python某鱼主播粉丝的爬取
找到粉丝数据是如何传过来的
随机找一个主播的直播间打开,本人使用的是chrome控制台,定位粉丝html的标签位置。但这里定位后会发现页面展示的数据和html中展示的数据是不对的。这个时候能想到的是该数据应该是做了字体反爬。
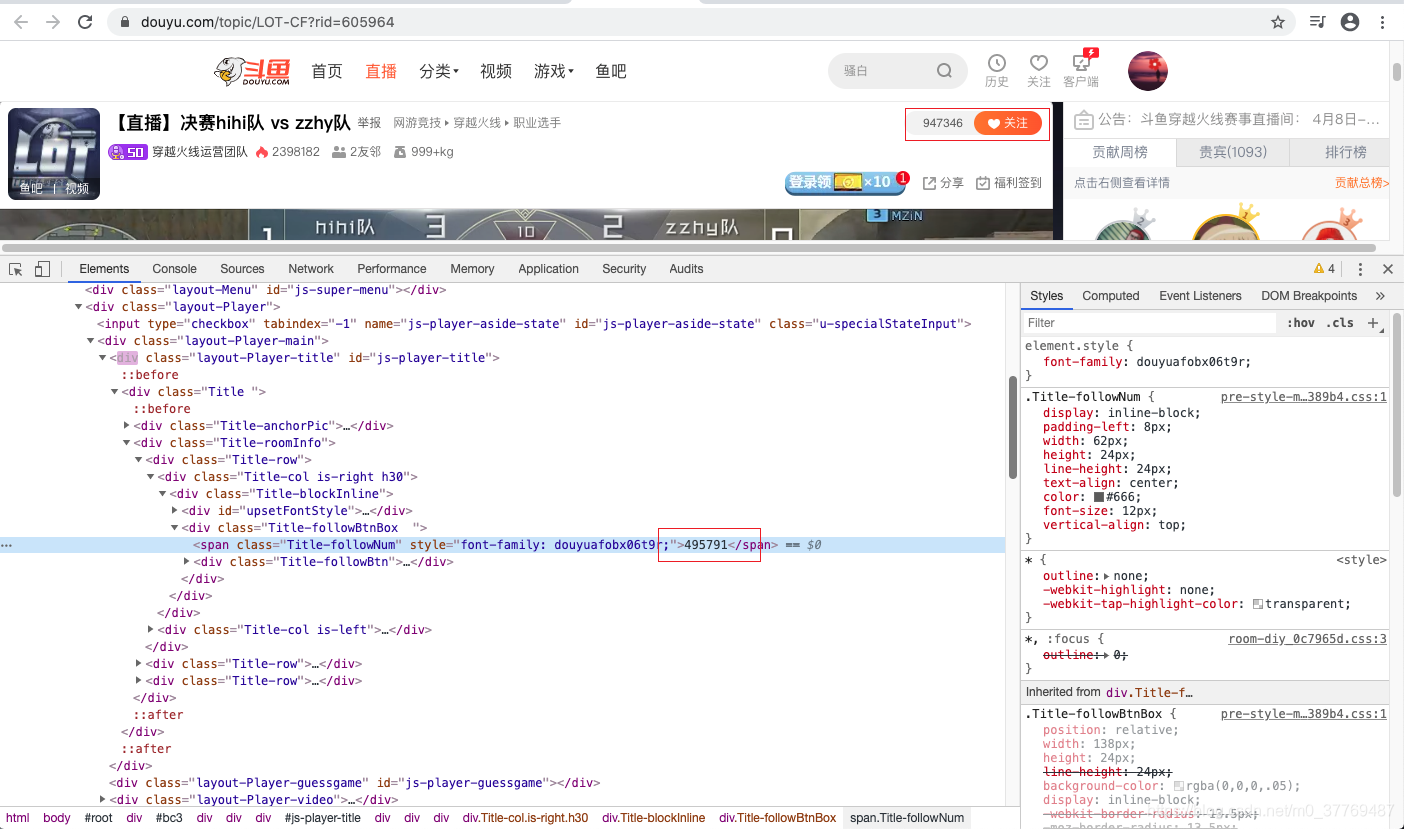
再细心点会发现它标签中用到的属性style,后面跟上的字符传应该是调用对应字体库的链接中的某个参数。
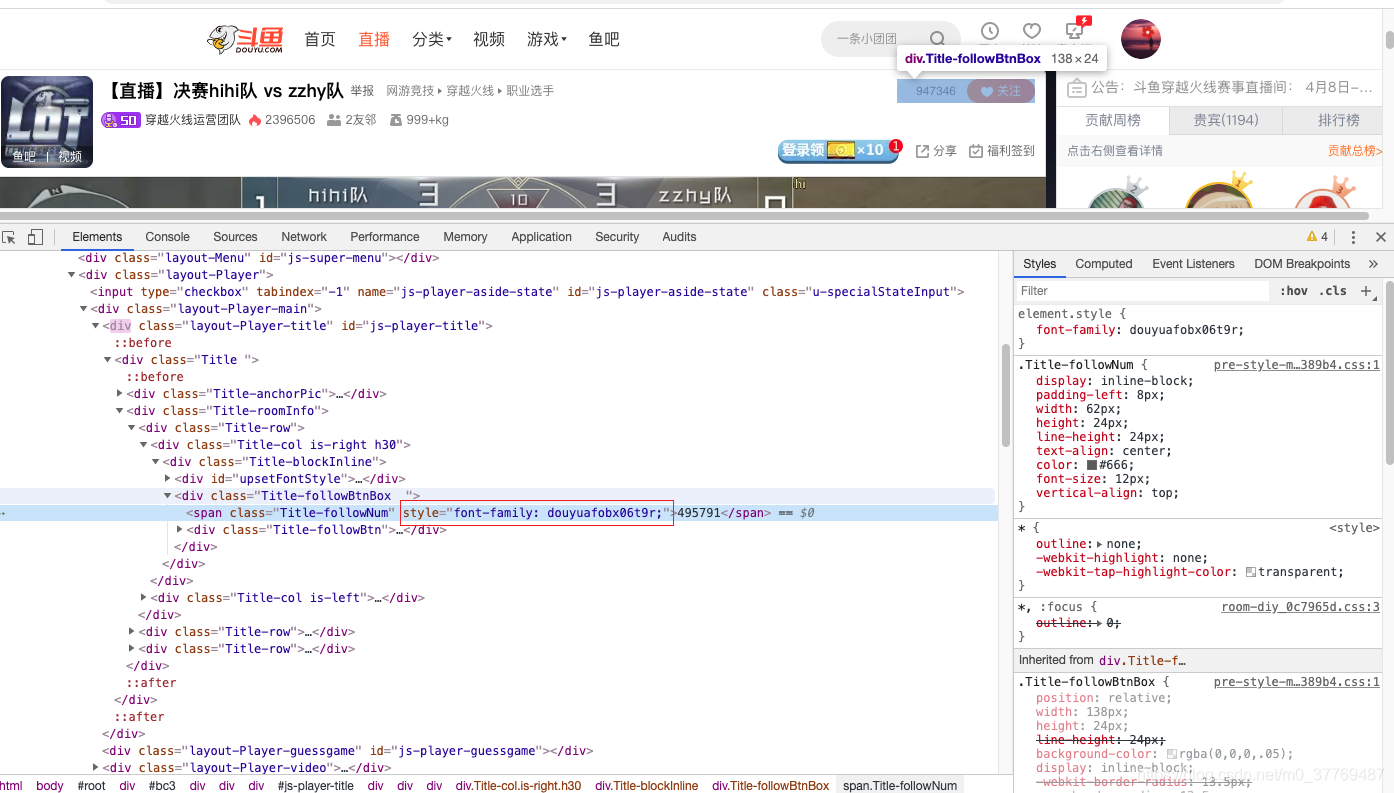
找到调用的字体库
把第一步上字体库的url参数通过全局搜索,会发现它存在于一个长链接中,再细看长链接,有两个参数cfdc和ci这两个参数,其中cfdc对应的数据是粉丝数量需要经过字体库的映射一下关系,则是对应才是正确的粉丝数量,ci这个参数是对应的字体库的链接的参数
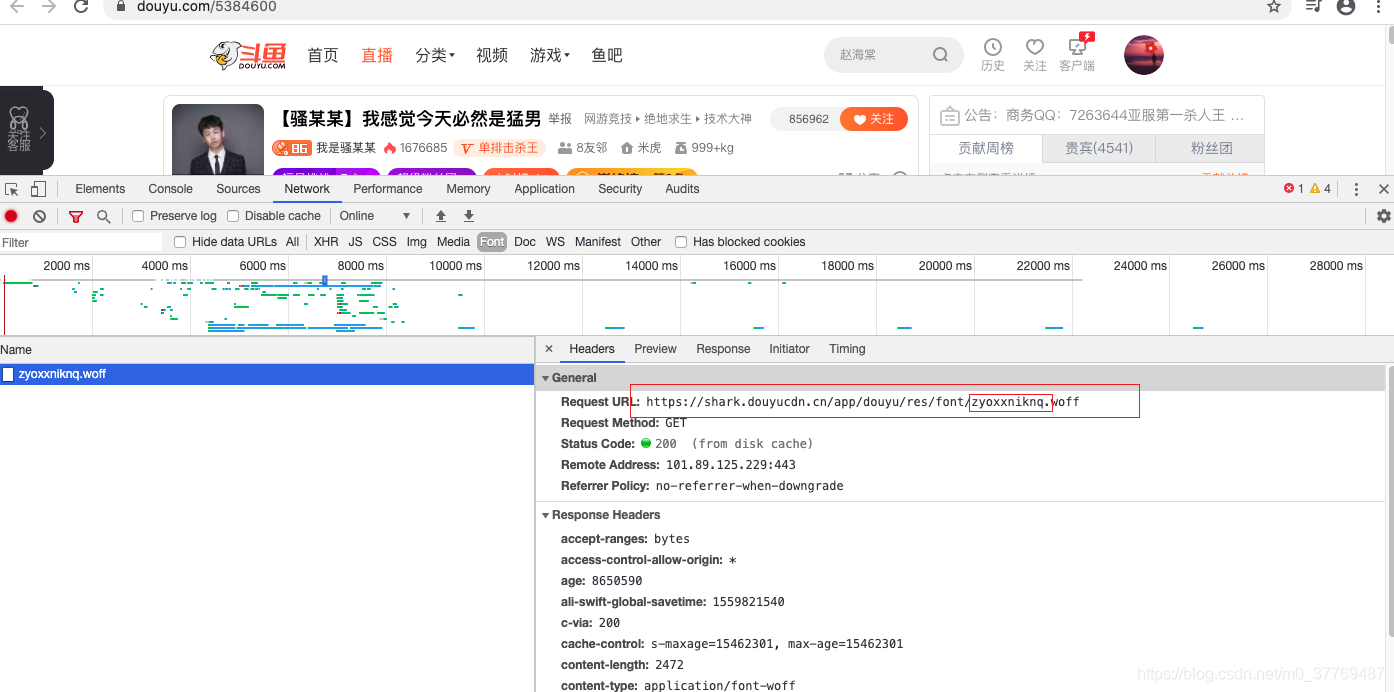
但是多刷新几次,会发现每次调用的字体库是不一样的,所以这里不能写死。要根据长链接返回的字体库参数拼接链接。才能获取到每次调用的字体库的链接。
解析字体库,找到对应关系
把每次获取到的字体库链接直接通过requests下载下来,保存为woff格式。然后转成lxml格式。打开lxml,很清楚的能看见里面对应的关系。然后通过python解析lxml对数据进行解析,获取到对应的映射关系即可。
附上解析字体的代码:
import requests
from fontTools.ttLib import TTFont
from xml.dom.minidom import parse
headers = {
'user_agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36',
}
def get_number_dict(keyword):
number_dict = {
'zero': 0,
'seven': 7,
'three': 3,
'four': 4,
'eight': 8,
'six': 6,
'five': 5,
'nine': 9,
'one': 1,
'two': 2,
}
dom = parse("lxml路径")
# dom = parse("/Users/zhulang/Desktop/nanodata_crawling/apps/douyu/woff/%s.xml" % str(keyword))
data = dom.documentElement
stus = data.getElementsByTagName('GlyphID')
