此原生爬虫项目旨在爬取直播平台(本项目以pandaTV为例)上某分类(本项目为Dota2)的主播人气,进行排行、得出排行榜。
首先对爬虫的框架进行分析,得到以下思维导图:
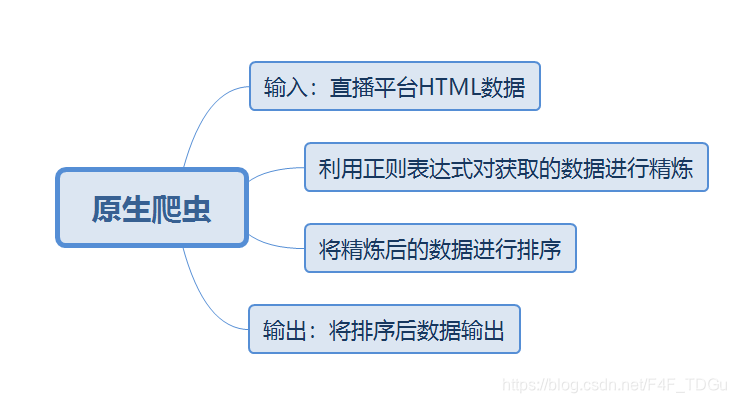
从思维导图中可以得到该爬虫应该实现的四个基本功能:
1)从直播平台获取HTML数据
2)对获取的数据进行精炼
3)将精炼后的数据进行排序
4)将排序后的结果输出
基本功能确定后,将爬虫的基本框架搭建如下:
class Spider():
html = 'null'
data = 'null'
rank = []
def __get_html(self):
Spider.html = get_html()
def __refine_data(self,data):
Spider.data = refine_data(data)
def __sort_data(self,data):
Spider.rank = sort(data)
def __show_rank(self,data):
show_rank(data)
def get_rank(self):
self.__get_html()
self.__refine_data(Spider.html)
self.__sort_data(Spider.data)
self.__show_rank(Spider.rank)
Spider类中的四个私有函数即对应了此爬虫应实现的四个功能,接下来对这四个功能进行具体的实现:
1.获取HTML数据
from urllib import request
import gzip
#panda dota2网址
url_dota2 = 'https://www.panda.tv/cate/dota2?pdt=1.24.s1.16.7ko54c8j1cb'
#panda lol网址
url_lol ='https://www.panda.tv/cate/lol?pdt=1.24.s1.3.7ti3ad20q0c'
url = url_dota2
#如果接收到的html数据为gzip类型,则进行解压
def ungzip(data):
try:
data = gzip.decompress(data)
except:
pass
return data
def get_html():
user_agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0'
headers = {'User-Agent':user_agent}
page = request.Request(url,headers=headers)
r = request.urlopen(page)
#获得字节码类型的html数据
# html = r.read()
html = ungzip(r.read())
#转换成str类型
html = str(html,encoding = 'utf-8')
return html
#以下代码为调试模块功能是否实现
if __name__ == '__main__':
test = get_html()
print(test)
2.对获取的数据进行精炼
import re
douyu = '<div class="DyListCover-info">([\s\S]*?)<\div>'
panda = '<div class="video-info">([\s\S]*?)</div>'
panda_name = '<span class="video-nickname" title="([\s\S]*?)">'
panda_hot = '<span class="video-number"><i class="ricon ricon-eye"></i>([\s\S]*?)</span>'
def refine_data(data):
r = re.findall(panda,data)
data_refined = []
for i in r:
name = re.findall(panda_name,i)[0]
hot = re.findall(panda_hot,i)[0]
#有部分高人气主播的人气达到万人级别,故需要转换
if '万' in hot:
hot = float(re.sub('万','',hot)) * 10000
result = {'name':name,'hot':int(hot)}
data_refined.append(result)
return data_refined
3.将精炼后的数据进行排序
def sort_rule(data):
return data['hot']
def sort(data):
sorted_data = sorted(data,key = sort_rule,reverse = True)
return sorted_data
4.将排序后的结果输出
def show_rank(data):
l = len(data)
for i in range(l):
print('排名' + str(i + 1)
+ ': ' + data[i]['name']
+ ' 人气: '
+ str(data[i]['hot']) )
四个基本功能实现后,调用爬虫对pandaTV中的dota2分类进行爬取,得到以下结果:
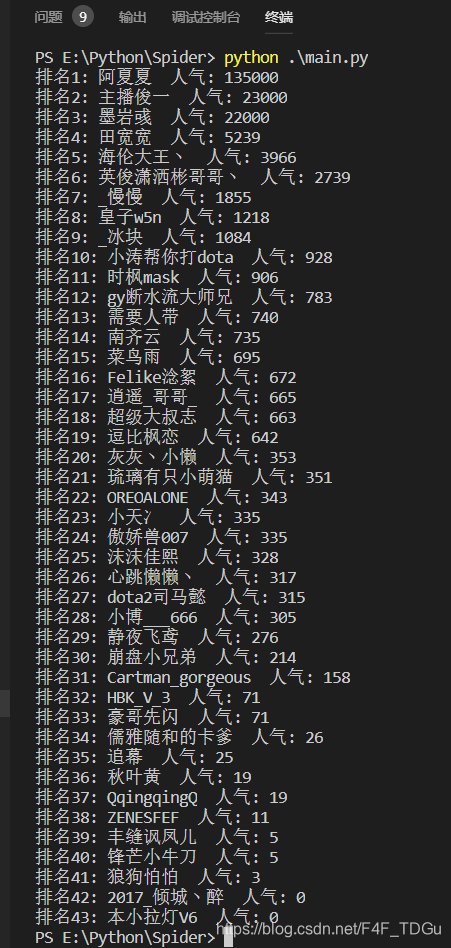
可以看到该爬虫的基本功能均已实现!
PS:此项目源码储存于我的github,网址为https://github.com/TDGyou/Spider_raw