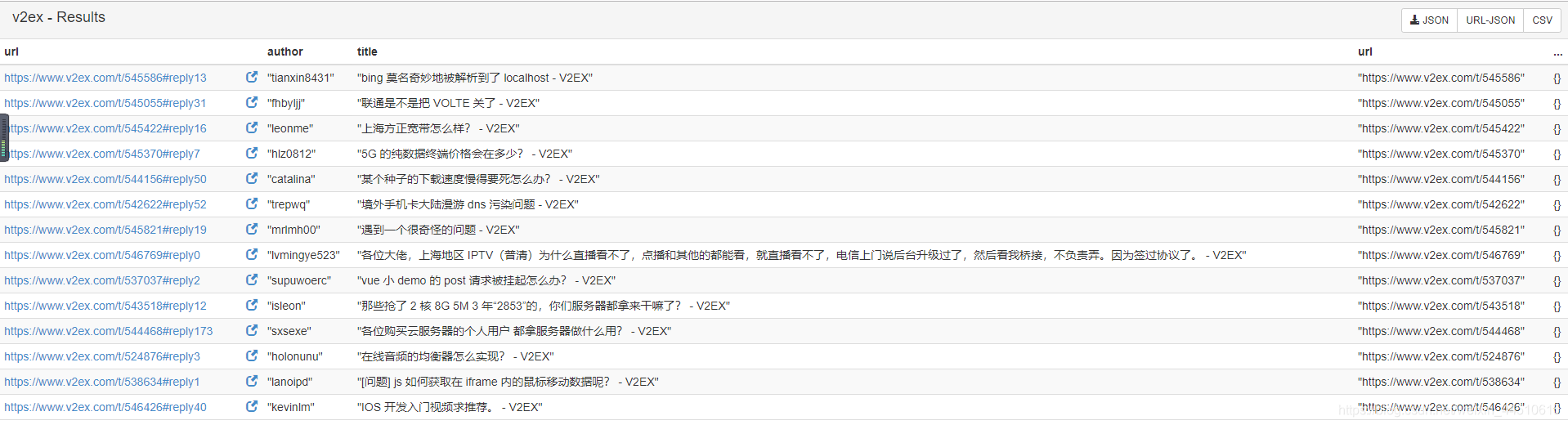
爬取每篇帖子的url,author,和title

爬取流程
- 在命令行运行
pyspider,并能在网页端打开
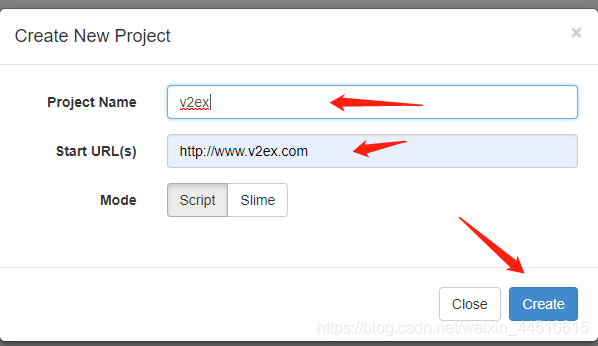
2. 新建项目,命名为v2ex ,url为http://www.v2ex.com
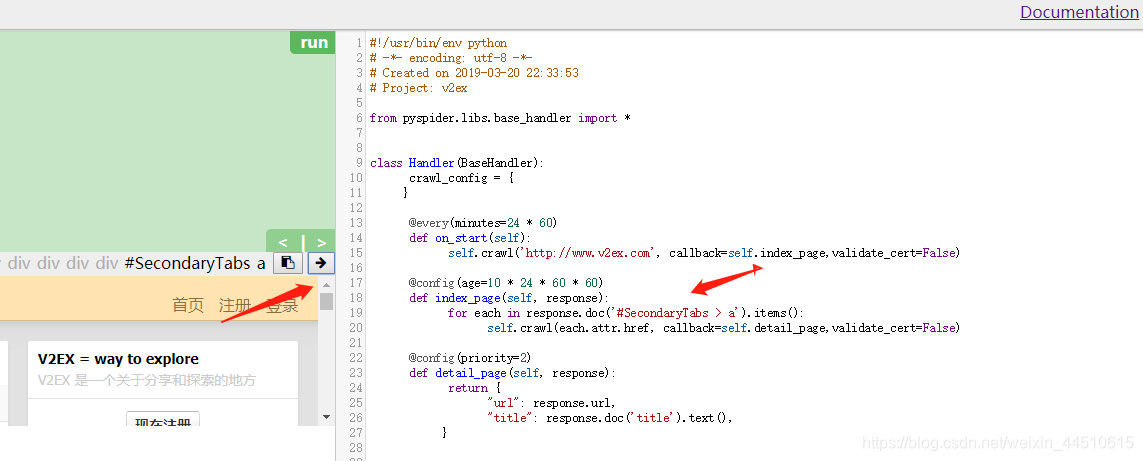
- 编写代码
-
首先在回调函数中加上
validate_cert=False用来请求到https,保存并运行,再follow,

