文章目录
-
为什么需要选择不同的权重初始化方法?和梯度消失和梯度爆炸之间的关系是什么?
模型的正向传播和反向传播都是基于矩阵乘法来实现,当网络很深的时候,在更新模型参数时,梯度值可能很大或者很小,导致梯度爆炸和梯度消失的问题,网络不稳定、无法收敛的现象。除了残差块、梯度归一化、激活函数等方式外,合理的网络权重初始化也是一种缓解梯度消失和梯度爆炸的重要方法之一。
合理的权重初始化内涵是:合理控制每一层的输出和梯度大小,并使得输入和输出的均值和方差保持一致。这里只提到均值和方差,没提到具体服从什么分布。一般涉及均匀分布和高斯分布两种,这作为下面两种初始化方法的假设前提。
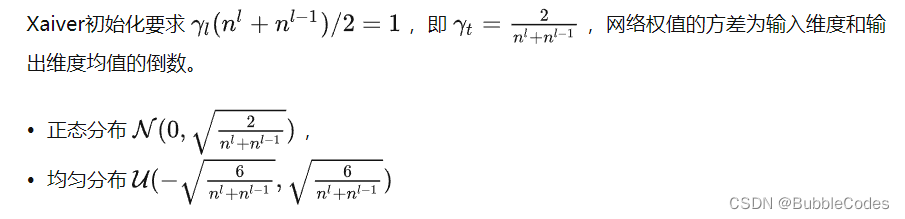
xvaier初始化方法在sigmoid、tanh等类似激活函数上表现不错,但是在relu激活函数上表现不佳。实际使用过程中还有一个参数gain根据具体的激活函数类型来调整。
kaiming初始化方法为了解决xvaier初始化方法在非对称的激活函数如relu激活函数上表现不佳的问题而提出的。值得一提的是,两种初始化都是从方差一致性的角度出发来设计的。 -
pytorch的默认权重初始化是什么样的
-
使用了BN之后是否不需要初始化bias
是