解析库的作用就是不需要写又臭又长的正则表达式就可以轻松匹配到页面的各个节点....
| 表达式 | 描述 |
| nodename | 选取该节点的所有子节点 |
| / | 从当前子节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
from lxml import etree
html = etree.parse('test.html', etree.HTMLParser())
result=etree.tostring(html)
print(result.decode('utf-8'))
def xpa(str):
result=html.xpath(str)
print(result)
return result
if __name__ == '__main__':
xpa('//*')
xpa('//li')
xpa('//li/@class')
xpa('//li[@class="item-0"]')
xpa('//li[@class="item-0"]/text()')
xpa('//li[@class="item-0"]/a/text()')
xpa('//ul')
xpa('//li/a')
xpa('//a[@href="link4.html"]')
xpa('//a/@href')匹配所有节点://*选取所有节点://li选取所有的li节点
匹配所有子节点://li/a所有li节点的a节点
匹配所有孙节点://li//a所有li节点下的孙节点为a的节点
匹配父节点://a[@id="reback"]/../@class 属性id=reback的a节点的父节点的class是??
或者使用parent::表示父节点
//a[@id="reback"]/parent::*/@class
匹配带属性的节点://li[@class="reback"]所有属性为reback的li节点
获取文本
//li[@class="reback"]/a/text() class为reback的li节点下的a节点处的文本
或者直接查找孙节点
//li[@class="reback"]//text() 效果同样
获取节点的属性://li/a/@href 获取节点的href属性
包含节点的属性://li[contains(@class, "li")]/a/text()
contains() 方法,第一个参数传入属性名称,第二个参数传入属性值,这样只要此属性包含所传入的属性值就可以完成匹配了
多属性匹配://li[contains(@class, "li") and @name="item"]/a/text()
按顺序选择:
//li[last()]/a/text() //li[1]/a/text()
//li[position()<3]/a/text() //li[last()-2]/a/text()
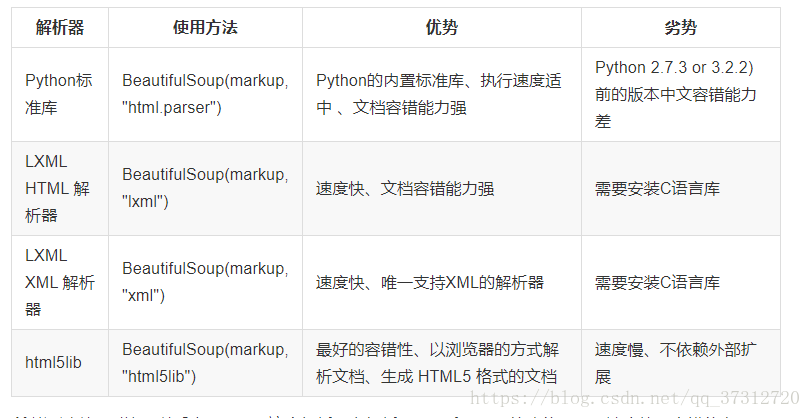
BeautifulSoup:官方解释
BeautifulSoup提供一些简单的、Python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。 BeautifulSoup 自动将输入文档转换为 Unicode 编码,输出文档转换为 utf-8 编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时你仅仅需要说明一下原始编码方式就可以了。 BeautifulSoup 已成为和 lxml、html6lib 一样出色的 Python 解释器,为用户灵活地提供不同的解析策略或强劲的速度。
BeautifulSoup在解析的时候实际上是依赖于解析器的,除了支持Python标准库,还支持上面的lxml还支持html5lib的解析器
基本使用
html中的选择器:即解析器的效果
from bs4 import BeautifulSoup
soup=BeautifulSoup('<p>Hello</p>','lxml')
print(soup.p.string)
就是将html文件给进去,然后指定解析器...
节点什么的有固定的套路(语法)...
soup.prettify()...将html固有的骨架补齐
soup.title..string...title是什么...(选到的都是第一个)\
获取名称:
soup.title.name
获取属性:
soup.p.attrs
获取属性值
soup.p.attrs['name'] 或者soup.p['name']
节点
children子节点 descendants子孙节点
parent父节点 parents父族节点
next_sibling previous_sibling next_siblings previous_siblings
方法选择器:
find() find_all()
soup.findall(name='li')返回的可能是一个或者多个对象..所有要做内层循环,取值的话要使用string
soup.find(attrs={'name'='reback'})
匹配文本中的字段:soup.find_all(text=re.compile('link'))
find_next_siblings() find_next_sibling()
find_previous_sibling() find_previous_siblings()
find_all_next() find_next()
find_all_previous find_previous()
CSS选择器
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.select('.panel .panel-heading'))
print(soup.select('ul li'))
print(soup.select('#list-2 .element'))
print(type(soup.select('ul')[0]))
嵌套选择:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
for ul in soup.select('ul'):
print(ul.select('li'))
获取属性:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
for ul in soup.select('ul'):
print(ul['id'])
print(ul.attrs['id'])
获取文本:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
for li in soup.select('li'):
print('Get Text:', li.get_text())
print('String:', li.string)pyQuery的基本用法:
url初始化:
from pyquery import PyQuery as pq
doc = pq(url='http://www.baidu.com')
print(doc('title'))
和下面的是等效的,都是url初始化
import requests
from pyquery import PyQuery as pq
doc = pq(requests.get('http://www.baidu.com').text)
print(doc('title'))同样可以将文件(html文件)初始化
from pyquery import PyQuery as pq
doc=pq(filename='test.html')
print(doc('li'))重点是它的CSS选择器***
print(doc('#id .class li'))
print(type(doc('#id .class li')))# PyQuery类型查找节点:
for item in doc('.list').find('li').items():
print(item)
doc('.list').find('li').children()#所有子孙节点
doc('.list').find('li').children('.active')#所有class=active的子孙节点
doc('.list').find('li').parent()#所有父节点
doc('.list').find('li').parent('.active')#所有class=active的父节点
doc('.list').find('li').parents()#所有的祖先节点
doc('.list').find('li').parents('.active')#所有的class=active的祖先节点
doc('.list').find('li').sibling()
doc('.list').find('li').siblings()
因为所有的查找返回的都不是item类型而是pyQuery类型的文件所以遍历的时候要进行类型转换
for item in doc('li').items():
print(item)获取属性:
print(a.attr('href'))
print(a.attr.href)获取文本:
print(a.text())
print(a.html())#获取html的文本添加属性或者删除属性:
a=doc('.active')
a.addClass('*')
a.removeClass('*')
改变节点内容:(用赋值)
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
li.attr('name', 'link')
print(li)
li.text('changed item')
print(li)
li.html('<span>changed item</span>')
print(li)删除节点:
html = '''
<div class="wrap">
Hello, World
<p>This is a paragraph.</p>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
wrap = doc('.wrap')
print(wrap.text())
wrap.find('p').remove()
print(wrap.text())
append()、empty()、prepend() 同样