requests+bs4+xlwt模块–简单爬虫实例–小说排行榜目录–笔趣阁篇
爬取小说内容文章链接:传送门
文章目录
section1:声明
1、本文爬取内容均为用户可以免费查看内容。
2、本文为自己的学习笔记,不会用于商用。
3、本文如有侵权,请联系我删除文章!!!
section2:内容爬取分析:
既然是要爬取排行榜,进行数据筛选,肯定少不了多页爬取。那我们就先来看看,每一页的URL有什么变化,有时候规律可循。


通过比较,我们可以很快发现规律,之后在这个地方使用放循环即可
for i in range(1, 5): # 根据想要爬的页数而改动
url = 'https://www.52bqg.net/top/allvisit/{}.html'.format(i+1)
然后就是对一个页面进行检查分析啦。
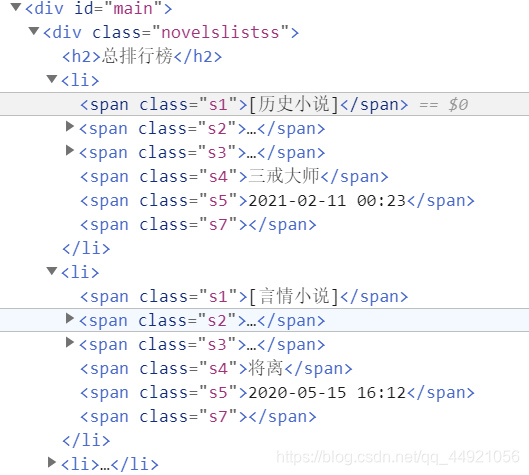
规律也是很明显的,一个li节点对应一篇小说的目录内容,使用bs4,很容易就能对内容进行提取。
提取内容之后,就是对内容的保存,利用xlwt模块,把内容导入到excel中,这里我直接放一下代码:
list_all = list()
path = 'D:/笔趣阁目录.xls'
workbook = xlwt.Workbook(encoding='utf-8', style_compression=0)
worksheet = workbook.add_sheet('小说目录', cell_overwrite_ok=True) # 可覆盖 # 设置工作表名
col = ('小说类型', '小说名', '最新章节', '作者', '最新更新时间')
for i in range(0, 5):
worksheet.write(0, i, col[i]) # 设置列名
for i in range(1, 5): # 根据想要爬的页数而改动
url = 'https://www.52bqg.net/top/allvisit/{}.html'.format(i)
data_list = get_content(url)
list_all.append([data_list])
for i in range(len(list_all)): # i=0~1
sleep(0.5) # 延迟0.5秒)
print('正在下载第{}页目录=====> 请稍后'.format(i+1))
data_s = list_all[i]
for j in range(len(data_s)): # j=0
data = data_s[j]
for k in range(len(data)): # k=0~49
data_simple = data[k]
for m in range(0, 5): # m=0~4
worksheet.write(1 + i * 50 + k, m, data_simple[m])
workbook.save(path)
(我也是因为这个实例,刚学的xlwt,我把我参考的文章放在后面。)
section3:完整代码
import requests
import bs4
import xlwt
from time import sleep
headers = {
'user - agent': 'Mozilla / 5.0(WindowsNT10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 80.0.3987.116Safari / 537.36'
}
def get_content(url):
res = requests.get(url=url, headers=headers)
html = res.text
soup = bs4.BeautifulSoup(html, 'html.parser')
soup = soup.select('.novelslistss li')
list_all = []
for novel in soup[0: 50]:
novel_type = novel.select('.s1')[0].string
novel_name = novel.select('.s2 a')[0].string
latest_chapters = novel.select('.s3 a')[0].string
author = novel.select('.s4')[0].string
update_time = novel.select('.s5')[0].string
list_all.append([novel_type, novel_name, latest_chapters, author, update_time])
return list_all
def main():
list_all = list()
path = 'D:/笔趣阁目录.xls'
workbook = xlwt.Workbook(encoding='utf-8', style_compression=0)
worksheet = workbook.add_sheet('小说目录', cell_overwrite_ok=True) # 可覆盖 # 设置工作表名
col = ('小说类型', '小说名', '最新章节', '作者', '最新更新时间')
for i in range(0, 5):
worksheet.write(0, i, col[i]) # 设置列名
for i in range(1, 5): # 根据想要爬的页数而改动
url = 'https://www.52bqg.net/top/allvisit/{}.html'.format(i)
data_list = get_content(url)
list_all.append([data_list])
for i in range(len(list_all)): # i=0~1
sleep(0.5) # 延迟0.5秒)
print('正在下载第{}页目录=====> 请稍后'.format(i+1))
data_s = list_all[i]
for j in range(len(data_s)): # j=0
data = data_s[j]
for k in range(len(data)): # k=0~49
data_simple = data[k]
for m in range(0, 5): # m=0~4
worksheet.write(1 + i * 50 + k, m, data_simple[m])
workbook.save(path)
print('所检索所有页面目录=======> 全部保存成功!'.format(i))
if __name__ == '__main__':
main()
section4:运行结果
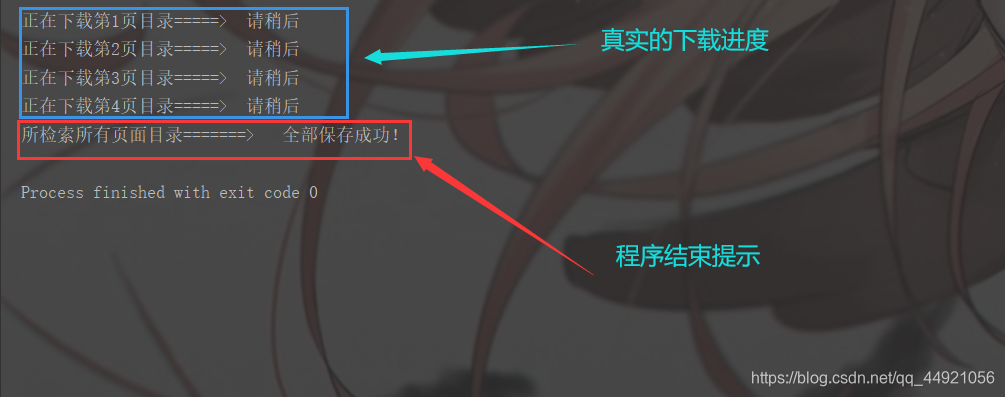

可以利用筛选功能,多条件筛选心仪的小说!
section5:参考文章及学习链接
1、Python模块xlwt对excel进行写入操作
参考文章:点此此处传送
2、爬取软科中国最好大学排名(实例)
参考文章:点击此处获取