一. 反向传播算法
1. BP算法自然语言描述
概念:梯度下降是利用损失函数的梯度,来决定最终的下降方向。反向传播算法是计算复杂梯度的方式。数学原理就是链式法则。
梯度向量中每一项,不光告诉我们每个参数增加还是缩小。并且指出了每个参数的“性价比”

我们从单样本训练进行观察。
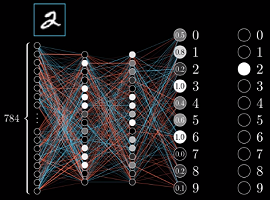
输入的特征为784个,两层隐藏层,输出层为类别,10个节点。输出的目标为识别为2,我们看到输出层的激活值因为网络还没有训练好,值非常的随机。我们都是希望正确分类的激活值应该最大,其他的接近于0.。而激活值是由输入值和权重来决定的。第一次训练的时候权重和偏置都是随机设置的,那如何进行更改?
我们最简单的方式去考虑,激活值变动,应该和当前的目标值之间的误差成正比。目前2的激活值为0.2,距离输出值1差距很大,而8的激活值为0.2,距离输出值0差距很小。所以增加2的激活值要比8更大一些。
输出分类为2的激活函数如下图所示
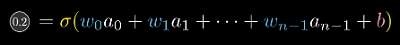
根据式子我们可以看出,增大权重、增大偏置、调整上一层的激活值。可以增加当前的激活值。
1) 如何调整权重和偏置?
(1) 因为偏置没有输入,只作用与当前的神经元,所以可以正比当前值和目标值之间的差来进行调整。
(2) 权重作用于上一层神经元和下一层神经元之间的连线,反应了连接的强弱,所以上层的激活值越大,那权重对当前的神经元激活值的影响就是巨大的。所以应该正比于关联的上层激活值调整参数。
2) 如何改变上层的激活值?
(1) 因为权重带有正负,而激活函数如果是sigmoid和ReLU函数,那么激活值一定是大于等于0的,所以想要增加当前的激活值,应该使正权连接的上层激活值增加,负权连接的上层函数激活值减少。
(2) 上层激活值的大小也是有上层的权重和偏置还有激活值决定。
2. 反向传播
1) 通过上面我们理解到,改变输出神经元的激活值,需要改变上层的神经元激活值已经权重和偏置,但是在单样本训练的过程中,出了增加正确的神经元激活值,还要降低错误的神经元激活值,其他输出神经元也会改变上层的参数值,因此,要将这些神经元的期待全部求和,作为最终的改变上层神经元参数的指示。
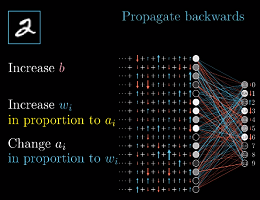
2) 综合来说,反向传播的理解就是这样,将所有的期待改变相加,得到对上层改动的变化量,重复这个过程直到第一层。
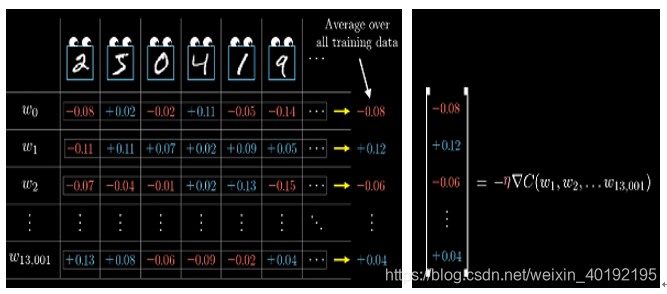
3) 实际训练中,是需要同时考虑每个样本对权重与偏置的修改,然后对他们的期望进行平均,作为每个参数的变化量。最终得到的向量就是梯度下降中的负梯度。η 表示倍数。
3. BP算法总结
1) 反向传播算法计算的是单个训练样本对所有权重和偏置的调整,包括每个参数的正负变化和变化的比例。可以最快的降低损失。
2) 梯度下降需要对训练集中的每个样本都要进行反省传播,计算说有的平均变化值,然后进行更新。这样做的缺点是会使算法的复杂度和训练样本的数量相关。
3) 所以最终我们实践时,会使用随机梯度下降。
(1) 首先是将训练样本打乱
(2) 然后将所有样本分发到mini-batch中,mini-batch的大小自己决定
(3) 计算每个mini-batch的梯度,调整参数
(4) 直到达到某个阈值,或者loss值不再改变
神经网络最终将会收敛到某个局部最小值上
PS:下一篇将讲解BP算法数学原理
参考:https://github.com/imhuay/Algorithm_Interview_Notes-Chinese/blob/master/A-深度学习/A-深度学习基础.md