font_dict = {
}
corr_number = []
error_number = []
for stu in stus:
corr_number.append(stu.getAttribute('id'))
if stu.getAttribute('name') != '.notdef':
error_number.append(number_dict[stu.getAttribute('name')])
else:
pass
corr_number = corr_number[:-1]
for index in range(len(corr_number)):
font_dict[error_number[index]] = corr_number[index]
return font_dict
def download_font(keyword):
url = 'https://shark.douyucdn.cn/app/douyu/res/font/%s.woff' % str(keyword)
res = requests.get(url, headers=headers)
with open("woff字体路径", 'wb') as f:
f.write(res.content)
base_font = TTFont("woff字体路径" )
base_font.saveXML("lxml路径")
number_dict = get_number_dict(keyword)
return number_dict
调试粉丝长链接
这里提供大概的一个思路吧,先是通过刚刚上一步长链接里面返回的参数,用参数在控制台中做一个全局的搜索。再一步一步的从每个js文件里面去调试。最后会看到一个socket.sendMessage()这样一个方法,里面发送的数据就是套接字的数据。但是要注意的是这里面有写是验证型的数据,需要自己通过查看js代码去找到该数据的生成方式。这里面就有vk@=和rt@=这两个参数。其中vk这个参数是根据套接字里面的devid与他们给的特定的一串字符加上当前时间戳做的一个字符串的拼接,再转为md5,rt就是当前时间戳。
上面两个问题解决后,会发现链接长链接一段时间后,该长链接会封ip,所以再在链接长链接时加上自己的ip代理即可。
附上完整代码
import datetime
import re
import hashlib
import traceback
import websocket
import download_font
import get_proxy
try:
import thread
except ImportError:
import _thread as thread
import time
class getLiveRoomFans(object):
def __init__(self):
self.headers = {
'user_agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36',
}
def on_message(self, ws, message):
message1 = message.decode('utf8', 'ignore')
if re.search('type@=followed_count', message1):
pattern_fans = re.compile('cfdc@=(.+?)/')
fans = re.findall(pattern_fans, message1)[0]
pattern_font = re.compile('/ci@=(.+?)/')
ci = re.findall(pattern_font, message1)[0]
change_fans = download_font(ci)
number_fans = ''
fans_info = {
}
for i in str(fans):
fans = change_fans[int(i)]
number_fans += fans
fans_info['room_id'] = self.room_id
fans_info['fans_number'] = int(number_fans)
ws.close()
else:
pass
def on_error(self, ws, error):
print(error)
def on_close(self, ws):
print("### closed ###")
def on_open(self, ws):
def run(room_id):
rt = int(time.time())
p = "d248f56d14dda7efa3e2237200051501"
a = "r5*^5;}2#${XF[h+;'./.Q'1;,-]f'p["
vk = str(rt) + a + p
m2 = hashlib.md5()
m2.update(vk.encode('utf-8'))
login = 'type@=loginreq/roomid@=' + str(room_id) + '/dfl@=sn@AA=105@ASss@AA=1/username@=330225743/password@=/ltkid@=77344183/biz@=1/stk@=842a1e8ff5863b28/devid@=d248f56d14dda7efa3e2237200051501/ct@=0/pt@=2/cvr@=0/tvr@=7/apd@=/rt@=' + str(
