版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/weixin_39777626/article/details/82020019
本文主要知识点:
Pyspider框架
静态页面+动态页面 抓取
pymongo存储
1.终端输入
pyspider all2.浏览器打开http://localhost:5000/,得到以下界面
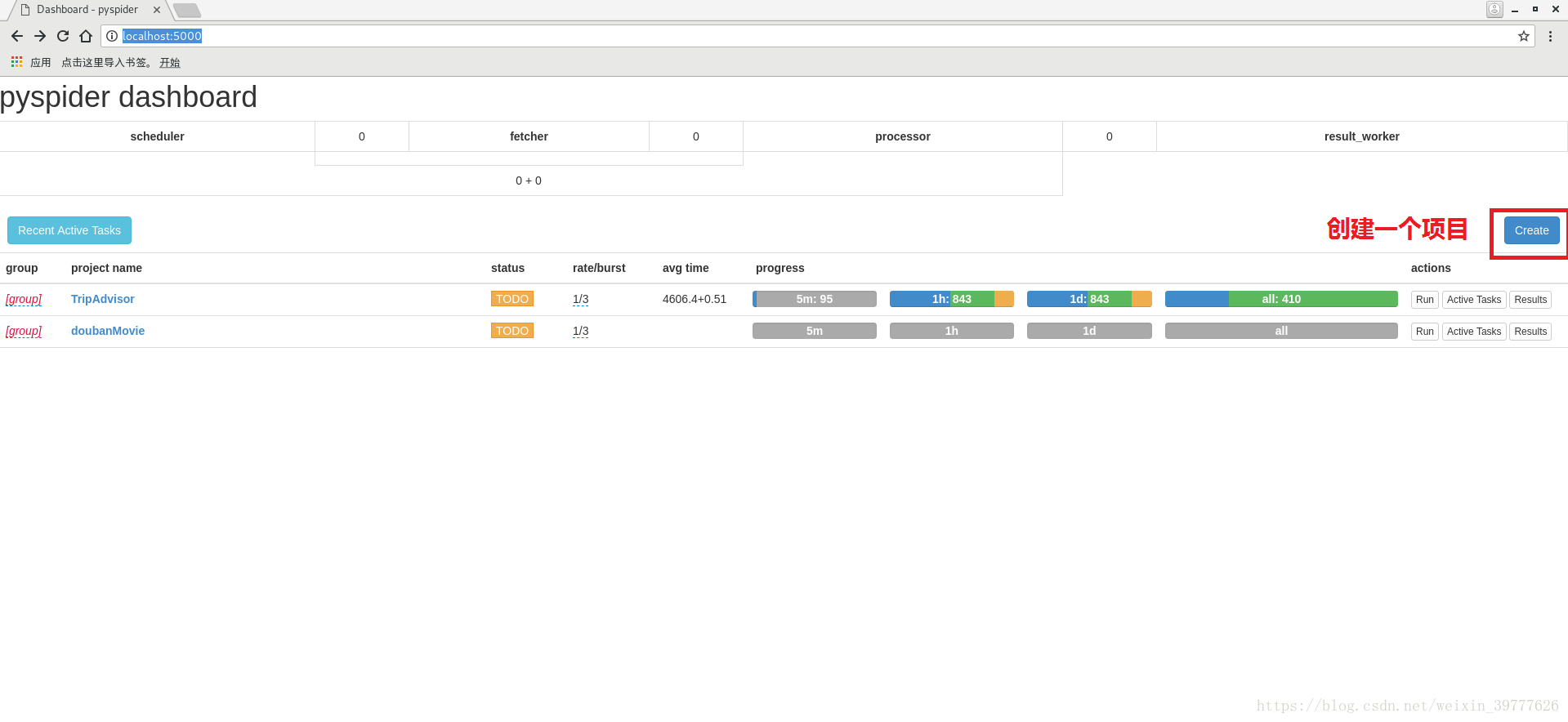
3.点击create,创建一个爬虫项目
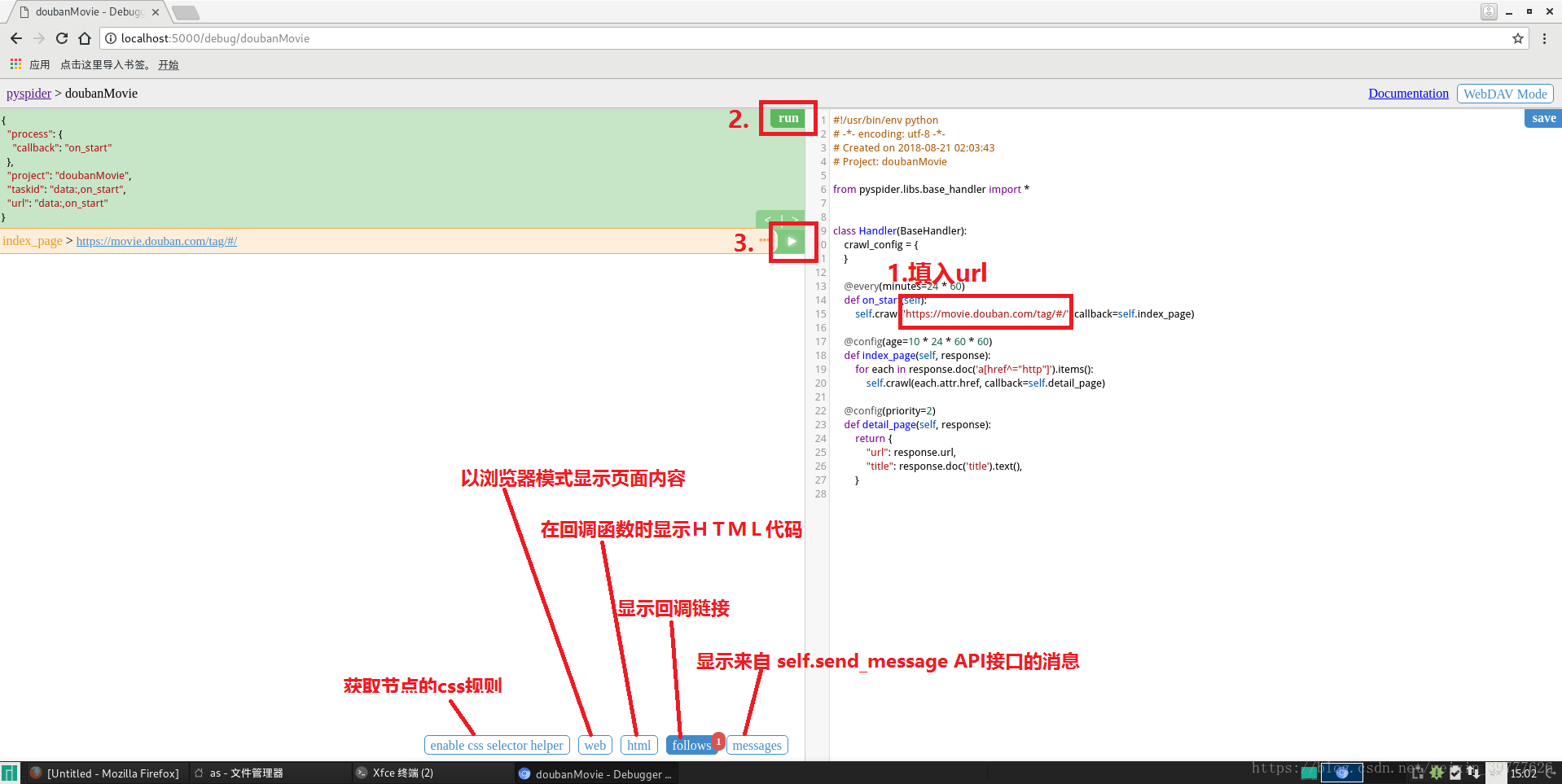
4.打开项目,界面如下所示,右侧为脚本区(用来写爬虫代码),左侧为页面预览区
左上方:
run:执行代码区请求,并返回结果或异常
左下方:
1.enable css selector helper:配合web进行使用,方便获取页面元素的CSS表达式(a.点击web打开页面;b.点击enable css selector helper;c.选中页面元素;d.此时左侧中间会有个 “->”,点击 “->”就会在代码区自动插入css表达式)
2.web:页面实时预览图
3.html:页面HTML代码
4.follows:回调的新请求
5.messages:爬取过程中输出的信息
填入初始链接 >> run >>三角号
代码
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2018-08-23 17:04:35
# Project: TripAdvisor
from pyspider.libs.base_handler import *
from pymongo import MongoClient
class MongoStore(object):
def __init__(self):
client=MongoClient()
db=client.TripAdvisor
self.London=db.London
def insert(self,result):
if result:
self.London.insert(result)
class Handler(BaseHandler):
crawl_config = {
}
mongo=MongoStore()
headers = {
'User-Agent': r'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.90 Safari/537.36 2345Explorer/9.3.2.17331',
'Referer': 'https://www.tripadvisor.cn',
'Connection': 'keep-alive'
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('https://www.tripadvisor.cn/Attractions-g186338-Activities-c47-London_England.html#FILTERED_LIST', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for cell in response.doc('* > .attraction_clarity_cell').items():
