大语言模型(LLM,Large Language Model)是指能够处理海量数据、拥有百亿级参数的深度学习模型,它已成为⼈⼯智能领域中的新热点。2022 年 11 ⽉ 30 号 ChatGPT 发布,其卓越的性能表现给整个⾏业带来了巨⼤的冲击。⼈们不再排斥⼤模型的笨重难以部署,⽽纷纷惊叹其惊艳的表现。ChatGPT无疑引发了⼀轮新的对大语言模型的关注,也促使⼈们对大语言模型能力进行重新思考。
一、大语言模型的发展脉络
目前新的大语言模型绝⼤部分都是使⽤ GPT 所采⽤的 Autoregressive 模型,它本质上就是⼀个文字接龙或者自动补充模型,包括 Google 的 PaLM、LaMDA,还有开源的Facebook(Meta)的 OPT 以及 BigScience 的 BLOOM 等。随着技术的发展⼤模型也层出不穷,下图是我们收集的大模型(LLM)发展脉络:
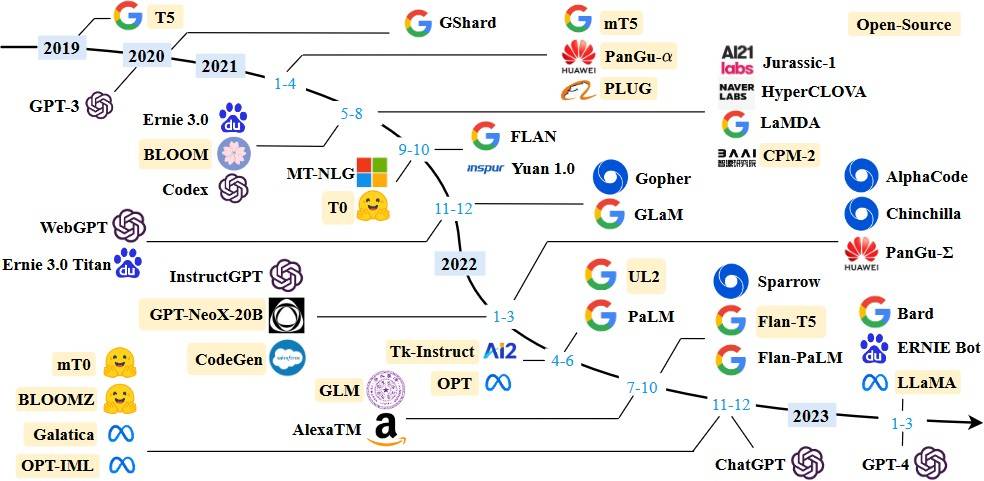
⼆、开源类ChatGPT模型在信息抽取领域的实测对比
ChatGPT 这类大语言模型出色的表现得益于Instruction Tuning,即通过人工标注大量自然语⾔形式的指令和答案对来进⾏有监督的学习,其可以极大提升模型对用户意图的理解能⼒,同时也能提升模型应对全新任务的泛化能力。具体的ChatGPT 为代表的 LLM 的特点可以总结为如下⼏点:
(1)强⼤的自然语言理解能力(NLU),以 ChatGPT 代表的这类⼤语⾔模型语⾔理解能⼒⾮常强,它能精确的理解⽤户意图对于其中的细节意图也能精准把控,⽣成的回答语言也流畅。
(2)涌现能力( Emergent Abilities)这是随着模型规模不断增⼤到达某个临界点后,模型能⼒会完成从量变到质变的⻜跃,呈现出惊⼈的爆发式增⻓。⽐如 In-Context Learning,⽆需微调只需要输⼊合适的prompt便可以实现惊⼈的zero-shot或few-shot的能力。再如思维链(Chain of Thoughs)能⼒,即链式思维推理,其也是⼤模型能够拥有拟⼈化对话能⼒的关键。
