本系列来总结Pytorch训练中的模型结构一些内容,包括模型定义,模型参数初始化,模型保存与加载等
上篇博文简述了模型定义,严格来说,模型参数初始化也是模型构造的一部分,但其又有其特殊性和篇幅,所以我单独列出来
深度网络中参数初始化一度是一个热点和难点,在DL发展早期,研究者们对参数初始化方法研究不可谓不多;发展到今,因为网络结构的优化,训练的优化,初始化方法的日趋成熟,参数初始化已渐进成熟。以至我们(至少我)都很少关注这个方向,只是拿来用就可以了,但它在模型训练中还是很重要的;当然本文也不会去深入初始化原理,只在总结Pytorch中初始化方法
1 模型初始化–Pytorch
源码链接
1)均匀分布
def uniform_(tensor, a=0, b=1):
r"""Fills the input Tensor with values drawn from the uniform
distribution :math:`\mathcal{U}(a, b)`.
Args:
tensor: an n-dimensional `torch.Tensor`
a: the lower bound of the uniform distribution
b: the upper bound of the uniform distribution
tensor - n维的torch.Tensor
a - 均匀分布的下界
b - 均匀分布的上界
Examples:
>>> w = torch.empty(3, 5)
>>> nn.init.uniform_(w) 从均匀分布U(a, b)中生成值,填充输入的张量或变量w
"""
with torch.no_grad():
return tensor.uniform_(a, b)
2)正太分布
def normal_(tensor, mean=0, std=1):
r"""Fills the input Tensor with values drawn from the normal
distribution :math:`\mathcal{N}(\text{mean}, \text{std})`.
Args:
tensor: an n-dimensional `torch.Tensor`
mean: the mean of the normal distribution 正态分布的均值
std: the standard deviation of the normal distribution 正态分布的标准差
Examples:
>>> w = torch.empty(3, 5)
>>> nn.init.normal_(w)
"""
with torch.no_grad():
return tensor.normal_(mean, std)
3)常量
def constant_(tensor, val):
r"""Fills the input Tensor with the value :math:`\text{val}`.
Args:
tensor: an n-dimensional `torch.Tensor`
val: the value to fill the tensor with
Examples:
>>> w = torch.empty(3, 5)
>>> nn.init.constant_(w, 0.3)
"""
with torch.no_grad():
return tensor.fill_(val)
4)1填充
def ones_(tensor):
r"""Fills the input Tensor with ones`.
Args:
tensor: an n-dimensional `torch.Tensor`
Examples:
>>> w = torch.empty(3, 5)
>>> nn.init.ones_(w)
"""
with torch.no_grad():
return tensor.fill_(1)
5)0填充
def zeros_(tensor):
r"""Fills the input Tensor with zeros`.
Args:
tensor: an n-dimensional `torch.Tensor`
Examples:
>>> w = torch.empty(3, 5)
>>> nn.init.zeros_(w)
"""
with torch.no_grad():
return tensor.zero_()
6)单位矩阵
用单位矩阵来填充2维输入张量或变量,在线性层尽可能多的保存输入特性
def eye_(tensor):
r"""Fills the 2-dimensional input `Tensor` with the identity
matrix. Preserves the identity of the inputs in `Linear` layers, where as
many inputs are preserved as possible.
Args:
tensor: a 2-dimensional `torch.Tensor`
Examples:
>>> w = torch.empty(3, 5)
>>> nn.init.eye_(w)
"""
if tensor.ndimension() != 2:
raise ValueError("Only tensors with 2 dimensions are supported")
with torch.no_grad():
torch.eye(*tensor.shape, out=tensor, requires_grad=tensor.requires_grad)
return tensor
7)dirac(delta)函数
详见《DiracNets: Training Very Deep Neural Networks Without Skip-Connections》
这个函数是比较新的一种初始化方法,问题提到,用该方法初始化不用skip的resnet,收到不俗效果(具体没看)
def dirac_(tensor):
r"""Fills the {3, 4, 5}-dimensional input `Tensor` with the Dirac
delta function. Preserves the identity of the inputs in `Convolutional`
layers, where as many input channels are preserved as possible.
Args:
tensor: a {3, 4, 5}-dimensional `torch.Tensor`
Examples:
>>> w = torch.empty(3, 16, 5, 5)
>>> nn.init.dirac_(w)
"""
dimensions = tensor.ndimension()
if dimensions not in [3, 4, 5]:
raise ValueError("Only tensors with 3, 4, or 5 dimensions are supported")
sizes = tensor.size()
min_dim = min(sizes[0], sizes[1])
with torch.no_grad():
tensor.zero_()
for d in range(min_dim):
if dimensions == 3: # Temporal convolution
tensor[d, d, tensor.size(2) // 2] = 1
elif dimensions == 4: # Spatial convolution
tensor[d, d, tensor.size(2) // 2, tensor.size(3) // 2] = 1
else: # Volumetric convolution
tensor[d, d, tensor.size(2) // 2, tensor.size(3) // 2, tensor.size(4) // 2] = 1
return tensor
8)xavier_uniform_ 均匀分布
def _calculate_fan_in_and_fan_out(tensor):
dimensions = tensor.ndimension()
if dimensions < 2:
raise ValueError("Fan in and fan out can not be computed for tensor with fewer than 2 dimensions")
if dimensions == 2: # Linear
fan_in = tensor.size(1)
fan_out = tensor.size(0)
else:
num_input_fmaps = tensor.size(1)
num_output_fmaps = tensor.size(0)
receptive_field_size = 1
if tensor.dim() > 2:
receptive_field_size = tensor[0][0].numel()
fan_in = num_input_fmaps * receptive_field_size
fan_out = num_output_fmaps * receptive_field_size
return fan_in, fan_out
根据Glorot, X.和Bengio, Y.在“Understanding the difficulty of training deep feedforward neural networks”中描述的方法,用一个均匀分布生成值,填充输入的张量或变量。结果张量中的值采样自U(-a, a),其中a= gain * sqrt( 6/(fan_in + fan_out)). 该方法也被称为Glorot initialisation
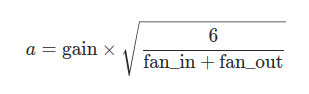
def xavier_uniform_(tensor, gain=1):
r"""Fills the input `Tensor` with values according to the method
described in "Understanding the difficulty of training deep feedforward
neural networks" - Glorot, X. & Bengio, Y. (2010), using a uniform
distribution. The resulting tensor will have values sampled from
:math:`\mathcal{U}(-a, a)` where
.. math::
a = \text{gain} \times \sqrt{\frac{6}{\text{fan\_in} + \text{fan\_out}}}
Also known as Glorot initialization.
Args:
tensor: an n-dimensional `torch.Tensor`
gain: an optional scaling factor
Examples:
>>> w = torch.empty(3, 5)
>>> nn.init.xavier_uniform_(w, gain=nn.init.calculate_gain('relu'))
"""
fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor)
std = gain * math.sqrt(2.0 / (fan_in + fan_out))
a = math.sqrt(3.0) * std # Calculate uniform bounds from standard deviation
with torch.no_grad():
return tensor.uniform_(-a, a)
9)xavier_normal_ 正态分布
根据Glorot, X.和Bengio, Y. 于2010年在“Understanding the difficulty of training deep feedforward neural networks”中描述的方法,用一个正态分布生成值,填充输入的张量或变量。结果张量中的值采样自均值为0,标准差为gain * sqrt(2/(fan_in + fan_out))的正态分布。也被称为Glorot initialisation.
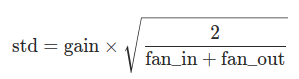
def xavier_normal_(tensor, gain=1):
r"""Fills the input `Tensor` with values according to the method
described in "Understanding the difficulty of training deep feedforward
neural networks" - Glorot, X. & Bengio, Y. (2010), using a normal
distribution. The resulting tensor will have values sampled from
:math:`\mathcal{N}(0, \text{std})` where
.. math::
\text{std} = \text{gain} \times \sqrt{\frac{2}{\text{fan\_in} + \text{fan\_out}}}
Also known as Glorot initialization.
Args:
tensor: an n-dimensional `torch.Tensor`
gain: an optional scaling factor
Examples:
>>> w = torch.empty(3, 5)
>>> nn.init.xavier_normal_(w)
"""
fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor)
std = gain * math.sqrt(2.0 / (fan_in + fan_out))
with torch.no_grad():
return tensor.normal_(0, std)
10)kaiming_uniform_ 均匀分布
def calculate_gain(nonlinearity, param=None):
r"""Return the recommended gain value for the given nonlinearity function.
The values are as follows:
================= ====================================================
nonlinearity gain
================= ====================================================
Linear / Identity :math:`1`
Conv{1,2,3}D :math:`1`
Sigmoid :math:`1`
Tanh :math:`\frac{5}{3}`
ReLU :math:`\sqrt{2}`
Leaky Relu :math:`\sqrt{\frac{2}{1 + \text{negative\_slope}^2}}`
================= ====================================================
Args:
nonlinearity: the non-linear function (`nn.functional` name)
param: optional parameter for the non-linear function
Examples:
>>> gain = nn.init.calculate_gain('leaky_relu')
"""
linear_fns = ['linear', 'conv1d', 'conv2d', 'conv3d', 'conv_transpose1d', 'conv_transpose2d', 'conv_transpose3d']
if nonlinearity in linear_fns or nonlinearity == 'sigmoid':
return 1
elif nonlinearity == 'tanh':
return 5.0 / 3
elif nonlinearity == 'relu':
return math.sqrt(2.0)
elif nonlinearity == 'leaky_relu':
if param is None:
negative_slope = 0.01
elif not isinstance(param, bool) and isinstance(param, int) or isinstance(param, float):
# True/False are instances of int, hence check above
negative_slope = param
else:
raise ValueError("negative_slope {} not a valid number".format(param))
return math.sqrt(2.0 / (1 + negative_slope ** 2))
else:
raise ValueError("Unsupported nonlinearity {}".format(nonlinearity))

def _calculate_correct_fan(tensor, mode):
mode = mode.lower()
valid_modes = ['fan_in', 'fan_out']
if mode not in valid_modes:
raise ValueError("Mode {} not supported, please use one of {}".format(mode, valid_modes))
fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor)
return fan_in if mode == 'fan_in' else fan_out
根据He, K等人于2015年在“Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification”中描述的方法,用一个均匀分布生成值,填充输入的张量或变量。结果张量中的值采样自U(-bound, bound),其中bound = sqrt(6/((1 + a^2) * fan_in)) 。也被称为He initialisation.
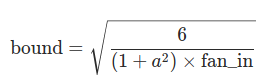
def kaiming_uniform_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu'):
r"""Fills the input `Tensor` with values according to the method
described in "Delving deep into rectifiers: Surpassing human-level
performance on ImageNet classification" - He, K. et al. (2015), using a
uniform distribution. The resulting tensor will have values sampled from
:math:`\mathcal{U}(-\text{bound}, \text{bound})` where
.. math::
\text{bound} = \sqrt{\frac{6}{(1 + a^2) \times \text{fan\_in}}}
Also known as He initialization.
Args:
tensor: an n-dimensional `torch.Tensor`
a: the negative slope of the rectifier used after this layer (0 for ReLU
by default)
mode: either 'fan_in' (default) or 'fan_out'. Choosing `fan_in`
preserves the magnitude of the variance of the weights in the
forward pass. Choosing `fan_out` preserves the magnitudes in the
backwards pass.
nonlinearity: the non-linear function (`nn.functional` name),
recommended to use only with 'relu' or 'leaky_relu' (default).
tensor – n维的torch.Tensor或autograd.Variable
a -这层之后使用的rectifier的斜率系数(ReLU的默认值为0)
mode -可以为“fan_in”(默认)或“fan_out”。“fan_in”保留前向传播时权值方差的量级,“fan_out”保留反向传播时的量级。
Examples:
>>> w = torch.empty(3, 5)
>>> nn.init.kaiming_uniform_(w, mode='fan_in', nonlinearity='relu')
"""
fan = _calculate_correct_fan(tensor, mode)
gain = calculate_gain(nonlinearity, a)
std = gain / math.sqrt(fan)
bound = math.sqrt(3.0) * std # Calculate uniform bounds from standard deviation
with torch.no_grad():
return tensor.uniform_(-bound, bound)
11)kaiming_normal_ 正态分布
根据He, K等人在“Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification”中描述的方法,用一个正态分布生成值,填充输入的张量或变量。结果张量中的值采样自均值为0,标准差为sqrt(2/((1 + a^2) * fan_in))的正态分布。
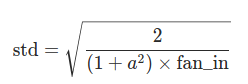
def kaiming_normal_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu'):
r"""Fills the input `Tensor` with values according to the method
described in "Delving deep into rectifiers: Surpassing human-level
performance on ImageNet classification" - He, K. et al. (2015), using a
normal distribution. The resulting tensor will have values sampled from
:math:`\mathcal{N}(0, \text{std})` where
.. math::
\text{std} = \sqrt{\frac{2}{(1 + a^2) \times \text{fan\_in}}}
Also known as He initialization.
Args:
tensor: an n-dimensional `torch.Tensor`
a: the negative slope of the rectifier used after this layer (0 for ReLU
by default)
mode: either 'fan_in' (default) or 'fan_out'. Choosing `fan_in`
preserves the magnitude of the variance of the weights in the
forward pass. Choosing `fan_out` preserves the magnitudes in the
backwards pass.
nonlinearity: the non-linear function (`nn.functional` name),
recommended to use only with 'relu' or 'leaky_relu' (default).
