范数、稀疏与过拟合合集(1)范数的定义与常用范数介绍
范数、稀疏与过拟合合集(2)有监督模型下的过拟合与正则化加入后缓解过拟合的原理
范数、稀疏与过拟合合集(3)范数与稀疏化的原理、L0L1L2范数的比较以及数学分析
范数、稀疏与过拟合合集(4)L2范数对condition number较差情况的缓解
范数、稀疏与过拟合合集(5)Dropout原理,操作实现,为什么可以缓解过拟合,使用中的技巧
范数、稀疏与过拟合合集(6)过拟合的成因、判断、常用八种解决措施
1、过拟合的判断
有一个概念需要先说明,在机器学习、深度学习算法中,我们常常将原始数据集分为三部分:training data、validation data,testing data。这个validation data是什么?它其实就是用来避免过拟合的,在训练过程中,我们通常用它来确定一些超参数,比如根据validation data上的accuracy来确定什么样的参数最好最有效果。那为啥不直接在testing data上做这些呢?因为如果在testing data做这些,那么随着训练的进行,我们的网络实际上就是在一点一点猜出了什么样的训练结果会在testing data上面表现最好,导致最后得到的testing accuracy没有任何参考意义,这其实就是过度拟合了训练集,也过度拟合了验证集,测试集最终的目的就是用来判断:最后的训练效果在未知数据上是否也有着较好的表现。
所谓过拟合,指的是模型在训练集上表现的很好,但是在交叉验证集、测试集上表现一般,也就是说模型对未知样本的预测表现一般,泛化(generalization)能力较差。
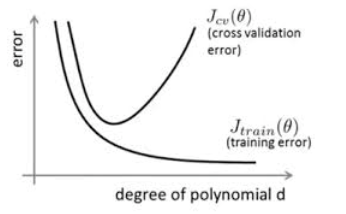
2、过拟合的成因
2.1 训练数据的问题
第一方面:训练数据无法对整个数据的分布进行估计,或者也有可能是训练集和测试集特征分布不一致。
第二方面:训练集的数量级和模型的复杂度不匹配。训练集的数量级要远远小于模型的复杂度。
第三方面:样本里的噪音数据干扰过大,大到模型过分记住了嗓音特征,反而忽略了真实的输入输出间的关系
2.2 训练的问题:
对模型进行过度训练(overtraining):对于参数更新迭代次数足够多,拟合了训练数据中的噪声和训练样例中没有代表性的特征。
3、解决缓解过拟合的措施
3.1 调小模型复杂度(Simpler model structure)
使其适合自己训练集的数量级(缩小宽度和减小深度)
3.1.1 权值共享
权值共享最常见的就是在卷积神经网络中,权值共享的目的旨在减小模型中的参数,同时还能较少计算量。在循环神经网络中也用到了权值共享。
3.1.2 剪枝处理
剪枝是决策树中一种控制过拟合的方法,我们知道决策树是一种非常容易陷入过拟合的算法,剪枝处理主要有预剪枝和后剪枝这两种,常见的是两种方法一起使用。预剪枝通过在训练过程中控制树深、叶子节点数、叶子节点中样本的个数等来控制树的复杂度。后剪枝则是在训练好树模型之后,采用交叉验证的方式进行剪枝以找到最优的树模型。
3.2 数据增广(Data augmentation)
很明显训练集越多越大,过拟合的概率越小。
在数据挖掘领域流行着这样的一句话,“有时候往往拥有更多的数据胜过一个好的模型”。但是往往条件有限,如人力物力财力的不足,而不能收集到更多的数据,如在进行分类的任务中,需要对数据进行打标,并且很多情况下都是人工得进行打标,因此一旦需要打标的数据量过多,就会导致效率低下以及可能出错的情况。所以,往往在这时候,需要采取一些计算的方式与策略在已有的数据集上进行手脚,以得到更多的数据。
通俗得讲,数据机扩增即需要得到更多的符合要求的数据,即和已有的数据是独立同分布的,或者近似独立同分布的。一般有以下方法:
- 从数据源头采集更多数据
- 对已有数据进行重采样
- 添加噪声
- 根据当前数据集估计数据分布参数,使用该分布产生更多数据等。在计算机视觉领域中,这种增广方式一般包括(旋转、翻折、缩放、剪切)
3.3 提前终止迭代(Early stopping)
该方法主要是用在神经网络中,在神经网络的训练过程中我们会初始化一组较小的权值参数,此时模型的拟合能力较弱,通过迭代训练来提高模型的拟合能力,随着迭代次数的增大,部分的权值也会不断的增大到符合训练集预设label的局部最优点。
Early stopping便是一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代,来防止过拟合。
一方面:果我们提前终止迭代可以有效的控制权值参数的大小不让他增大到足够大,从而降低模型的复杂度。
另一方面:如果我们提前终止迭代可以较少为了迎合训练集,过度的关注不具有代表性的特征噪声。
这样可以有效阻止过拟合的发生,因为过拟合本质上就是对自身特点过度地学习。
3.4 批次归一化(Batch Normalization)
BN算法是一种非常有用的正则化方法,而且可以让大型的卷积神经网络快速收敛,同时还能提高分类的准确率,而且可以不需要使用局部响应归一化处理,也可以不需要加入Dropout。BN算法会将每一层的输入值做归一化处理,并且会重构归一化处理之后的数据,确保数据的分布不会发生变化。
而且有很多变种,比如Layer Normalization,在RNN或者Transformer中用的比较多。
3.5 增加噪声
这也是深度学习中的一种避免过拟合的方法(没办法,深度学习模型太复杂,容易过拟合),添加噪声的途径有很多,相比于之前所叙述的在数据上添加,增大数据的多样性,这里描述的是可以在权值上添加噪声。
3.6 模型集成(Bagging、Boosting)
Bagging和Boosting是机器学习中的集成方法,多个模型的组合可以弱化每个模型中的异常点的影响,保留模型之间的通性,弱化单个模型的特性。
3.7 正则化(Regularization)
可以查看之前的blog
深度学习机器学习理论知识:范数、稀疏与过拟合合集(2)有监督模型下的过拟合与正则化加入后缓解过拟合的原理_呆呆象呆呆的博客-CSDN博客
深度学习机器学习理论知识:范数、稀疏与过拟合合集(3)范数与稀疏化的原理、L0L1L2范数的比较以及数学分析_呆呆象呆呆的博客-CSDN博客
3.8 随机丢弃(Dropout)
可以查看之前的blog
深度学习机器学习理论知识:范数、稀疏与过拟合合集(5)Dropout原理,操作实现,为什么可以缓解过拟合,使用中的技巧_呆呆象呆呆的博客-CSDN博客
LAST、参考文献
过拟合以及解决办法_qzlicn的博客-CSDN博客_过拟合