BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库,它的使用方式相对于正则来说更加的简单方便,常常能够节省我们大量的时间。
BeautifulSoup的使用

节点对象
- Tag
tag对象可以说是BeautifulSoup中最为重要的对象,通过BeautifulSoup来提取数据基本都围绕着这个对象来进行操作。
每一个tag对象都有name属性,为标签的名字。
- NavigableString
NavigableString的意思是可以遍历的字符串,一般被标签包裹在其中的的文本就是NavigableString格式。
在这里插入图片描述
- BeautifulSoup
BeautifulSoup 对象表示的是一个文档的全部内容.大部分时候,可以把它当作 Tag 对象,是一个特殊的 Tag
- Comment
Comment指的是在网页中的注释以及特殊字符串
如何使用
- 获取标签
title = soup.head.title(获取head标签下面的第一个title标签)
- 获取属性
title = soup.p['title']
- 获取文本内容
# string方法只能获取p标签的内容
string = suop.p.string
#通过get_text()方法我们可以获取p下所有的文本内容。
text = soup.p.get_text()
-
获取节点(tpye:generator)
contents和children
通过
contents可以获取某个节点所有的子节点,包括里面的NavigableString对象。获取的子节点是列表格式。而通过children同样的是获取某个节点的所有子节点,但是返回的是一个迭代器,这种方式会比列表格式更加的节省内存descendants
contents和children获取的是某个节点的直接子节点,而无法获得子孙节点。通过descendants可以获得所有子孙节点,返回的结果跟children一样,需要迭代或者转类型使用。扫描二维码关注公众号,回复: 5639884 查看本文章
- 父节点
parent和parents
有时我们也需要去获取某个节点的父节点,也就是包裹着当前节点的节点而使用
parents则可以获得当前节点递归到顶层的所有父辈元素。- 兄弟节点
兄弟节点指的就是父节点相同的节点。
next_sibling和previous_sibling
next_siblings和previous_siblings -
查找
soup.find('a')
soup.find('a',title='')
soup.find('a',id='')
soup.find('a',class='')
soup.find_all('a')
soup.find_all(['a','p'])
soup.find_all('a',limit=2)
soup.find_all(attrs={'class': 'sister'})
XPath
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。
相比于BeautifulSoup,Xpath在提取数据时会更有效率。
用法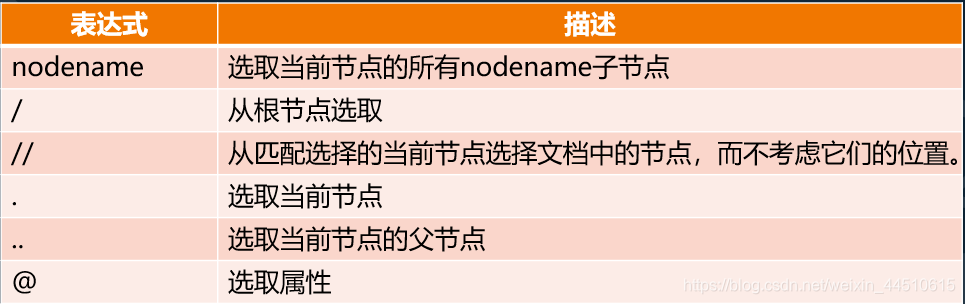
使用
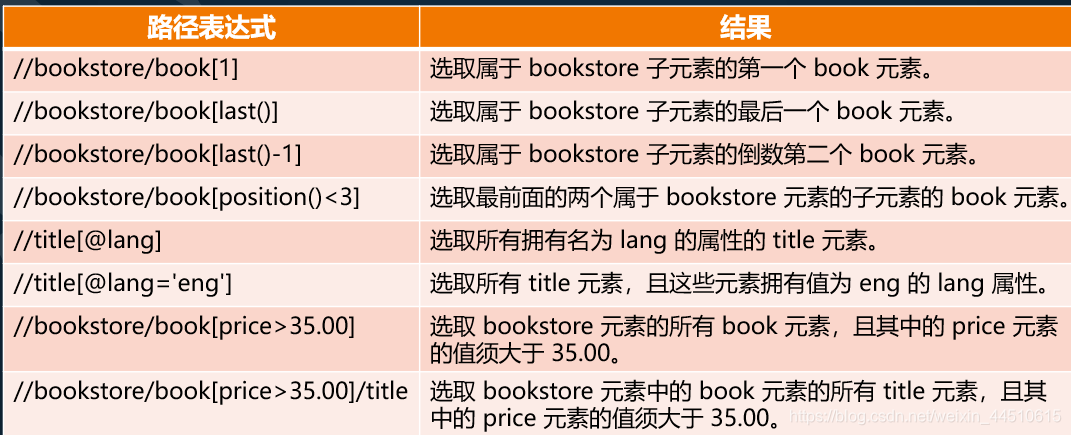


用text()获取某个节点下的文本
result=html.xpath('//li[@class="item-0"]/text()')