Examples:
>>> w = torch.empty(3, 5)
>>> nn.init.kaiming_normal_(w, mode='fan_out', nonlinearity='relu')
"""
fan = _calculate_correct_fan(tensor, mode)
gain = calculate_gain(nonlinearity, a)
std = gain / math.sqrt(fan)
with torch.no_grad():
return tensor.normal_(0, std)
12)orthogonal_
用(半)正交矩阵填充输入的张量或变量。输入张量必须至少是2维的,对于更高维度的张量,超出的维度会被展平,视作行等于第一个维度,列等于稀疏矩阵乘积的2维表示。其中非零元素生成自均值为0,标准差为std的正态分布。
参考:Saxe, A等人(2013)的“Exact solutions to the nonlinear dynamics of learning in deep linear neural networks”
def orthogonal_(tensor, gain=1):
r"""Fills the input `Tensor` with a (semi) orthogonal matrix, as
described in "Exact solutions to the nonlinear dynamics of learning in deep
linear neural networks" - Saxe, A. et al. (2013). The input tensor must have
at least 2 dimensions, and for tensors with more than 2 dimensions the
trailing dimensions are flattened.
Args:
tensor: an n-dimensional `torch.Tensor`, where :math:`n \geq 2`
gain: optional scaling factor
Examples:
>>> w = torch.empty(3, 5)
>>> nn.init.orthogonal_(w)
"""
if tensor.ndimension() < 2:
raise ValueError("Only tensors with 2 or more dimensions are supported")
rows = tensor.size(0)
cols = tensor[0].numel()
flattened = tensor.new(rows, cols).normal_(0, 1)
if rows < cols:
flattened.t_()
# Compute the qr factorization
q, r = torch.qr(flattened)
# Make Q uniform according to https://arxiv.org/pdf/math-ph/0609050.pdf
d = torch.diag(r, 0)
ph = d.sign()
q *= ph
if rows < cols:
q.t_()
with torch.no_grad():
tensor.view_as(q).copy_(q)
tensor.mul_(gain)
return tensor
13)sparse_
将2维的输入张量或变量当做稀疏矩阵填充,其中非零元素根据一个均值为0,标准差为std的正态分布生成。 参考Martens, J.(2010)的 “Deep learning via Hessian-free optimization”.
def sparse_(tensor, sparsity, std=0.01):
r"""Fills the 2D input `Tensor` as a sparse matrix, where the
non-zero elements will be drawn from the normal distribution
:math:`\mathcal{N}(0, 0.01)`, as described in "Deep learning via
Hessian-free optimization" - Martens, J. (2010).
Args:
tensor: an n-dimensional `torch.Tensor`
sparsity: The fraction of elements in each column to be set to zero
std: the standard deviation of the normal distribution used to generate
the non-zero values
Examples:
>>> w = torch.empty(3, 5)
>>> nn.init.sparse_(w, sparsity=0.1)
"""
if tensor.ndimension() != 2:
raise ValueError("Only tensors with 2 dimensions are supported")
rows, cols = tensor.shape
num_zeros = int(math.ceil(sparsity * rows))
with torch.no_grad():
tensor.normal_(0, std)
for col_idx in range(cols):
row_indices = torch.randperm(rows)
zero_indices = row_indices[:num_zeros]
tensor[zero_indices, col_idx] = 0
return tensor
2 模型初始化–CPN
1)resnet
在类ResNet的init函数中,组件注册下面有这段代码:
for m in self.modules(): #遍历模型
if isinstance(m, nn.Conv2d): #isinstance:m类型判断 若当前组件为 conv
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n)) #正太分布初始化
elif isinstance(m, nn.BatchNorm2d): #若为batchnorm
m.weight.data.fill_(1) #weight为1
m.bias.data.zero_() #bias为0
这里将所有带参数的层都初始化
在resnet50这个方法里面,有( if pretrained:)这么一段:
def resnet50(pretrained=False, **kwargs):
"""Constructs a ResNet-50 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs)
if pretrained:
print('Initialize with pre-trained ResNet')
from collections import OrderedDict
state_dict = model.state_dict()
pretrained_state_dict = model_zoo.load_url(model_urls['resnet50'])
for k, v in pretrained_state_dict.items():
if k not in state_dict:
continue
state_dict[k] = v
print('successfully load '+str(len(state_dict.keys()))+' keys')
model.load_state_dict(state_dict)
return model
如果预训练模型存在,则加载并初始化,会覆盖掉前面随机初始化参数
这里涉及到模型加载,预训练模型,finetune等知识,本人准备将这块单独总结
但要知道我们通常所说的加载预训练模型或finetune,其实都是为了我们模型参数有更好的初始值,可以让模型更好更快地收敛,甚至有时可以用少量数据就可以达到目的;这就好比我们去教一个孩子学习某种技能,如果这个孩子已经在这方面有好的基础,我们教起来就容易得多,相反,若是个小白,就会耗费我们更多的精力和时间
2)globalnet
在类globalNet的init函数中,组件注册下面有这段代码:
其方法和上面resnet一样
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()