一些说明
我为什么要写这篇文章?
其实这篇文章并不是为了比较出结论,因为结论是显而易见的,Xpath 必然 是要比 BeautifulSoup 在时间和空间上都要性能更好一些。其中理由有很多,其中一个很明显的是 BeautifulSoup 在构建一个对象的时候需要传入一个参数以指定解析器,而在它支持的众多的解析器中,lxml 是性能最佳的,那么 BeautifulSoup 对象的各种方法可以理解为是对 lxml 的封装,换句话说,BeautifulSoup 本质上并没有创造出自己的解析方式,而是建立在各种解析器的基础上。考虑到其他一些内部耗时因素,BeautifulSoup 注定会比 lxml 甚至是任何一个构建对象时使用的解析器要慢,要更耗费空间。只有付出这样子的代价才能够换来它的简洁、优美与用户友好性。
那么,本文其实是通过一个爬虫例子来简单的验证一下这个结论,以及对它们之间的差距有一个数量上的认识。
测试例子
# test.py
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup, SoupStrainer
import traceback
import json
from lxml import etree
import re
import time
def getHtmlText(url):
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
if r.encoding == 'ISO-8859-1':
r.encoding = r.apparent_encoding
return r.text
except:
traceback.print_exc()
def parseWithBeautifulSoup(html_text):
soup = BeautifulSoup(html_text, 'html.parser') # 后改为 'lxml'
content = []
for mulu in soup.find_all(class_='mulu'):
h2 = mulu.find('h2')
if h2 != None:
h2_title = h2.string # 获取标题
lst = []
for a in mulu.select('div.box a'):
href = a.get('href')
box_title = a.get('title')
pattern = re.compile(r'\s*\[(.*)\]\s+(.*)') # (re) 匹配括号内的表达式,也表示一个组
match = pattern.search(box_title)
if match != None:
date = match.group(1)
real_title = match.group(2)
lst.append({'href':href,'title':real_title,'date':date})
content.append({'title':h2_title,'content':lst})
with open('dmbj_bs.json', 'w') as fp:
json.dump(content, fp=fp, indent=4)
def parseWithXpath(html_text):
html = etree.HTML(html_text)
div_mulus = html.xpath('.//*[@class="mulu"]') # 先找到所有的 div class=mulu 标记
content = []
for div_mulu in div_mulus:
# 找到所有的 div_h2 标记
div_h2 = div_mulu.xpath('./div[@class="mulu-title"]/center/h2/text()')
if len(div_h2) > 0:
h2_title = div_h2[0]
a_s = div_mulu.xpath('./div[@class="box"]/ul/li/a')
lst = []
for a in a_s:
# 找到 href 属性
href = a.xpath('./@href')[0]
# 找到 title 属性
box_title = a.xpath('./@title')[0]
pattern = re.compile(r'\s*\[(.*)\]\s+(.*)') # (re) 匹配括号内的表达式,也表示一个组
match = pattern.search(box_title)
if match != None:
date = match.group(1)
real_title = match.group(2)
lst.append({'href':href,'title':real_title,'date':date})
content.append({'title':h2_title,'content':lst})
with open('dmbj_xp.json', 'w') as fp:
json.dump(content, fp=fp, indent=4)
def main():
html_text = getHtmlText('http://www.seputu.com')
print(len(html_text))
start = time.clock()
parseWithBeautifulSoup(html_text)
print('BSoup cost:', time.clock()-start)
start = time.clock()
parseWithXpath(html_text)
print('Xpath cost:', time.clock()-start)
if __name__ == '__main__':
user_agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.117 Safari/537.36'
headers={'User-Agent': user_agent}
main()
- 运行截图
html.parser

lxml
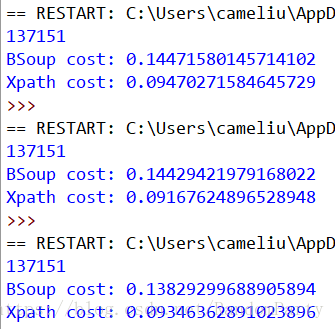
结果分析
可以看到,当我们使用 html.parser 作为解析器时,BeautifulSoup 解析的耗时平均是 Xpath 的 1.8 倍+;当我们使用 lxml 作为解析器时,BeautifulSoup 解析的耗时虽有减少,但平均仍是 Xpath 的 1.5 倍+。
最后
BeautifulSoup 这碗美味汤确实是美味可口,但是一碗好汤煲制时间和用料上面都更加花费,这无可厚非。Xpath 相对来说可能语义性没有前者强,但总体也是 user-friendly,也很好用,功能十分强大,最重要的是它的爸爸 lxml 使用 C 编写的,速度自然就不必说了,如果在很追求效率和资源节约的情况下,熟练运用 Xpath 会使你感到无尽的愉悦。