1、什么是过拟合?
过拟合是指在模型参数拟合过程中的问题,由于训练数据包含抽样误差,训练时复杂的模型将抽样误差也考虑在内,将抽样误差也进行了很好的拟合。
2、过拟合带来什么问题?
最终模型在训练集上效果好;在测试集上效果差。模型泛化能力弱。
3、过拟合产生的原因?
在对模型进行训练时,有可能遇到训练数据不够,即训练数据无法对整个数据的分布进行估计;
权值学习迭代次数足够多(Overtraining),拟合了训练数据中的噪声和训练样例中没有代表性的特征。

随着模型训练的进行,模型的复杂度会增加,此时模型在训练集上的训练误差会逐渐减小,但在模型的复杂度达到一定程度时,模型在验证集上的误差反而随着模型的复杂度增加而增大,此时便发生了过拟合现象。
4、如何解决过拟合问题?
- Early stopping
对模型进行训练的过程即是对模型的参数进行学习更新的过程,往往会用到一些迭代方法,如梯度下降学习算法,Early stopping便是一种迭代次数截断的方法来防止过拟合的方法,在模型对训练集迭代收敛之前停止迭代来防止过拟合。
具体做法:
在每一个Epoch结束时(一个Epoch集为对所有的训练数据的一轮遍历)计算validation data 的accuracy,当accuracy不再提高时,就停止训练,在训练的过程中,记录目前为止最好的validation accuracy,当连续10次Epoch(或者更多次)没达到最佳accuracy时,则停止迭代。
- 数据集扩增
这是解决过拟合最有效的方法,只要给足够多的数据,让模型尽可能多的适应【例外情况】,就会不断修正参数,得到更好的结果。
从数据源获取更多数据;根据当前数据集估计数据分布参数,使用该分布产生更多数据(一般不用,或引入抽样误差);数据增强,通过一定规则扩充数据,如在物体分类问题里,物体在图像中的位置、姿态、尺度、图片明暗度等都不会影响分类结果,可以通过图像平移、翻转、缩放等扩充数据。
- 正则化
在计算损失函数时加上正则项,减少特征量的权值,减少方差,避免某些参数值过大即过于“依赖”某些神经元,
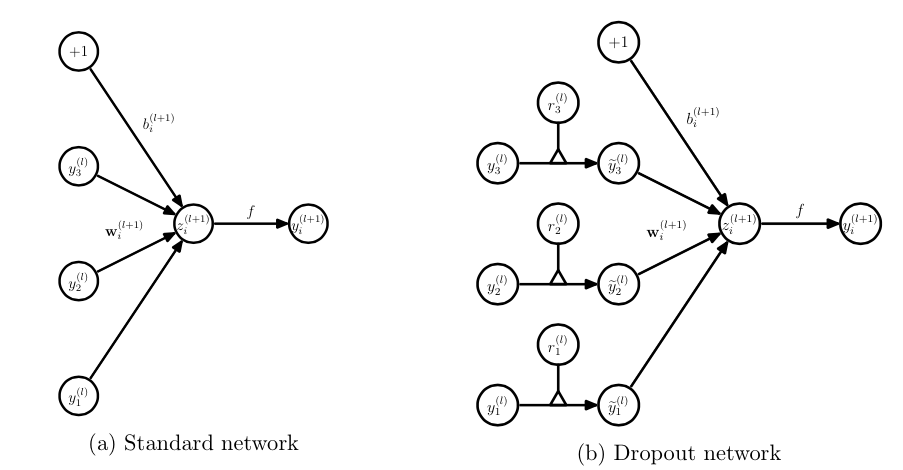
- dropout
dropout在深度学习网络的训练过程中,多余神经网络单元,按照一定的概率将其暂时兄网络中丢弃。
训练网络的每个单元要添加一道概率流程: