本文为马士兵教育《Python网络爬虫进阶指南》课程笔记,部分内容由AI生成。课件:第一章,第二章,第三章,第四章,第五章,第六章,第七章,第九章,第十章。
一、爬虫开发基础
1.1浏览器工作原理
浏览器是我们在日常网络活动中经常使用的工具,它允许我们浏览网页、查找信息、与网站进行交互等。浏览器的工作原理涉及多个组件和过程,如下所示:
- 用户界面(User Interface)
这是浏览器的外观,包括地址栏、后退/前进按钮、书签、标签页等。用户界面提供了与浏览器交互的方式。 - 浏览器引擎(Browser Engine)
这是浏览器的核心部分,负责解释和执行用户界面和呈现引擎之间的命令。它处理用户输入,将其转化为请求,并与呈现引擎协调,以展示所需的内容。 - 呈现引擎(Rendering Engine)
这是浏览器的另一个核心部分,负责显示请求的内容。它将HTML和CSS解释成可视化的页面。不同的浏览器使用不同的呈现引擎,例如Chrome使用Blink引擎,Firefox使用Gecko引擎。 - 网络组件(Networking)
这部分负责网络通信,从互联网下载页面和资源。浏览器通过HTTP请求从服务器获取HTML、CSS、JavaScript、图片等文件。 - JavaScript解释器(JavaScript Interpreter)
如果页面中有JavaScript代码,浏览器会使用JavaScript解释器来解析和执行这些代码,实现交互性和动态效果。 - UI后端(UI Backend)
此组件绘制浏览器的用户界面元素,如文本框和按钮。它使用操作系统的用户界面方法来实现。 - 数据存储(Data Persistence)
浏览器需要存储各种数据,包括cookies、缓存和本地存储。这些数据允许网站“记住”用户,并在不同页面之间保留状态。
现在,结合下图来详细了解浏览器的工作原理:

-
用户输入网址:用户在客户端电脑的浏览器地址栏中输入网址(
URL),例如上图输入了https://www.baidu.com/,按下回车。 -
客户端向服务器发送请求
- DNS解析:浏览器向域名系统(DNS)发送请求(
request),将网址转换为IP地址。这是因为计算机使用IP地址来定位服务器。 - 建立连接:浏览器与服务器之间建立网络连接。这通常是通过HTTP请求完成的,即浏览器向服务器发送请求。
- DNS解析:浏览器向域名系统(DNS)发送请求(
-
服务器处理请求,做出响应:服务器收到浏览器的请求后,会处理请求并做出响应(
response),返回相应的数据,通常是HTML、CSS、JavaScript和其他资源。
当您打开百度主页并按下Ctrl+U时(或者右键单击,选择查看源码),您将看到网页的源代码,其中包含了构成百度主页的HTML、CSS和JavaScript等内容。
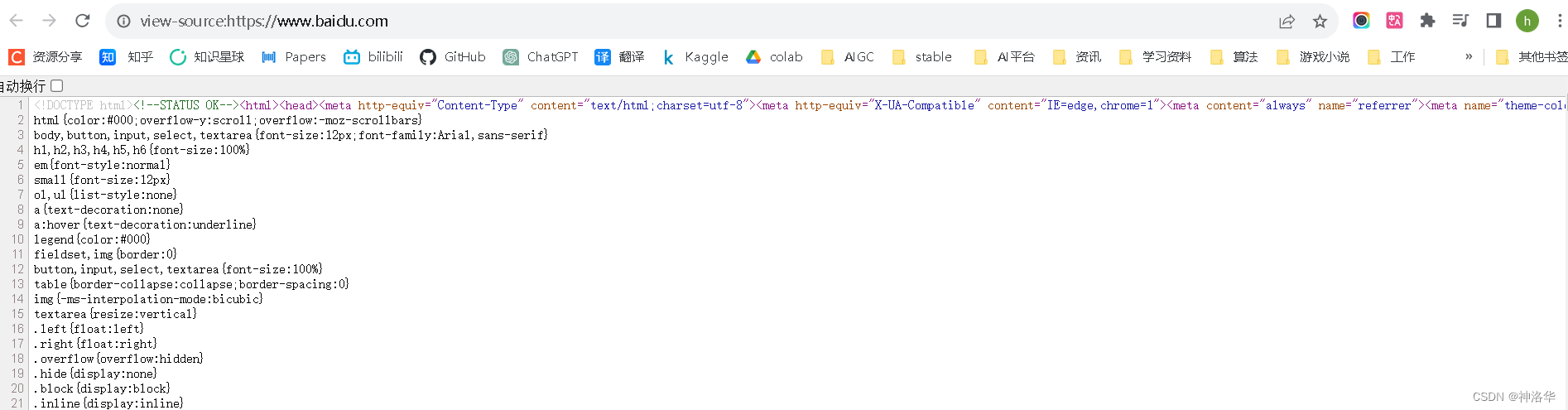

以下是您可能会在源码中看到的内容的解释:
-
HTML 结构
HTML 代码定义了页面的整体结构和布局,使用标签如<html>,<head>,<body>,<div>,<p>等来创建网页的各个元素,所以您可以看到页面的分区、导航栏、页眉、页脚等元素。 -
样式和样式表
在源码中,您可能会看到<style>标签或外部 CSS 文件的链接,这些CSS层叠样式表定义了页面的外观,如颜色、字体、间距等。 -
JavaScript 代码
如果百度主页使用了 JavaScript 来实现动态效果、交互性和功能,您会在源码中找到<script>标签或外部 JavaScript 文件的链接。 -
文本内容和图片
HTML 代码中包含了文本内容,如标题、段落、列表、按钮等。同时,您将会看到使用<img>标签插入的图片,这些图片可能是百度主页上的图标、背景图像等。 -
元数据和链接
在<head>标签中,您可能会看到<meta>标签,提供了有关页面的元数据,如字符集、作者、描述等。另外,您会看到使用<a>标签创建的链接和超链接,这些链接可能指向其他页面或资源。 -
注释和外部资源链接
源码中可能含有注释,以<!-- 注释内容 -->的形式存在,提供了关于代码目的或作者的附加信息。同时,您还可能会看到链接到外部资源的标签,如外部 CSS 文件、JavaScript 库等,这些链接可以帮助构建页面的样式和功能。
- 呈现页面:浏览器的呈现引擎解释HTML和CSS,将页面转换成用户可见的内容。
- JavaScript执行:如果页面包含JavaScript代码,浏览器会执行这些代码,实现交互性和动态效果。
- 渲染页面:呈现引擎将处理后的内容渲染到屏幕上,呈现给用户。
- 数据存储:浏览器可能会存储一些数据,如cookies、缓存和本地存储,以便在用户访问同一站点时提供更快的响应和保留用户状态。
- 页面加载完成:当所有资源都加载完毕,页面完成呈现后,用户可以浏览页面内容。
- 用户交互:用户可以继续与页面进行交互,如点击链接、填写表单等。
需要注意的是,这只是浏览器工作原理的简要概述,实际上涉及更多细节和过程。浏览器的工作涵盖了多个层面,包括网络通信、页面解析、渲染和用户交互等。不同浏览器可能在某些细节上有所不同,但总体流程是类似的。
1.2 HTTP 概述
参考官方文档《 HTTP 概述》
1.2.1 HTTP简介
HTTP: 全称为“超文本传输协议”(HyperText Transfer Protocol),是一种用于在计算机网络上传输超文本(例如 HTML、图片、视频等)的应用层协议。它是Web通信的基础,用于在客户端和服务器之间传输数据,使用户能够浏览和访问互联网上的各种资源。
客户端-服务器模型: HTTP使用了客户端-服务器模型,其中客户端通常是指用户使用的Web浏览器,而服务器是存储和提供资源的计算机。当用户在浏览器中输入一个URL或点击链接时,浏览器会向服务器发送HTTP请求,请求特定的资源。服务器收到请求后,会根据请求的内容返回相应的HTTP响应,其中包括状态码、响应头和实际的数据(如HTML文件、图片等)。
请求-响应机制: HTTP的工作方式是通过建立请求-响应的交互来实现的。每个HTTP请求都包含一个请求方法(如GET、POST、PUT等)、请求URI(统一资源标识符)、请求头和可选的请求主体。服务器根据请求的信息和方法进行处理,然后返回一个HTTP响应,包含状态码、响应头和响应主体。
无状态: HTTP协议本身是无状态的,这意味着每个请求都是独立的,服务器不会保留之前请求的状态。为了解决这个问题,引入了Cookie和Session等机制,使得服务器能够跟踪用户的状态。
总之,HTTP是Web通信的基础,它定义了客户端和服务器之间如何进行数据交换,使得用户能够在浏览器中获取和浏览各种网页和资源。
1.2.2 五层网络模型
五层网络模型是指OSI(Open Systems Interconnection)参考模型,它是一个用于理解和描述计算机网络体系结构的框架,将网络通信过程分为不同的层次,每一层都有特定的功能和责任。
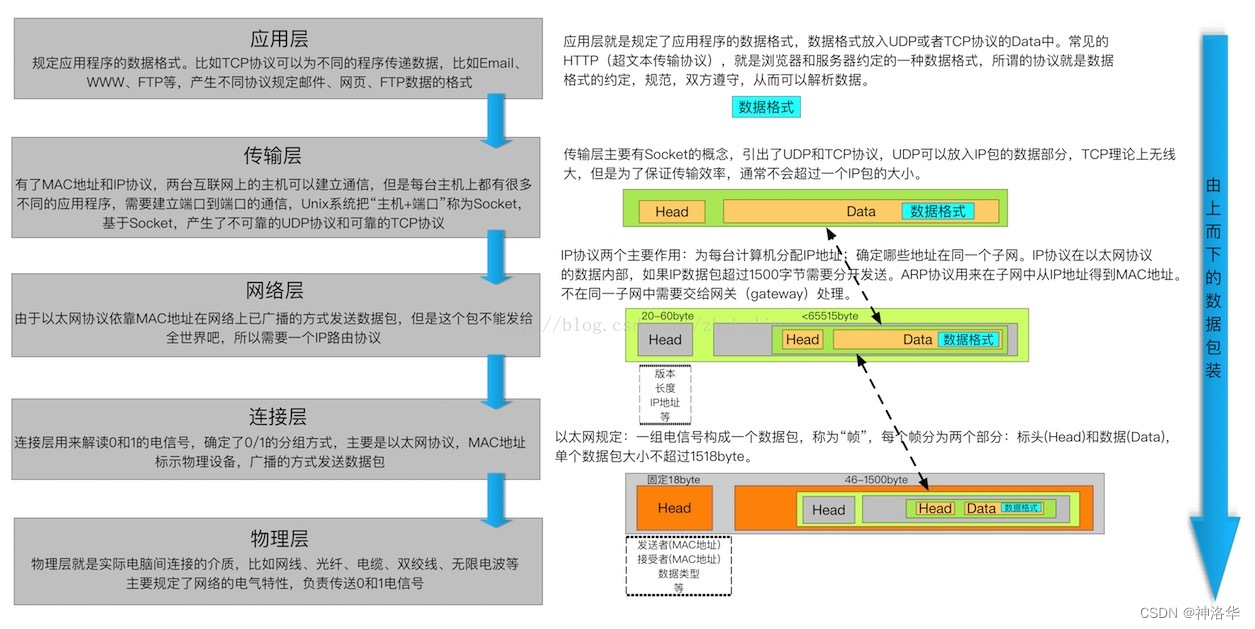
| OSI模型层 | 主要功能 | 当前层主要设备 | 设备主要作用 |
|---|---|---|---|
| 应用层 | 提供用户应用程序与网络接口,定义通信协议(如HTTP、FTP、SMTP等),以实现各种网络服务和应用的通信 | 代理服务器、负载均衡器 | 代理服务器用于代理客户端请求 负载均衡器分发网络流量到多个服务器,以实现资源的均衡利用,提高性能和可靠性。 |
| 传输层 | 提供端到端的数据传输,保证数据可靠性 | TCP&UDP | 传输层协议,用于在网络上的不同设备之间传输数据 |
| 网络层 | 负责路由和寻址。将数据从源主机发送到目标主机,通过选择最佳路径来实现跨网络的数据传输。IP(Internet Protocol)是网络层的重要协议,用于定义主机的逻辑地址 | 路由器、防火墙 | 路由器根据目标IP地址来决定如何将数据包从源网络传递到目标网络 防火墙保护网络免受攻击 |
| 数据链路层 | 负责将物理层传输的比特流划分为帧,管理物理地址(MAC地址),进行帧的错误检测和纠正,以确保可靠的点对点数据传输 | 交换机、网关 | 交换机用于在局域网(LAN)内部进行数据帧的转发和交换,它能够根据数据帧中的目标MAC地址将数据包从一个端口转发到另一个端口,以便实现网络内部设备的通信。网关连接不同网络 |
| 物理层 | 最底层,负责物理信号传输,即将数据转换为电压、电流等物理信号通过物理媒介(如电缆、光纤)进行传输 | 调制解调器、网卡 | 调制:将数字信号转换成模拟信号以便在电话线等模拟传输媒介上传输数据 解调:将模拟信号转换成数字信号 网卡连接计算机和网络媒介 |
1.2.3 HTTP组件系统
HTTP的组件系统是指构成HTTP协议的各个组成部分,这些部分共同协同工作,使得在网络上的数据传输变得高效、可靠和安全。HTTP的组件系统包括以下几个主要组件:
-
客户端(Client): 客户端通常是指用户使用的Web浏览器,它发起HTTP请求并接收服务器的HTTP响应,获取所需的资源(网页、文本、图片、视频等)。
-
服务器(Server): 服务器是存储和提供资源的计算机,它接收来自客户端的HTTP请求,并根据请求的内容作出相应的响应。服务器会处理请求,提取请求的资源,然后将响应发送回客户端。
-
代理(Proxy): 代理是一种位于客户端和服务器之间的中间服务器,用于转发请求和响应。它可以拦截、修改、缓存或过滤传输的数据。使用代理服务器还可以提高网络性能、安全性和隐私性。
- 缓存(可以是公开的也可以是私有的,如浏览器的缓存)
- 过滤(如反病毒扫描、家长控制…)
- 负载均衡(让多个服务器服务不同的请求)
- 认证(控制对不同资源的访问)
- 日志(使得代理可以存储历史信息)
-
缓存(Cache): 缓存是一种临时存储机制,用于存储已经获取过的资源的副本,以便在后续的请求中可以更快地获取相同的资源。缓存可以减轻服务器负担,加快资源访问速度。
-
网关(Gateway): 网关是连接不同协议或不同类型网络的设备,它可以将一个协议的请求转换为另一个协议的请求,从而使得不同类型的网络能够互相通信。
-
隧道(Tunnel): 隧道是通过一个协议在两个通信应用之间建立私密的连接,以保护数据传输的安全性和隐私性。HTTPS使用TLS/SSL隧道来加密HTTP数据。
所以,请求可以由由一个实体,即用户代理(user agent),或是一个可以代表它的代理方(proxy)发出。用户代理可以是一个网页浏览器,或者爬虫程序。

用户代理(
user agent)通常是指客户端(例如Web浏览器)在进行HTTP请求时的标识。它包含了一些关于客户端的信息,例如用户使用的浏览器类型、版本、操作系统等。用户代理的作用是让服务器知道请求的源头是什么类型的设备和软件,从而服务器可以根据不同的用户代理提供不同的内容或适当的响应。例如,服务器可以根据不同的用户代理提供适合移动设备或桌面设备的网页版本。
1.2.4 HTTP报文
HTTP报文在客户端向服务器发起HTTP请求或服务器向客户端发送HTTP响应时发出。
-
客户端发出HTTP请求报文: 当用户在浏览器中输入一个URL、点击链接、提交表单或执行其他操作时,浏览器会构建一个HTTP请求报文,包括请求行、请求首部和请求主体。然后,浏览器将该HTTP请求报文发送给服务器,以请求特定的资源或执行特定的操作。
-
服务器发出HTTP响应报文: 服务器收到客户端发送的HTTP请求后,会根据请求的内容进行处理,并生成一个HTTP响应报文,包括状态行、响应首部和响应主体。服务器将该HTTP响应报文发送回客户端,以返回所请求的资源或操作的结果。
下面是一个请求报文的示例:
GET / HTTP/1.1
Host: developer.mozilla.org
Accept-Language: zh
请求报文由以下元素组成:
- 请求行(Request Line):包括请求方法(如GET、POST)、请求的URI(Uniform Resource Identifier)和HTTP版本。
- 请求首部(Request Headers):包括一系列的首部字段,用于传递附加的请求信息,如User-Agent、Host、Accept等。
- 空行(Blank Line):一个空行用于分隔请求首部和请求主体。
- 请求主体(Request Body):可选部分,包含发送给服务器的数据,通常用于POST请求等情况。
下面是一个响应报文示例:
HTTP/1.1 200 OK
Date: Sat, 09 Oct 2010 14:28:02 GMT
Server: Apache
Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT
ETag: "51142bc1-7449-479b075b2891b"
Accept-Ranges: bytes
Content-Length: 29769
Content-Type: text/html
<!DOCTYPE html>…(此处是所请求网页的 29769 字节)
响应报文由以下元素组成:
- . 状态行(Status Line):包括HTTP版本、状态码和状态短语,描述服务器对请求的处理结果。
- 响应首部(Response Headers):包括一系列的首部字段,用于传递附加的响应信息,如Server、Content-Type、Content-Length等。
- 空行(Blank Line):一个空行用于分隔响应首部和响应主体。
- 响应主体(Response Body):可选部分,包含服务器返回的数据,如HTML页面、图片、文本等。
1.3 爬虫工作原理
爬虫通过模拟浏览器行为,从服务器获取数据并进行解析和处理,使我们能够有效地从互联网上获取所需的信息。爬虫一般分为两类:
通用爬虫:通常指搜索引擎的爬虫聚焦爬虫:针对特定网站的爬虫
此时没有浏览器发送请求和解析渲染数据了,而是用爬虫程序来代替,也就是下图的黄色部分

-
发送请求:爬虫程序会模拟浏览器,向目标服务器发送请求(GET请求或POST请求)。爬取的目标可以是一个特定的网页、整个网站,或者特定的数据源。
-
服务器响应:服务器收到请求后,会根据请求的类型和参数,返回相应的数据。通常,服务器会以HTML、JSON、XML等格式返回数据。
-
数据解析:爬虫程序会解析服务器返回的数据,根据预定的规则提取出所需的信息,提取文本、链接、图像等内容。
-
数据处理和存储:爬虫从页面中提取的数据会被处理和清洗,以确保数据的准确性和一致性。然后,爬虫会将这些数据存储到合适的位置,如数据库、文件或其他存储系统。
除了以上基础部分,还有一些进阶的操作:
- 处理反爬:服务器有可能会有反爬虫的策略,如限制请求频率、使用验证码等,爬虫程序需要具备处理这些问题的能力。
- 深度遍历:如果需要爬取多个页面或链接,爬虫会通过解析页面中的链接,形成一个链接队列,逐一访问这些链接并获取数据。这可以是广度优先搜索或深度优先搜索,取决于您的需求。
- 数据处理和分析:一旦爬虫获取了足够的数据,您可以进行数据分析、可视化、挖掘等操作,从中提取有价值的信息。
- 循环迭代:爬虫通常是一个持续运行的过程,因为网站内容会不断更新。爬虫需要周期性地重复上述步骤,以获取新数据并更新现有数据。
通过对比浏览器和爬虫的工作原理,可以看到,除了模拟浏览器的正常操作之外,爬虫比浏览器还多了数据的加工处理的部分。
1.4 HTML基础
1.4.1 HTML简介
HTML,全称为“超文本标记语言”(HyperText Markup Language),是一种用于创建网页内容的标记语言,它使用各种标签和元素来描述网页的结构和显示方式。
“超文本”(hypertext)是指连接单个网站内或多个网站间的网页的链接。“标记”(markup)是指HTML 使用标记来注明文本、图片和其他内容,以便于在 Web 浏览器中显示。HTML 标记包含一些特殊“元素”如 <head>、<title>、<body>、<header>等等。HTML 元素通过“标签”(tag)将文本从文档中引出,标签由在“<”和“>”中包裹的元素名组成,习惯上用小写字母表示。
HTML可以理解为网页的“骨架”。它为浏览器提供了关于网页内容如何排列、呈现和交互的信息。通过在HTML文档中插入不同类型的标记,我们可以创建文本、图像、链接、表格和其他元素。
1.4.2 HTML文档结构
一个完整的HTML文档由<head></head>标签和<body></body>两对标签组成。
-
<!DOCTYPE>声明:这是文档类型声明,用于告诉浏览器使用哪个HTML版本来渲染页面。例如:<!DOCTYPE html> -
<html>元素:这是HTML文档的根元素,包含整个HTML内容。它有两个主要部分:<head>和<body>。<head>部分:这个部分包含关于文档的元信息,如页面标题、字符集设置等。它不会在浏览器中显示出来。
例如下图是12306主页源码,其中head部分第一行标注了编码格式,title部分是网页标题,它显示在网页最上方的标签栏中,而不是网页的内容部分。
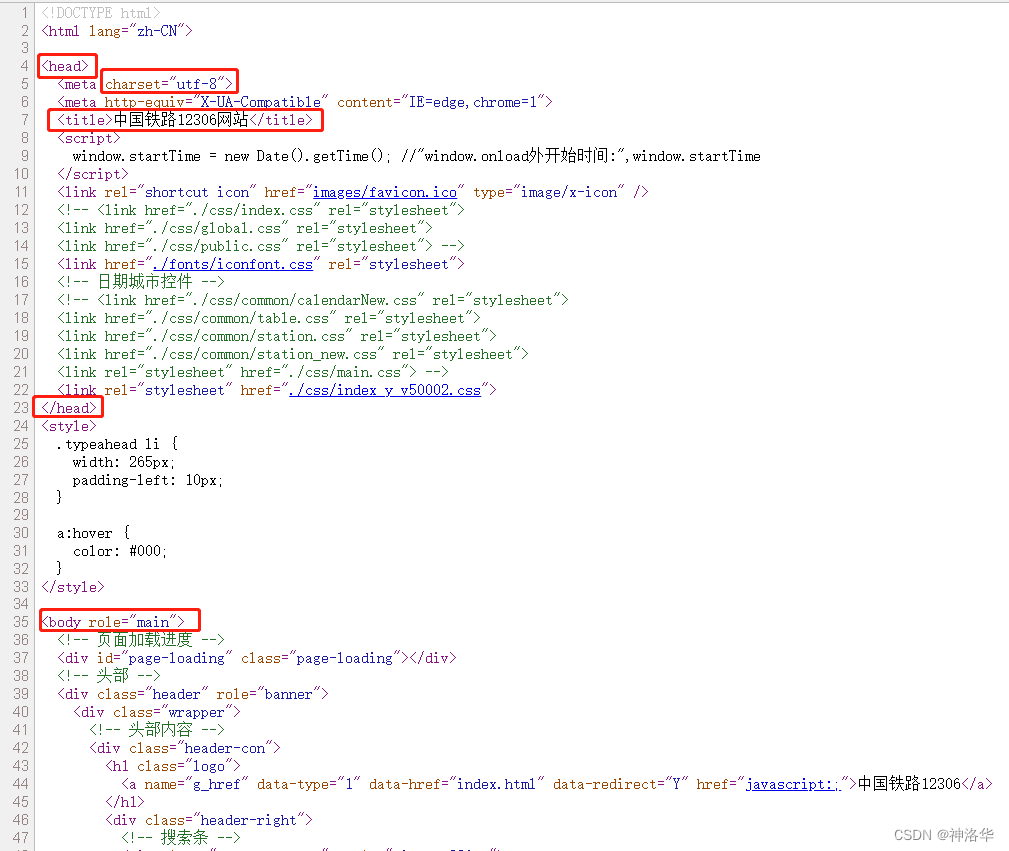
<body>部分:这是页面的主要内容区域,包含要在浏览器中显示的所有内容,如文本、图像、链接等。<body> <h1>这是一个标题</h1> <p>这是一个段落。</p> <!-- 其他内容 --> </body>
HTML文档结构的正确设置对于网页的呈现和排版非常重要。确保标签正确嵌套和关闭,以避免出现问题
1.4.3 CSS层叠样式表
1.4.3.1 CSS的作用
HTML只能定义网页的结构,但是不能定义网页的显示方式,如果要想让网页变得绚丽多彩就需要使用CSS(Cascading Style Sheet)层叠样式表,它通过定义元素的样式,如颜色、字体、大小和间距,使网页变得漂亮而富有吸引力。(分离 HTML 和 CSS 使得修改外观变得更加方便)
样式是一组规则,用于定义元素的外观。我们可以在 HTML 中直接编写样式,但更好的方法是将样式放入 外部样式表 中这样做的好处是:
- 可维护性: 所有页面共享相同的样式,更容易进行维护和修改。
- 一致性: 所有页面的外观都保持一致,增强了用户体验。
- 分离关注点: HTML 负责表示内容,CSS 负责外观,使 HTML 代码更加简洁,代码更具可读性。
CSS规则由两个主要的部分构成:选择器和一条或多条声明:

选择器和声明是定义样式的关键。选择器是用于选择要应用样式的 HTML 元素的名称。每个选择器都与一个或多个属性相关联,这些属性定义了元素的外观。
1.4.3.2 CSS选择器
CSS的选择器有三种类型:
- 元素选择器: 使用元素的名称来选择元素。例如,选择所有的
<p>元素。上图h1是标题标签,所以是标签选择器。 - 类选择器: 使用类名来选择元素。类选择器以点号
.开头,例如 .highlight。 - ID 选择器: 使用 ID 来选择元素。ID 选择器以
#开头,例如 #header。
<!DOCTYPE html>
<html>
<head>
<style>
/* 元素选择器 */
p {
color: blue;
}
/* 类选择器 */
.highlight {
background-color: yellow;
}
/* ID 选择器 */
#header {
font-size: 24px;
}
</style>
</head>
<body>
<p>这是一个段落。</p>
<p class="highlight">这是另一个段落,使用类选择器。</p>
<p id="header">这是标题,使用ID选择器。</p>
</body>
</html>
在这个示例中,我们使用了三种不同的选择器来选择不同的元素,并对它们应用不同的样式:
- 元素选择器(
<p>元素): 我们使用元素选择器选择所有的 <p> 元素,并将它们的文本颜色设置为蓝色。 - 类选择器(
.highlight类): 我们使用类选择器选择具有 “highlight” 类的元素,并将它们的背景颜色设置为黄色。 - ID 选择器(
#headerID): 我们使用 ID 选择器选择具有 “header” ID 的元素,并将它们的字体大小设置为24像素。
通过使用这些不同类型的选择器,我们可以精确地选择要应用样式的元素。这使得我们可以更好地控制页面的外观和布局。
1.4.3.3 CSS文本和字体样式
文本样式包括字体、大小、颜色、对齐方式等。通过为文本应用样式,我们可以使网页内容更易读、更吸引人。
<!DOCTYPE html>
<html>
<head>
<style>
/* 设置字体样式、颜色、大小和对齐方式 */
/*第一行表示设置body元素为 Arial 字体。如果用户的计算机上没有,浏览器将会使用默认的 sans-serif 字体*/
body {
font-family: Arial, sans-serif;
font-size: 16px;
color: #333333;
text-align: center;
background-color: #f4f4f4;
}
/* 设置标题样式 */
h1 {
font-size: 32px;
color: #ff9900;
margin-bottom: 10px;
}
/* 设置段落样式 */
p {
font-size: 18px;
line-height: 1.5;
color: #666666;
margin-bottom: 20px;
}
/* 设置链接样式 */
a {
color: #007bff;
text-decoration: none;
}
/* 设置按钮样式 */
.button {
display: inline-block;
padding: 10px 20px;
background-color: #007bff;
color: #ffffff;
border: none;
border-radius: 5px;
cursor: pointer;
}
</style>
</head>
<body>
<h1>Welcome to My Website</h1>
<p>This is a sample paragraph with <a href="#">a link</a> for demonstration.</p>
<button class="button">Click Me</button>
</body>
</html>
<body>元素的样式包括字体、大小、颜色和对齐方式,以及背景颜色。<h1>元素的样式包括字体大小、颜色和下边距。<p>元素的样式包括字体大小、行高、颜色和下边距。<a>元素的样式设置了链接的颜色和去掉下划线。.button类的样式设置了按钮的背景颜色、文字颜色、边框和圆角。
1.4.4 HTML元素和标签
HTML文档使用不同的元素和标签来描述网页的结构和内容。元素通常由一个开始标签、内容和结束标签组成,如<tag>内容</tag>,以下是常用的HTML标签:

- 段落和标题:通过使用标题和段落标签,你可以轻松地将文本内容组织成易于理解的格式(html代码):
<h1>这是一级标题</h1>
<h2>这是二级标题</h2>
<h3>这是三级标题</h3>
<!-- ...依此类推 -->
<p>这是一个段落。</p>
<p>这是另一个段落。</p>
- 超链接:通过使用超链接,你可以在网页之间创建丰富的连接,使用户能够轻松地导航到其他页面和资源。
- 使用
<a>标签创建超链接,你可以在href属性中指定链接的目标。例如,要创建一个指向Google的超链接,你可以这样写:
<a href="https://www.google.com">访问Google</a>
- 内部链接
如果你想创建到同一网站的内部链接,你可以使用相对路径。例如,如果你的网页中有一个叫做about.html的页面,你可以这样创建内部链接:
<a href="about.html">关于我们</a>
- 链接到电子邮件
你还可以使用超链接创建电子邮件链接,使用户能够点击链接发送电子邮件。例如:
<a href="mailto:[email protected]">联系我们</a>
- 无序列表
<ul>和有序列表<ol>
无序列表用于创建项目没有特定顺序的列表。每个项目通常用圆点或其他符号来标记,例如:
<ul>
<li>苹果</li>
<li>香蕉</li>
<li>橙子</li>
</ul>
有序列表用于创建项目按照特定顺序排列的列表。每个项目通常使用数字或字母来标记。例如:
<ol>
<li>第一步</li>
<li>第二步</li>
<li>第三步</li>
</ol>
自定义列表项<li>:列表项标签<li>用于定义每个列表项目。它可以嵌套在无序列表或有序列表中。
- 图像
要在网页中插入图像,你可以使用<img>标签,并在src属性中指定图像的URL。例如:
<img src="image.jpg" alt="这是一个图像">
src属性:图像的URL地址。alt属性:图像的替代文本,用于在图像无法加载时显示。
你可以使用width和height属性来调整图像的尺寸。注意,尽量不要拉伸图像,以免影响图像质量。例如:
<img src="image.jpg" alt="这是一个图像" width="200" height="150">
如果想要并排显示图像,可以输入:
<table>
<tr>
<td><img src="https://img-blog.csdnimg.cn/f59bf67c952e49a0ba140a4448f42b46.png" alt="Image 1" height="300"></td>
<td><img src="https://img-blog.csdnimg.cn/3b8a2546b95b469da774488590a58613.png" alt="Image 2" height="300"></td>
<td><img src="https://img-blog.csdnimg.cn/5bd1383143b642bcbf56f50389303cbe.png" alt="Image 2" height="300"></td>
</tr>
</table>
显示如下:
 |
 |
 |
- 分区标签
<div>
分区标签<div>是HTML中的一个重要元素,用于创建一个容器来组织和样式化网页内容。它本身并没有特定的样式或效果,其主要作用是将相关内容分组并添加样式,比如用CSS来为<div>添加样式。例如:
<div class="content">
<h1>欢迎来到我们的网站</h1>
<p>在这里,你会发现很多有趣的内容。</p>
</div>
你还可以为<div>添加类名或ID,然后使用CSS来为其添加样式。例如,给<div>添加类名:
<div class="info">
<p>这是一些重要信息。</p>
</div>
然后,在CSS中为类名添加样式(css代码):
.info {
background-color: lightgray;
padding: 10px;
}
- 行内元素标签
<span>
行内元素标签<span>是HTML中的一个重要元素,用于对文本中的特定内容应用样式,从而增强网页的可读性和吸引力。例如:
<p>这是一段 <span class="highlight">高亮</span> 的文本。</p>
你还可以为<span>标签添加类名或ID,并使用CSS样式化内部内容。
- 给
<span>添加类名:
<p>这是一段 <span class="important">重要</span> 的信息。</p>
- 在CSS中为类名添加样式:
.important {
font-weight: bold;
color: red;
}
- 表格
表格是网页中用于展示数据的重要元素。HTML提供了<table>标签,用于创建表格。
<table>
<tr>
<th rowspan="2">姓名</th>
<th>年龄</th>
</tr>
<tr>
<td>25</td>
</tr>
<tr>
<td>小红</td>
<td>22</td>
</tr>
</table>
<table>:定义表格。<tr>:定义表格的行。<th>:定义表头单元格,通常用于表头。<td>:定义普通单元格,用于表格数据。rowspan和colspan:合并单元格。
- 表单
表单是网页中用于收集用户输入数据的重要元素。HTML提供了多种表单元素,例如文本框、单选按钮、复选框等。要创建一个表单,你需要使用<form>标签,并在其中添加各种表单元素。
<form>
<label for="username">用户名:</label>
<input type="text" id="username" name="username"><br>
<label for="password">密码:</label>
<input type="password" id="password" name="password"><br>
<label for="gender">性别:</label>
<input type="radio" id="male" name="gender" value="male">
<label for="male">男性</label>
<input type="radio" id="female" name="gender" value="female">
<label for="female">女性</label><br>
<input type="submit" value="提交">
</form>
在这个例子中,我们使用了<input>标签来创建文本框、密码框和单选按钮。还使用了<label>标签来为每个输入项添加标签。
表单元素类型
text:文本框,用于输入文本。password:密码框,用于输入密码。radio:单选按钮,用于从多个选项中选择一个。checkbox:复选框,用于选择一个或多个选项。submit:提交按钮,用于提交表单数据。
例如我们打开12306网站,点击注册,就可以看到下面的表单。其中用户名是文本框,登录密码是密码框,证件类型是下拉选框,“我已阅读同意”前面的方框是复选框,下一步是提交按钮。

1.5 JavaScript
1.5.1 简介
JavaScript简称JS,是一种由客户端浏览器运行的动态脚本语言,旨在为网页添加交互性和动态性。JavaScript可以实现以下功能:
- 添加交互性:通过 JavaScript,可以让网页元素在用户交互时产生响应,如按钮点击、鼠标悬停等。
- 动态内容:JavaScript 可以动态地更新网页内容,而不需要刷新整个页面。
- 表单验证:通过验证用户输入,JavaScript 可以确保表单数据的准确性和完整性。
- 数据交互:JavaScript 可以通过 AJAX 或 Fetch API 与服务器进行数据交换,实现无需刷新的数据更新。
- 动画效果:JavaScript 可以创建各种动画效果,使页面更具吸引力和生动性。
1.5.2 基本语法
JavaScript 有一些基本的语法规则:
- 语句:JavaScript 代码由一条条语句组成,每条语句以分号结尾。
- 变量:使用关键字
var、let或const声明变量,例如:var age = 25; - 数据类型:JavaScript 有多种数据类型,如数字、字符串、布尔值、数组、对象等。
- 函数:使用关键字
function定义函数,函数可以接受参数并执行特定的操作。 - 条件语句:使用
if、else if和else来执行条件判断。 - 循环语句:使用
for、while或do while来进行循环操作。
现在,让我们进一步探讨 JavaScript 的基本语法和概念。
- 变量声明和赋值: 使用
var、let或const来声明变量。例如:var name = "Alice"; let age = 30; const PI = 3.14;
在命名变量时,需要遵循一些规则:
- 变量名必须以字母、下划线(_)或美元符号($)开头。
- 变量名可以包含字母、数字、下划线或美元符号。
- 变量名区分大小写,例如
myVariable和MyVariable是不同的变量。
- 数据类型: JavaScript 有不同的数据类型,包括字符串、数字、布尔值、数组、对象等。对象是一种复合的数据类型,它可以存储多个键值对。每个键都是一个字符串,对应一个值。对象可以存储不同类型的值。
// 声明各种数据类型的变量
var numberVar = 42; // 数字
var stringVar = "Hello, World!"; // 字符串
var booleanVar = true; // 布尔值
var nullVar = null; // 空值
var undefinedVar = undefined; // 未定义
var arrayVar = [1, 2, 3]; // 数组
var objectVar = {
// 对象
name: "John",
age: 30,
isStudent: false
};
var functionVar = function() {
// 函数
return "这是一个函数";
};
// 输出各种数据类型的值和类型
console.log("numberVar:", numberVar, typeof numberVar);
...
在上面的示例中,我声明了各种数据类型的变量,并使用 typeof 运算符来确定每个变量的数据类型。你可以在控制台中查看输出,了解每种数据类型的值和类型。
- 函数定义: 使用
function关键字定义函数,例如:
function add(a, b) {
return a + b;
}
var result = add(3, 5);
console.log("结果:" + result);
- 条件语句: 使用
if、else if和else进行条件判断。例如:
var age = 18;
if (age < 18) {
console.log("未成年人");
} else if (age >= 18 && age < 60) {
console.log("成年人");
} else {
console.log("老年人");
}
- 循环语句: 使用
for、while或do while来执行循环操作。例如:
for (var i = 0; i < 5; i++) {
console.log("循环次数:" + i);
}
var count = 0;
while (count < 3) {
console.log("计数:" + count);
count++;
}
1.5.3 基本操作
- 操作符:JavaScript 支持多种操作符,用于执行不同的操作,例如加法、减法、乘法等。例如:
var sum = 5 + 3; // 加法
var difference = 7 - 2; // 减法
var product = 4 * 6; // 乘法
var quotient = 12 / 3; // 除法
- 类型转换:JavaScript 会自动进行类型转换,但有时你可能需要显式地转换数据类型。例如:
var numString = "5"; // 字符串
var num = parseInt(numString); // 转换为整数
- 数组和对象操作:你可以使用索引访问数组中的元素,例如
fruits[0]访问数组的第一个元素。对象的属性可以通过键来访问,例如person.name访问对象的name属性。 - 字符串操作:JavaScript 提供了许多字符串操作方法,如拼接、截取、查找等。例如:
var greeting = "Hello";
var name = "Alice";
var message = greeting + ", " + name + "!"; // 字符串拼接
- JavaScript 动画和效果
通过 JavaScript,你可以为网页添加动画和效果,使用户体验更加生动和吸引人。例如,你可以使用setInterval或requestAnimationFrame来创建动态效果。
var element = document.getElementById("myElement");
var position = 0;
function animate() {
position += 2;
element.style.left = position + "px";
requestAnimationFrame(animate);
}
animate();
1.5.4 事件处理
通过 JavaScript,你可以为网页元素添加事件监听器,实现交互性。假设你想编写一个简单的 JavaScript 程序,让用户输入名字并显示问候信息:
// 获取用户输入
var name = prompt("请输入您的名字:");
// 构造问候信息
var message = "你好," + name + "!欢迎来到 JavaScript 的世界!";
// 显示问候信息
alert(message);
DOM(Document Object Model)是一种将 HTML 文档中的每个元素都视为对象的方式。通过 DOM,你可以使用 JavaScript 访问、修改和操作网页上的元素,例如文本、图像、按钮等。通过 DOM,你可以监听用户在页面上的操作,例如点击按钮、鼠标移动等。你可以使用 addEventListener 方法来添加事件监听器。例如:
myButton.addEventListener("click", function() {
console.log("按钮被点击了!");
});
1.5.5 前端框架和库
前端框架和库可以帮助你更高效地构建用户界面和交互。例如,React 允许你构建可复用的 UI 组件,Vue 提供了响应式数据绑定,Angular 则提供了完整的开发框架。
在实际项目中,代码往往非常庞大,为了更好地组织和管理代码,我们使用模块化的方法。这意味着将代码分割成不同的模块,每个模块负责特定的功能。包管理器如 npm(Node.js 包管理器)和 yarn 使我们能够方便地安装、管理和分享代码库。你可以通过这些工具来使用其他开发者编写的代码库。
二、网络请求
2.1 urllib(Python内置模块)介绍
urllib 是 Python 的一个标准库,用于处理 URL和执行网络请求。它提供了一些模块,可以帮助你发送 HTTP 请求、解析 URL 和处理网络数据。urllib 库包括以下主要模块:
urllib.request:用于发送各种类型的 HTTP 请求,并获取服务器响应,包括状态码、响应头和响应体。urllib.parse:用于对 URL 中的数据进行编码和解码。- 解析 URL:
urllib.parse模块可以解析 URL,将其分解为协议、主机、路径、查询参数等各个部分。 - 编码:
urllib.parse可以构建URLs,以便在请求中传递参数。
- 解析 URL:
urllib.error:包含异常类,用于处理与网络请求相关的异常。urllib.robotparser:用于解析 robots.txt 文件,以确定网站是否允许爬虫访问。
urllib发送请求可以使用urllib.request.urlopen()方法,参数文档如下:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
-
url:要打开的 URL 地址,可以是一个字符串(URL)或一个Request对象(定制的请求,例如设置请求头、数据等)。 -
data:可选参数,用于在请求中发送的数据。未提供时使用 GET 发送请求,否则将使用 POST 请求发送,并且会将这些数据附加到请求体中。 -
timeout:可选参数,设置超时时间,单位为秒。如果服务器在指定时间内没有响应,将会引发一个超时异常。 -
cafile/capath/cadefault:CA 证书文件相关的可选参数,暂不需要了解。 -
context:可选参数,用于传递一个ssl.SSLContext对象,用于配置 SSL/TLS 设置,例如指定加密协议、验证模式等。
这个方法会返回一个类似文件对象的响应,可以使用处理于文件对象的方法来读取响应数据,例如 read()、readline()、readlines() 等。
2.2 request介绍
requests 是一个流行的 Python 第三方库,用于发送 HTTP 请求并处理响应。它提供了一种简单、优雅的方式来进行网络通信,支持多种请求方法(GET、POST、PUT、DELETE 等),自动处理 URL 编码、Cookie、会话管理、SSL 验证等。
requests 通常被认为更加简洁易用,并提供了更多的功能和配置选项。以下是 requests 库的主要功能、常用模块和方法的详细介绍:
主要功能:
- 发送 HTTP 请求:支持多种请求方法,如 GET、POST、PUT、DELETE 等。
- 处理响应:自动解析服务器响应,提供易于使用的 API 访问响应内容和头信息。
- 处理 URL 编码:自动将参数编码并添加到 URL 中。
- 处理 Cookies:支持自动管理 Cookies,可以在请求之间保持会话状态。
- 会话管理:支持会话对象,可以跨请求保持会话状态。
- SSL 验证:支持 SSL/TLS,可以验证服务器证书。
- 异常处理:提供详细的异常信息,方便进行错误处理。
- 响应内容解码:自动处理响应内容的编码。
- 文件上传:支持上传文件。
- 支持 JSON 解析:自动将 JSON 响应解析为 Python 对象。
常用模块:
requests:主要模块,包含各种 HTTP 请求方法的函数。requests.sessions:用于创建和管理会话,保持会话状态。requests.exceptions:包含各种可能的异常类,用于捕获错误情况。
常用方法和参数用法:
-
requests.get(url, params=None, **kwargs):- 发送一个 GET 请求到指定的 URL。
url:请求的目标 URL。params:一个字典或字符串,作为 URL 参数。requests会自动将参数进行 URL 编码,并将其添加到 URL 中。**kwargs:其他关键字参数,用于设置请求的各种属性,例如请求头、超时时间等。
-
requests.post(url, data=None, json=None, **kwargs):- 发送一个 POST 请求到指定的 URL。
url:请求的目标 URL。data:一个字典、元组列表或字符串,作为 POST 请求的数据体。如果设置了data,Content-Type会被设置为application/x-www-form-urlencoded,数据将被编码成表单数据。json:一个字典,作为 POST 请求的 JSON 数据体。如果设置了json,Content-Type会被设置为application/json。**kwargs:其他关键字参数,用于设置请求的各种属性,例如请求头、超时时间等。
常用的 kwargs 参数包括:
headers:自定义请求头。cookies:自定义 Cookies。auth:HTTP 基本认证。timeout:请求超时时间。
requests.Session(): 创建一个会话对象,用于跨多个请求保持会话状态。response.text: 获取响应内容,自动处理编码。response.status_code: 获取响应状态码。response.json(): 将 JSON 响应内容解析为 Python 对象。response.headers: 获取响应头信息。response.cookies: 获取响应中的 Cookies。response.raise_for_status(): 如果请求失败,抛出异常。requests.exceptions.RequestException: 基本的请求异常类,可以捕获大多数请求错误。
2.3 发送请求
2.3.1 发送GET请求
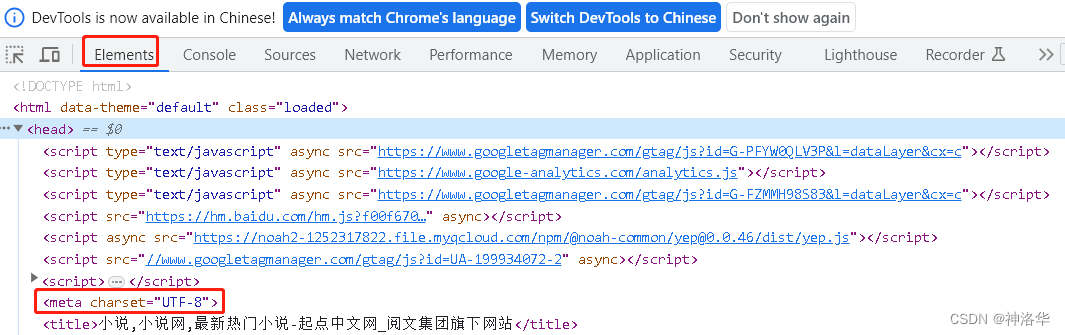
下面以起点中文网为例。按F12打开开发者模式,可见其编码格式为utf-8,所以对于读取到的服务器响应数据,要将其转为utf-8编码格式,才能正确显示中文。
- 使用urllib发送GET请求
import urllib.request
url = "https://www.qidian.com/"
response = urllib.request.urlopen(url)
content = response.read()
page_content = content.decode('utf-8') # 转成utf-8编码格式
print(page_content)
- 使用requests发送GET请求