(3)⽂本⽣成能力(Text Generation),以ChatGPT为代表的这类LLM拥有出色的文本生成能力,它能根据用户生成不同格式要求的回答。
鉴于大模型出色的能力,我们选取了⽬前开源的ChatGLM和MOSS⼤模型并结合我司业务场景进行了测试,具体效果如下:
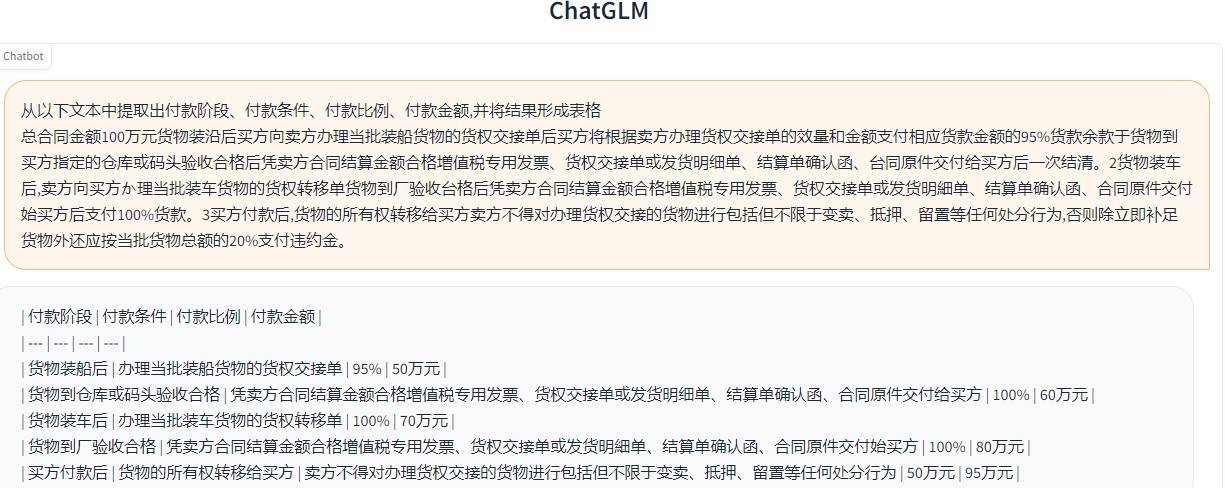
(1)尝试从合同⽂本中抽取“付款阶段”,“付款条件”,“付款⽐例”,“付款⾦额”字段信息。


(2)从表格(表格转成HTML格式)中的“采购人”,“供应商”,“共同⾦额”,“合同期限”,“合同签署时间”字段信息。
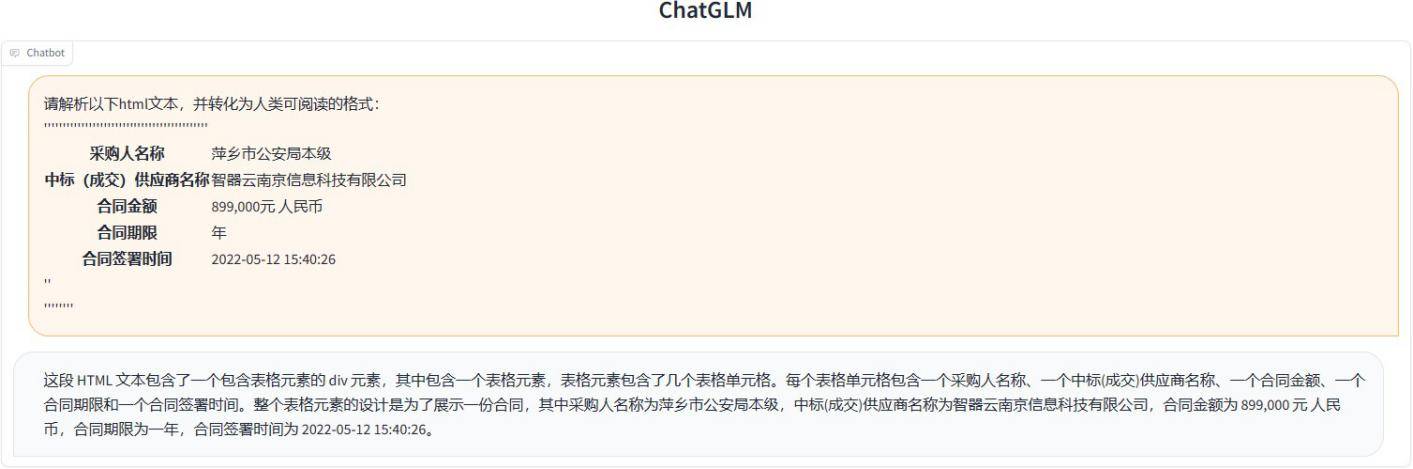

经过以上两个场景的模型测试,我们发现ChatGLM的效果明显优于MOSS,ChatGLM能跟准确的理解⽤户意图并能给较为准确的答案。相⽐之下MOSS的160亿参数规模⼏乎是ChatGLM(62亿参数)的三倍但信息抽取任务上的效果却不及ChatGLM。这⾥的原因主要是ChatGLM训练的任务中本⾝就有与信息抽取相贴合场景,⽽MOSS更擅⻓数学计算和图片生成相关的任务。因此才出现参数规模更⼤MOSS 效果反⽽不及规模较小的ChatGLM的情况。
三、类ChatGPT模型在垂直领域落地的思考
以ChatGPT为代表的大模型之所以效果惊艳,是因为背后有大规模的算力和众多Instruction Tuning 专业标注作为⽀撑。其中 Instruction Tuning 标注需要大量领域内的专业人员参与才行,成本也非常高。对于 LLM 来说,除了大算力之外,高质量的数据也⾮常重要,这也是为什么往往只有⼤公司才能负担从头开始训练⼤模型的原因之⼀。对于没有大规模算力和众多领域内的专业人员做标注的团队,使用开源的百亿级大模型(LLM)做垂域微调或许是个不错的选择。