-
打开web界面和css选择器
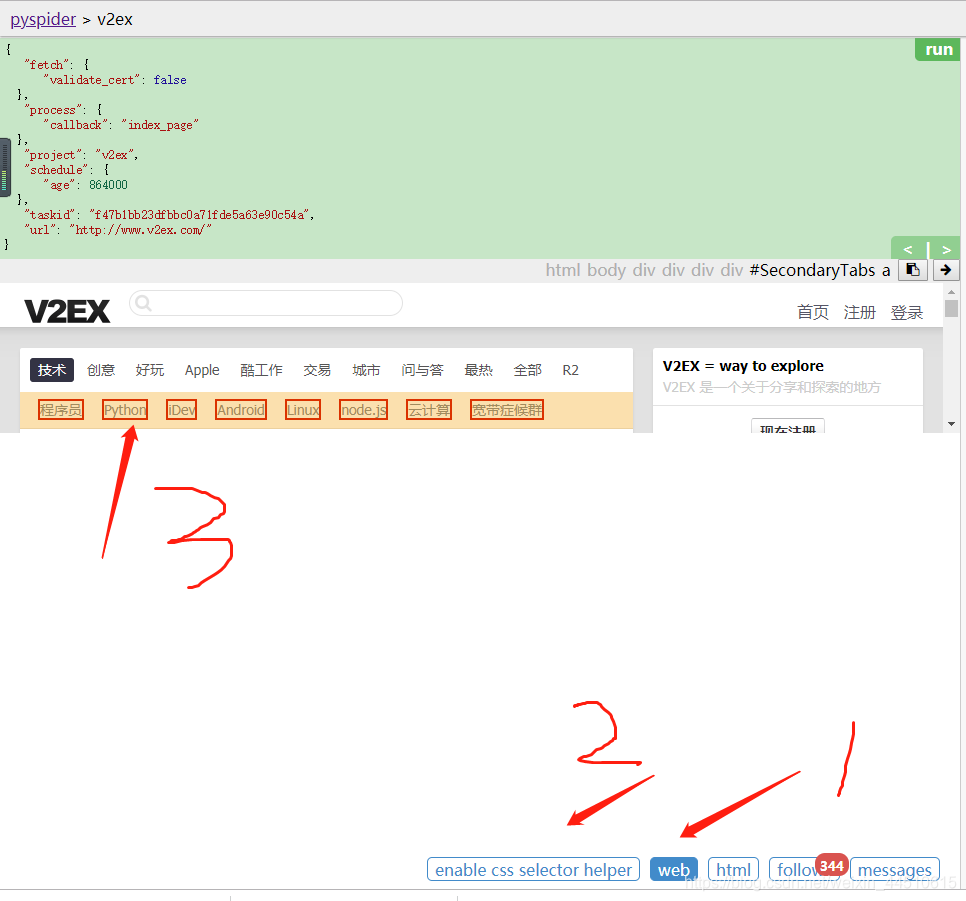
-
点击右箭头将css解析内容复制到对用地方,并从重新运行,相当于跳转了页面
!
-
同样的方法跳转页面,来到目标页面,因为要多跳转一个页面,使用要新建一个
detail_page的方法,可以复制上面的代码,只修改css解析内容

- 现在用同样的方法编写发布者的代码,得到对应得到css解析内容。

运行代码
- 保存回到原始界面,将状态改为
debug,并点击运行

我们可以从cmd窗口中看到爬取的内容

- 爬取成功
完整代码
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://www.v2ex.com', callback=self.index_page,validate_cert=False)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('#SecondaryTabs > a').items():
self.crawl(each.attr.href, callback=self.detail_page,validate_cert=False)
@config(priority=2)
def detail_page(self, response):
for each in response.doc('.item_title > a').items():
self.crawl(each.attr.href, callback=self.parse_item,validate_cert=False)
@config(priority=2)
def parse_item(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
"author": response.doc('.header > .gray > a').text()
}