rt) + '/vk@=' + str(m2.hexdigest()) + '/ver@=20190610/aver@=218101901/dmbt@=chrome/dmbv@=81/\0'
login_encode = login.encode('utf-8')
data_length = len(login_encode) + 8
infohead = int.to_bytes(data_length, 4, 'little') + int.to_bytes(data_length, 4, 'little') + int.to_bytes(689, 4,'little')
ws.send(infohead+login_encode)
join_group = 'type@=h5gkcreq/rid@=' + str(room_id) + '/ti@=' + '2201' + str(
datetime.datetime.now().strftime('%Y%m%d')) + '/\0'
info = join_group.encode('utf-8')
data_length = len(info) + 8
value = 689
infohead = int.to_bytes(data_length, 4, 'little') + int.to_bytes(data_length, 4, 'little') \
+ int.to_bytes(value, 4, 'little')
data = infohead + info
ws.send(data)
thread.start_new_thread(run, (self.room_id,))
def run(self, i):
self.room_id = i
websocket.enableTrace(True)
ws = websocket.WebSocketApp("wss://wsproxy.douyu.com:6673/",
on_message=self.on_message,
on_error=self.on_error,
on_close=self.on_close)
ws.on_open = self.on_open
ws.run_forever(http_proxy_host='代理IP',http_proxy_port='代理端口')
后续会跟上斗鱼直播间信息爬取。
注:
此博客纯手工,如有和其他博主的博客雷同,请麻烦联系一下我。