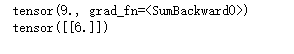参考
4.2 模型参数的访问、初始化和共享
在3.3节(线性回归的简洁实现)中,我们通过init模块来初始化模型的参数。我们也介绍了访问模型参数的简单方法。本节将深入讲解如何访问和初始化模型参数,以及如何在多个层之间共享同一份模型参数。
import torch
from torch import nn
from torch.nn import init
net = nn.Sequential(nn.Linear(4,3), nn.ReLU(), nn.Linear(3, 1))
print(net)
X = torch.rand(2, 4)
Y = net(X).sum()

4.2.1 访问模型的参数
回忆上一节中提到的Sequential类与Module类的继承关系。对于Sequential实例中含模型参数的层,我们可以通过Module类的parameters()或者named_parameters方法来访问所有参数(以迭代器的形式返回),后者除了返回参数Tensor外还会返回其名字
print(type(net.named_parameters()))
for name, param in net.named_parameters():
print(name, param.size())

可见返回的名字自动加上了层数的索引作为前缀。我们再来访问net中单层的参数。对于使用Sequential类构造的神经网络,我们可以通过方括号[]来访问网络的任一层。索引0表示隐藏层为Sequential实例最先添加的层.
for name, param in net[0].named_parameters():
print(name, param.size(), type(param))

# 如果一个Tensor是Parameter,那么它会自动被添加到模型的参数列表里
class MyModel(nn.Module):
def __init__(self, **kwargs):
super(MyModel, self).__init__(**kwargs)
self.weight1 = nn.Parameter(torch.rand(20, 20))
self.weight2 = torch.rand(20, 20)
def forward(self, x):
pass
n = MyModel()
for name, param in n.named_parameters():
print(name)
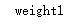
# 上面代码中weight1在参数列表中,但是weight2却没在参数列表中
# 因为Parameters是Tensor,即Tensor拥有的属性它都有,比如可以根据data来访问参数数值,用grad来访问参数梯度
weight_0 = list(net[0].parameters())[0] # 将第0层的W取出
print(net)
print(weight_0)
print(weight_0.grad) # 此时并未对Y做梯度下降,因此会显示None
Y.backward()
print(weight_0.grad)

4.2.2 初始化模型参数
在下面的例子中,我们将权重参数初始化为均值为0、标准差为0.01的正态分布随机数,并依然将偏差参数清零。
for name, param in net.named_parameters():
if 'weight' in name:
init.normal_(param, mean=0, std=0.01)
print(name, param.data)

# 使用常数来初始化权重参数
for name, param in net.named_parameters():
if 'bias' in name:
init.constant_(param, val=0)
print(name, param.data)
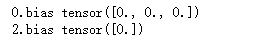
4.2.3 自定义初始化方法
有时候我们需要的初始化方法并没有在init模块中提供。这时,可以实现一个初始化方法,从而能够像使用其他方法那样使用它。
扫描二维码关注公众号,回复:
12281417 查看本文章

# 我们先看看pytorch如何实现的
def normal_(tensor, mean=0, std= 1):
with torch.no_grad:
return tensor.normal_(mean, std)
可以看到这就是一个inplace改变Tensor值的函数,而且这个过程是不记录梯度的。 类似的我们来实现一个自定义的初始化方法。在下面的例子里,我们令权重有一半概率初始化为0,有另一半概率初始化为[−10,−5]和[5,10]两个区间里均匀分布的随机数。
def init_weight_(tensor):
with torch.no_grad():
tensor.uniform_(-10, 10)
tensor *= (tensor.abs() >= 5).float()
for name, param in net.named_parameters():
if 'weight' in name:
init_weight_(param)
print(name, param.data)

4.2.4 共享模型参数
在有些情况下,我们希望在多个层之间共享模型参数。下面来看一个例子
linear = nn.Linear(1, 1, bias=False)
net = nn.Sequential(linear, linear)
print(net)
for name, param in net.named_parameters():
init.constant_(param, val = 3)
print(name, param.data)

# 在内存中,这两个线性层其实是一个对象
print(id(net[0]) == id(net[1]))
print(id(net[0].weight) == id(net[1].weight))

# 因为模型参数里包含了梯度,所以在反向传播时,这些共享的参数的梯度是累加的
x = torch.ones(1, 1)
y = net(x).sum()
print(y)
y.backward()
print(net[0].weight.grad)