import requests
url = "https://www.qidian.com/"
response = requests.get(url)
page_content = response.text # response.text会根据响应头中的字符编码自动进行解码
print("page_content:", page_content)
2.3.2 response 对象(requests)
发送GET请求后返回的是 response 对象,其中包含了许多信息,下面以requests库为例,列举常用的 response 对象属性和方法:
response.status_code: 获取响应的状态码,例如 200 表示成功,404 表示页面不存在等。response.headers: 获取响应头信息,返回一个字典,包含响应的头部字段。可获取特定的响应头字段的值,例如response.headers['Content-Type']。response.text: 获取响应的内容,以字符串形式返回。response.content: 获取响应的二进制内容,以字节形式返回,如图片、视频等。response.json(): 解析 JSON 格式的响应,返回一个 Python 对象response.url: 获取实际的请求 URL,用于处理重定向。response.cookies: 获取响应中的 Cookies,返回一个RequestsCookieJar对象。response.elapsed: 获取请求的响应时间,以datetime.timedelta对象表示。
下面我们来解析 response 对象:
print("Status code:", response.status_code)
print("Headers:", response.headers)
print("URL:", response.url)
if response.status_code == 200:
page_content = response.text # response.text会根据响应头中的字符编码自动进行解码
print("page_content:", page_content)
else:
print("Failed to retrieve the page. Status code:", response.status_code)
Status code: 200
Headers: {
'Date': 'Sun, 20 Aug 2023 09:17:39 GMT', 'Content-Type': 'text/html; charset=utf-8', 'set-cookie': 'newstatisticUUID=1692523058_129891282; Max-Age=31536000; Expires=Mon, 19-Aug-2024 09:17:38 GMT; Domain=qidian.com; Path=/', 'X-XSS-Protection': '1; mode=block', 'X-Content-Type-Options': 'nosniff', 'Content-Security-Policy': "frame-ancestors 'self' *.qidian.com *.hongxiu.com *.yuewen.com *.qq.com *.qdmm.com *.readnovel.com *.xs8.cn *.xxsy.net *.tingbook.com *.lrts.me *.ywurl.cn *.qdwenxue.com *.if.qidian.com www.gameloop.com", 'Content-Encoding': 'gzip', 'Server': 'Lego Server', 'X-Cache-Lookup': 'Cache Miss, Cache Miss', 'Transfer-Encoding': 'chunked', 'X-NWS-LOG-UUID': '1598994162829249285', 'Connection': 'keep-alive', 'Strict-Transport-Security': 'max-age=31536000;'}
URL: https://www.qidian.com/
下面是一些常见的网站服务器响应码及其含义:
| 响应码 | 含义 |
|---|---|
| 200 | OK - 请求成功 |
| 201 | Created - 创建成功 |
| 204 | No Content - 无响应内容 |
| 400 | Bad Request - 请求错误 |
| 401 | Unauthorized - 未授权 |
| 403 | Forbidden - 禁止访问 |
| 404 | Not Found - 资源不存在 |
| 405 | Method Not Allowed - 不允许的请求方法 |
| 500 | Internal Server Error - 服务器内部错误 |
| 502 | Bad Gateway - 错误的网关 |
| 503 | Service Unavailable - 服务不可用 |
2.3.3 含请求参数的GET请求(解析 URL)
我们打开香网小说http://www.xiang5.com,在主页搜索小说“主神崛起”,可以看到地址栏显示为http://www.xiang5.com/search.php?keyword=主神崛起,但是复制下来却是http://www.xiang5.com/search.php?keyword=%E4%B8%BB%E7%A5%9E%E5%B4%9B%E8%B5%B7。
我们按下F12开启开发者模式,刷新网页。在network选项卡中选择第一个网页,在右侧Headers中,可以看到,Request URL也显示为http://www.xiang5.com/search.php?keyword=%E4%B8%BB%E7%A5%9E%E5%B4%9B%E8%B5%B7。这是因为,为了保证兼容性和避免问题,通常URL 中会使用 URL 编码来表示中文字符。

URL 编码会将特殊字符转换成 % 符号后跟两个十六进制数,以便在 URL 中传输和解析。
2.3.3.1 urllib编码解码
我们可以使用urllib.parse的urlencode方法对URL中的中文进行编码,也可以使用unquote方法对编码后的URL进行解码。
import urllib.parse
url = 'http://www.xiang5.com/search.php'
# 准备待处理的数据
d={
'keyword':'主神崛起'} # 上面例子中,网址里主神崛起是keyword的值
# 发送请求时,URL中的中文要进行编码处理
encoded_params=urllib.parse.urlencode(d) # 对url地址进行编码操作
print(d_urlencode)
# 再次解码验证
s=urllib.parse.unquote(d_urlencode)
print(s,type(s))
full_url = url + '?' + encoded_params # 构建完整的 URL
response = urllib.request.urlopen(full_url)
page_content = response.read().decode('utf-8')
keyword=%E4%B8%BB%E7%A5%9E%E5%B4%9B%E8%B5%B7
keyword=主神崛起 <class 'str'>
2.3.3.2 request自动编码解码
和urllib不同,request可以自动对URL和响应内容进行编码,所以更加便捷。
- URL 编码:
requests: 在使用requests时,你可以将参数作为字典传递给请求方法,并且requests库会自动将参数进行 URL 编码,构建出完整的 URL。你无需手动进行 URL 编码。urllib: 在使用urllib时,你需要手动使用urllib.parse.urlencode()对参数进行 URL 编码,并将编码后的参数字符串拼接到 URL 中,以构建完整的 URL。
- 响应编码处理:
requests:requests库会根据响应头中的字符编码(如Content-Type)自动解码响应内容,你可以直接使用response.text获取已解码的文本内容。urllib:urllib库不会自动解码响应内容,你需要使用.decode()方法手动对响应内容进行解码,通常是使用'utf-8'编码。
import requests
# 方式一:参数直接写到URL中
url = 'http://www.xiang5.com/search.php?keyword=主神崛起'
response = requests.get(url) # requests自动编码URL
# 方式二:参数以传参方式传递
url2 = 'http://www.xiang5.com/search.php'
params2 = {
'keyword': '主神崛起'} # 将中文字符作为参数传递
response2 = requests2.get(url2, params=params)
如果地址栏中没有键值对,而只是/隔开,可以写成:
import requests
url3 = 'https://www.qidian.com/so/主神崛起.html' # 包含中文字符的完整 URL
response3 = requests.get(url3)
对于获取的响应,直接使用response.text获取结果:
if response3.status_code == 200:
page_content3 = response3.text
print(response3.encoding)
print(page_content3)
else:
print("Failed to retrieve the page. Status code:", response3.status_code)
utf-8
<!doctype html><html data-theme="default"> <head>...</head>
...
对于 response.text,通常情况下,requests 库会自动根据响应头的 Content-Type 字段来选择正确的字符编码。如果出现乱码问题,通常是因为服务器返回的内容和解码方式不匹配,在这种情况下,可以尝试使用 response.content 获取原始的二进制内容,然后手动指定正确的编码进行解码。
例如我们爬取香网数据,直接打印response.text,返回结果没有正常显示。此时可以使用response.content..decode('utf-8'),指定编码格式:
import requests
url2 = 'http://www.xiang5.com/' # 包含中文字符的完整 URL
response2 = requests.get(url2)
page_content2 = response2.text
print(response2.encoding) # 返回编码格式不对
page_content2 = response2.content.decode('utf-8') # 如果不在此指定编码格式,返回内容会乱码
print(page_content2)
ISO-8859-1
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
...
response.text和response.content的差异:response.text和response.content都是用于获取响应内容的属性,但它们在处理内容的方式上有一些不同。
response.text:
- 返回一个字符串对象,自动使用正确的字符编码(例如 UTF-8)来解码响应内容。
- 如果响应内容中包含文本,使用
response.text可以直接得到以字符串形式表示的内容。- 如果响应内容是二进制数据,
response.text会尝试自动使用正确的编码进行解码,但有时可能会出现解码错误,需要手动指定编码。- 适合处理包含文本信息的响应,如 HTML、XML、JSON 等。
response.content:
- 返回一个字节对象(
bytes类型),即原始的二进制内容。
- 不进行任何编码解码,以原始的字节形式返回响应内容。
- 适合处理包含二进制数据的响应,如图片、音频、视频等。
2.3.4 发送POST请求
2.3.4.1 GET请求和POST请求的区别
GET 请求和 POST 请求是 HTTP 协议中的两种常见请求方法,都用于在客户端(通常是浏览器)和服务器之间传递数据。但是GET 请求通常用于获取服务器上的数据,而不会对服务器的状态产生影响;而 POST 请求通常用于提交数据到服务器,可能会对服务器的状态进行修改。另外,二者还有一些区别:
-
数据传递位置:
- GET 请求: 请求数据会附加在 URL 的查询字符串中(地址栏中),即在 URL 后面使用
?将参数和值连接起来,参数之间使用&分隔。例如:https://www.example.com/search?query=keyword&page=1。 - POST 请求: 请求数据会包含在请求体中(在
payload中显示),而不是附加在 URL 上。
- GET 请求: 请求数据会附加在 URL 的查询字符串中(地址栏中),即在 URL 后面使用
-
安全性
- GET 请求: 数据以键值对的形式直接附加在 URL 上,可被轻松看到和修改。因此,不适合传递敏感信息。
- POST 请求: 数据在请求体中,不会被直接暴露在 URL 中,相对来说更安全,适合传递敏感信息。
综上所述,GET 请求参数在URL中,所以适用于非敏感数据的传递,如检索、搜索等。而 POST请求参数在请求体中, 更适合传递敏感信息和提交数据给服务器,比如提交表单(注册/登录)、上传下载文件等。
下面还是以香网小说举例,打开http://www.xiang5.com/,在左上角随便输入账户名amdin和密码admin进行登录。在network中打开第一个login网页,右侧可以看到请求方式是POST,请求网址是http://pass.xiang5.com/login.php。

点击payload可以查看输入的登录账号和密码,而没有显示在URL中。

2.3.4.2 使用requests发送POST请求
要发送 POST 请求,你需要创建一个请求对象并在其中设置请求的方法为 “POST”,同时传递需要发送的数据作为参数。下面是一个简单的示例:
import requests
# 请求的网址
url='http://pass.xiang5.com/login.php'
# 请求需要携带请求参数。上图中payload中已经显示了参数名称和内容
data={
'username':'admin','password':'admin'}
# 发送POST请求并获取响应结果
response=requests.post(url,data=data)
print(response)
2.3.4.3 使用GET请求下载百度logo和百度首页
打开https://www.baidu.com/,按下F12打开开发者模式,刷新页面,选择[email protected],这个就是百度logo图片。

点击Header可以看到其URL为https://www.baidu.com/img/flexible/logo/pc/[email protected]。下面我们用POST请求来进行下载:
import requests
url='https://www.baidu.com/img/flexible/logo/pc/[email protected]' # 请求的url
response=requests.get(url) # 发送请求并获取响应结果
# 输出详细的响应信息
print('响应状态码:',response.status_code)
print('请求的链接:',response.url)
data=response.content # 使用变量data存储字节方式的响应体
print('字节方式的响应体:',data)
# 将响应的内容保存为图片文件,wb表示写入字节数据
with open('logo.png', 'wb') as file:
file.write(data)
虽然理论上也可以使用 POST 请求下载资源,但这不符合 HTTP 请求的语义和习惯,也可能会引起混淆。因此,在下载静态资源时,使用 GET 请求更加常见和合适。POST 请求通常用于向服务器提交数据,而不是用于获取资源。
同理,我们也可以使用requests下载百度首页:
import requests
url='https://www.baidu.com/'
response=requests.get(url)
data=response.text
#将响应的字符串响应体保存到本地存储
with open('baidu.html', 'w',encoding='utf-8') as file:
file.write(data)
2.4 使用请求头
许多网站会采取反爬虫措施,限制或拒绝自动化爬取工具的访问。比如在访问豆瓣网站的首页时,使用正常的爬虫代码,响应结果状态码为418。
一种常见的反爬措施是检查请求头中的用户代理(User-Agent)信息,来判断是否为真实浏览器发起的请求。如果请求头中的用户代理信息不符合浏览器的特征,服务器可能会认为这是自动化爬取程序,并拒绝响应或返回错误码(如状态码 418 - I’m a teapot)
另外, 一些网站可能会根据用户代理信息提供不同的响应内容,比如移动版和桌面版的页面。
所以,通过设置合适的请求头,你可以模拟浏览器行为,避免被识别为爬虫,并获得正确的响应。
我们打开豆瓣官网——https://www.douban.com/,进入开发者模式,往下拉可以看到User-Agent信息,我们将其添加到GET请求头中,就可以正确爬取豆瓣首页内容例了。
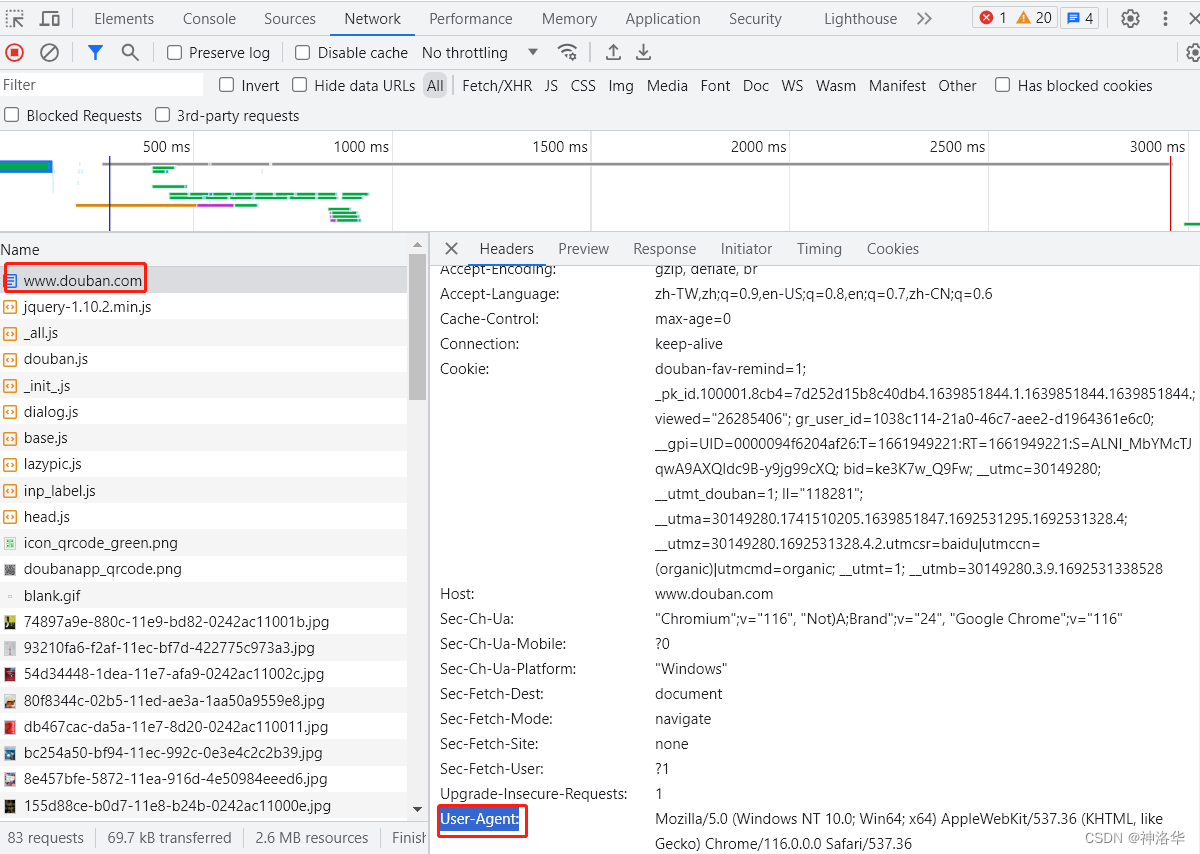
import requests
#请求的url
url='https://www.douban.com/'
# 字典形式定义请求头信息
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'
}
# 发送请求并获取响应结果
response=requests.get(url,headers=headers)
#输出响应对象
print(response)
<Response [200]>
三、数据解析
3.1 XPath解析
lxml: 用于处理 XML 和 HTML 文档的库,lxml官方文档。
3.1.1 XML文档的树状结构
XPath是XML Path Language的简称,即XML路径语言。它是一种小型的查询语言,可以在XML文档中查找信息,同时它也支持在HTML语言中查找信息。
XML 文档通常采用树状结构来组织数据,其中有且只有一个根元素(library),每个元素都可以包含子元素和属性。以下是一个简单的 XML 文档的树状结构示例:
<library>
<book id="1">
<title>Harry Potter and the Sorcerer's Stone</title>
<author>J.K. Rowling</author>
<genre>Fantasy</genre>
</book>
<book id="2">
<title>The Great Gatsby</title>
<author>F. Scott Fitzgerald</author>
<genre>Classic</genre>
</book>
</library>
在这个示例中,XML 文档描述了一个图书馆的书籍信息。树状结构如下:
library
├─ book
│ ├─ title
│ │ └─ Harry Potter and the Sorcerer's Stone
│ ├─ author
│ │ └─ J.K. Rowling
│ └─ genre
│ └─ Fantasy
└─ book
├─ title
│ └─ The Great Gatsby
├─ author
│ └─ F. Scott Fitzgerald
└─ genre
└─ Classic
在这个树状结构中:
- library 是根元素,它包含两个 book 元素作为子元素;
- 每个 book 元素都包含 title、author 和 genre 子元素
- title、author 和 genre 子元素包含文本内容(一对标签中间的是文本),分别表示书名、作者和书籍类型。
- 你可以在元素标签内部使用 name=“value” 的形式来添加属性。上面例子中,每个 book 元素都有一个id属性。
3.1.2 XPath路径表达式
XPath Helper 是一种用于浏览器的扩展程序,通常用于帮助开发人员在网页上使用 XPath 表达式来选择和定位 HTML 或 XML 文档中的特定元素。它可以方便地测试和验证 XPath 表达式,并查看匹配的结果,从而帮助开发人员调试和开发网页抓取、数据提取、自动化测试等应用。
在此之前,我们先学习一下如何使用XPath表达式选取节点(以上面library的xml文档举例:)
| 语法 | 描述 | 示例 | 结果 |
|---|---|---|---|
nodename |
选取所有指定节点的子节点 | book |
<book id="1">, <book id="2"> |
/ |
从根节点选取 | /library/book |
<book id="1">, ``` |
// |
选取文档中的所有匹配节点 | //book |
<book id="1">, <book id="2"> |
. |
选取当前节点 | . |
<library>...</library> |
.. |
选取当前节点的父节点 | .. |
无匹配,因为根节点没有父节点 |
@attributename |
选取当前节点的指定属性 | //book[@id] |
1, 2 |
[@attributename='value'] |
选取具有指定属性值的节点 | //book[@id='1'] |
<book id="1"> |
[@attributename='value' and @attributename2='value2'] |
多个属性筛选 | book[@id='1' and genre='Fantasy'] |
<book id="1"> |
[position()] |
选取指定位置的节点 | book[position()=1] |
