scrapy 连接mysql数据库,进行数据的存储
爬虫抓取到的数据我们需要将其存储起来以备后来使用,我们常用的保存方式为数据库存储,mysql数据库使我们最常用的关系型数据库。今天我们就看看如何将scrapy抓取到的数据保存到mysql数据库。
用到的模块:pymysql python连接操作mysql数据库的基本模块
Twisted 异步存储模块,上篇博文中有介绍其安装方法
步骤1:在settings中进行数据库的基本配置添加,如下:

如上图,配置中添加mysql的host,数据库名DB,用户名user,密码password,端口port,编码charset等,数据库连接的必要参数即可

配置完数据库参数后,同时在setting中将项目的管道设置释放,注意此处的obb是爬虫项目名
步骤2:在items中定义自己的数据库模型,以供之后scrapy操作时对应数据库进行插入操作,如下:

我的数据表有七个字段,我就在这里定义七个字段进行对应
步骤3:编写自己的pipelines文件,在这个文件中应用pymysql和Twisted两个模块对数据库的数据存储进行实际的操作。如下:
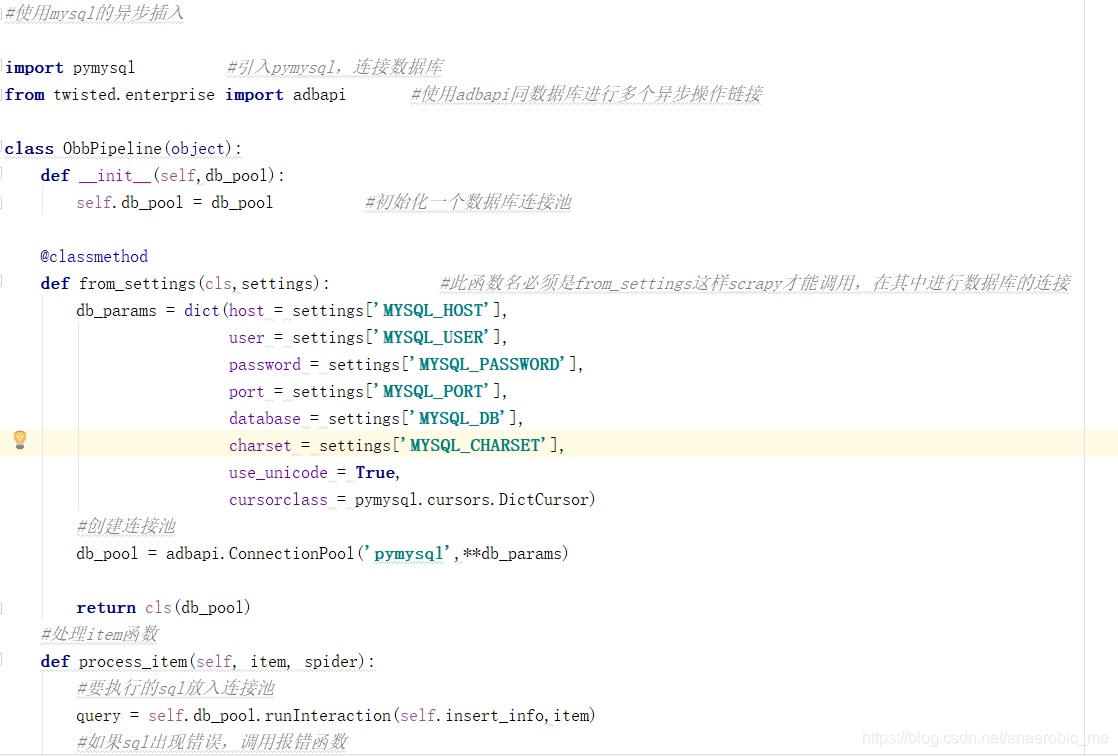

以上是pipelines中的管道操作数据库函数,已经注释了每一行的作用
步骤4:在自己的爬虫中调用items中的类即第二步中的类名,通过字典的形式将自己从网页中抓取的数据传入存储。如下

每一个名字都对应item中的名称,这样才能保证不会出错。
接着运行自己的爬虫:scrapy crawl 爬虫名
这样既可将主渠道的数据异步存储到mysql数据库中。