self.crawl(cell('.listing_title')('a').attr('href'),fetch_type='js',js_script='''
function(){
window.scrollTo(0,document.body.scrollHeight);
}
''',callback=self.detail_page)
self.crawl(response.doc('.pagination > .taLnk').attr('href'),callback=self.next_page)
def index_page(self, response):
for cell in response.doc('* > .attraction_clarity_cell').items():
self.crawl(cell('.listing_title')('a').attr('href'),fetch_type='js',js_script='''
function(){
window.scrollTo(0,document.body.scrollHeight);
}
''',callback=self.detail_page)
self.crawl(response.doc('.next').attr('href'),callback=self.index_page)
@config(priority=2)
def detail_page(self, response):
Imgs=[]
for Img in response.doc('.onDemandImg'):
Imgs.append(Img.get('data-src'))
self.crawl(response.doc('.improveContainer a').attr('href'),fetch_type='js',js_script='''
function(){
window.scrollTo(0,document.body.scrollHeight);
}
''',callback=self.complete_information,headers=self.headers,timeout=60)
return {
'title':response.doc('.heading_title').text(),
'点评':response.doc('div > .more').text(),
'标签':response.doc('.attraction_details > div > a').text(),
'地点':response.doc('.location > .address').text(),
'电话':response.doc('.headerBL .phone > span').text(),
'图片':Imgs,
#"url": response.doc('.headerBL .website > span').text(),
#"email": response.doc('.email > span').text()
}
def complete_information(self,response):
pass
def on_result(self,result):
self.mongo.insert(result)
super(Handler,self).on_result(result)