<book id="1"> |
[last()] |
选取最后一个节点 | book[last()] |
<book id="2"> |
text() |
选取当前节点的文本内容 | title/text() |
Harry Potter and the Sorcerer's Stone, The Great Gatsby |
/library/book和//book: 这两个方法都用于选取所有名为 “book” 的直接子节点或后代节点。因为XML中有两个<book>节点,所以两个方法都返回两个<book>节点。
XPath中的斜杠 / 用于指示路径的层次结构,以从根节点到特定节点的方式进行导航,如果直接写
/book,结果会是空列表
-
.: 这个方法用于选取当前节点,即<library>节点。所以结果是整个<library>节点及其子节点。 -
..: 这个方法用于选取当前节点的父节点,但对于根节点<library>来说,它没有父节点,因此结果为空列表。 -
//book[@id="1"]: 这个方法用于选取具有属性id值为 “1” 的<book>节点。因为只有一个符合条件的节点,所以结果是一个包含此节点的列表。 -
book[@id='1' and genre='Fantasy']: 这个方法用于选取具有<genre>子节点内容为 “Fantasy” ,同时id属性为1的<book>节点。因为只有一个符合条件的节点,所以结果是一个包含此节点的列表。 -
//book[position()=1]: 这个方法用于选取第一个<book>节点,根据位置索引来选取。结果是包含第一个<book>节点的列表。 -
//book[last()]: 这个方法用于选取最后一个<book>节点,根据位置索引来选取。结果是包含最后一个<book>节点的列表。 -
//title/text(): 这个方法用于选取所有<title>子节点的文本内容。结果是两个<title>节点的文本内容,即书籍的标题。
3.1.3 Xpath解析起点小说月票榜
先pip安装lxml,然后点击Xpath Helper下载安装Xpath助手插件了。安装完毕后,先固定Xpath Helper图标,使用时点击一下就行。

你也可以先设置快捷键:ctrl+shift+x,使用时按对应快捷键就行。

下面演示一下如何提取起点小说月票排行榜第一页的小说名称和作者。
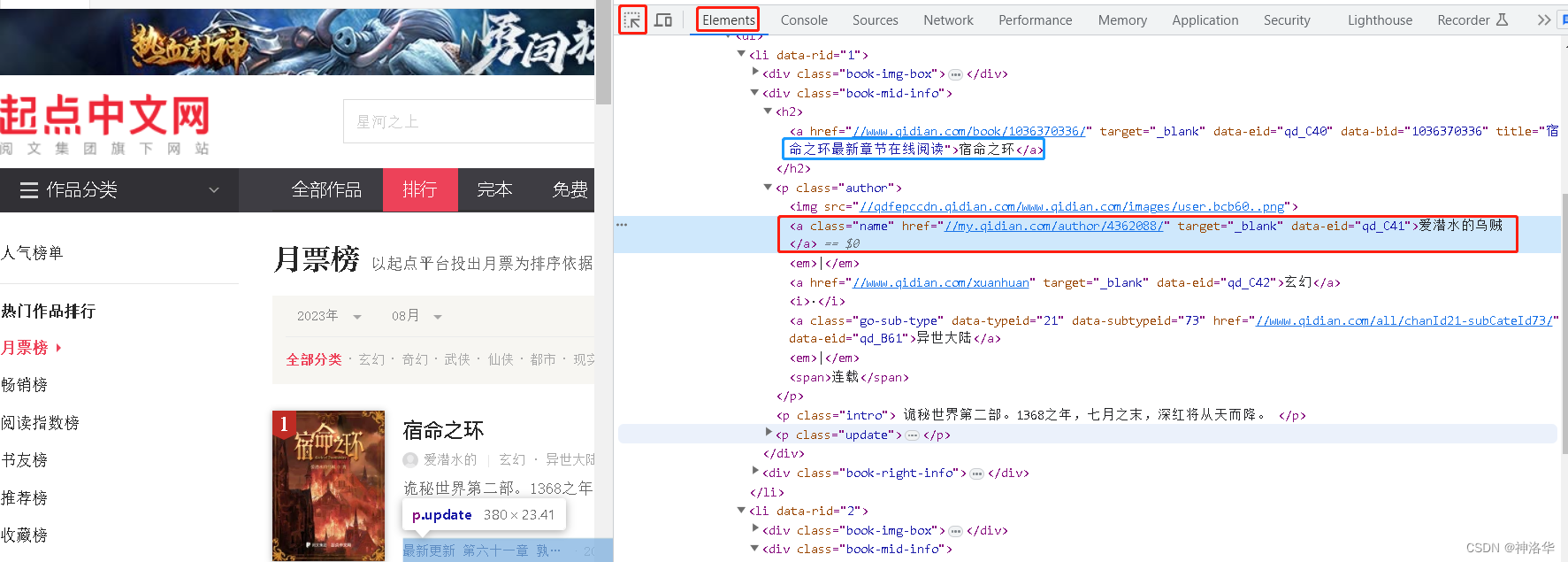
- 打开起点小说月票排行榜https://www.qidian.com/rank/yuepiao/,按F12进入开发者模式,刷新网页
- 点击element标签旁边的选取按钮(选取网页中的元素),点击第一本书作者,就可以跳转到网页源码中的对应位置。
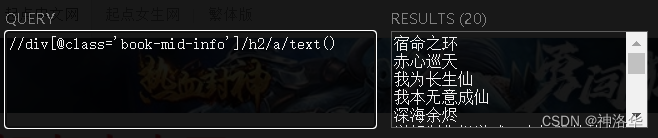
- 输入
//div[@class='book-mid-info']/h2/a/text()就可以提取所有的书名,输入//p[@class='author']/a[@class='name']/text()提取所有的作者。
- 使用爬虫代码获取数据:
import requests
from lxml import etree
# 要爬取的网址
url='https://www.qidian.com/rank/yuepiao/'
# 定义请求头
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'
}
# 发送请求
response=requests.get(url,headers=headers)
data=response.text # 字符串的响应结果
html=etree.HTML(data) # 获取HTML元素对象
# 使用XPath路径表达式提取HTML对象中需要的数据
names=html.xpath('//div[@class="book-mid-info"]/h2/a/text()')
authors=html.xpath('//p[@class="author"]/a[1]/text()')
# 使用zip函数组合输出前5组数据
for name, author in zip(names[:5], authors[:5]):
print(name, ':', author)
宿命之环 : 爱潜水的乌贼
赤心巡天 : 情何以甚
我为长生仙 : 阎ZK
我本无意成仙 : 金色茉莉花
深海余烬 : 远瞳
3.2 BeautifulSoup解析
3.2.1 BeautifulSoup解析器
Beautiful Soup 是一个用于解析 HTML 和 XML 文档的 Python 库。它提供了一种简单而强大的方式来从网页中提取信息,使得我们可以轻松地获取所需的数据。它可以:
- 解析 HTML 和 XML 文档,构建文档树。
- 遍历文档树,搜索和定位特定的标签,提取标签中的文本、属性和其他内容。
- 处理网页中的嵌套结构和复杂布局。
- 处理动态加载的内容,如使用 JavaScript 加载的数据。
安装:
!pip install bs4
BeautifulSoup有几种解析器:
| 解析器名称 | 介绍 | 选择建议 |
|---|---|---|
html.parser |
内置于标准库,解析速度适中,适合大多数简单的 HTML 解析任务。 | 适用于简单的 HTML 解析任务,无需额外安装库。 |
lxml |
解析速度非常快,对大型文档效果显著,支持 HTML 和 XML 解析。具有较好的容错性。 | 适用于大型文档或复杂嵌套结构的解析任务,需要安装 lxml 库。 |
html5lib |
能够处理复杂的嵌套结构和不规范的 HTML,解析准确性高。解析速度较慢,不适合大型文档。 | 适用于处理不规范的 HTML 或复杂结构,适用于较小的文档。需要安装 html5lib 库。 |
3.2.2 Beautiful Soup 提取标签和内容
下面举例说明Beautiful Soup 提取标签和内容的方法,以及相应的示例和结果:
<!DOCTYPE html>
<html>
<head>
<title>示例页面</title>
</head>
<body>
<h1>欢迎使用 Beautiful Soup</h1>
<p>Beautiful Soup 是一个用于解析 HTML 和 XML 文档的 Python 库。</p>
<ul>
<li>简单易用</li>
<li>强大灵活</li>
<li>适用于各种解析任务</li>
</ul>
<a href="https://www.example.com">访问示例网站</a>
</body>
</html>
| 方法 | 作用 | 示例 | 结果 |
|---|---|---|---|
find() |
搜索并返回第一个匹配的标签 | soup.find('h1') |
<h1>欢迎使用 Beautiful Soup</h1> |
find_all() |
搜索并返回所有匹配的标签列表 | soup.find_all('li') |
列表包含所有 <li> 标签 |
.text |
提取标签中的文本内容 | soup.find('h1').text |
欢迎使用 Beautiful Soup |
.get('属性名') |
获取标签的属性值 | soup.find('a').get('href') |
https://www.example.com |
3.2.3 Beautiful Soup解析起点小说月票榜
import requests
from bs4 import BeautifulSoup
url='https://www.qidian.com/rank/yuepiao/'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'
}
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.text,'lxml')
# 查找所有的div标签
div_tag=soup.find_all('div',class_='book-mid-info')
# 遍历所有的div标签
for div in div_tag[:5]:
h2_tag=div.find('h2') # 从div标签中获取第一个h2
a_tag=h2_tag.find('a') # 从h2标签中提取第一个a标签
p_tag=div.find('p',class_='author') # 从div中提取第一个名称为author 的p标签
author_a_tag=p_tag.find('a') #从p标签中提取第一个a标签
print(a_tag.text,':',author_a_tag.text)
宿命之环 : 爱潜水的乌贼
赤心巡天 : 情何以甚
我为长生仙 : 阎ZK
我本无意成仙 : 金色茉莉花
深海余烬 : 远瞳
3.2.3 CSS 选择器与 Beautiful Soup
CSS 选择器是一种用于选择 HTML 元素的强大工具,它可以帮助您通过元素的标签、类、ID 和其他属性来定位和选择元素。在 Beautiful Soup 中,您可以利用 CSS 选择器来精确地找到您感兴趣的内容。
- 标签选择器: 使用标签名称来选择特定类型的元素。例如,选择所有的
<a>标签可以使用a。 - 类选择器: 使用类名来选择具有特定类的元素。例如,选择所有具有
class="header"的元素可以使用.header。 - ID 选择器: 使用 ID 来选择具有特定 ID 的元素。例如,选择具有
id="content"的元素可以使用#content。 - 后代选择器: 选择某个元素的后代元素。例如,选择所有在
<div>中的<p>元素可以使用div p。
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
# 使用标签选择器选择<h1>元素
h1_element = soup.select('h1')
print("使用标签选择器选择<h1>元素:", h1_element[0].text)
# 使用类选择器选择<p>元素
p_element = soup.select('p')
print("使用类选择器选择<p>元素:", p_element[0].text)
# 使用后代选择器选择<li>元素
li_elements = soup.select('ul li')
print("使用后代选择器选择<li>元素:")
for li in li_elements:
print(li.text)
# 使用属性选择器选择<a>元素的href属性值
a_element = soup.select_one('a[href]')
print("使用属性选择器选择<a>元素的href属性值:", a_element['href'])
使用标签选择器选择<h1>元素: 欢迎使用 Beautiful Soup
使用类选择器选择<p>元素: Beautiful Soup 是一个用于解析 HTML 和 XML 文档的 Python 库。
使用后代选择器选择<li>元素:
简单易用
强大灵活
适用于各种解析任务
使用属性选择器选择<a>元素的href属性值: https://www.example.com
select_one用于查找并返回文档中符合条件的第一个元素,select用于查找并返回所有符合条件的元素。