1.基本流程
pytorch在训练过程有一个很基本的流程,正常情况下就按这个流程就能够训练模型:
1.加载模型,2初始化数据,3.预定义优化器,4.训练
# 模型加载
model = Darknet(opt.model_config_path)
# pytroch函数 Module.apply 对所有子模型初始化
# https://pytorch.org/docs/stable/nn.html?highlight=apply#torch.nn.Module.apply
model.apply(weights_init_normal)
if torch.cuda.is_available() and opt.use_cuda:
model = model.cuda()
# 优化器
optimizer = torch.optim.Adam(
filter(lambda p: p.requires_grad, model.parameters()))
for epoch in range(opt.epochs):
for ii, (_, imgs, targets) in tqdm(enumerate(dataloader)):
imgs = imgs.cuda()
targets = targets.type(torch.cuda.FloatTensor)
optimizer.zero_grad()
loss = model(imgs, targets)
loss.backward()
optimizer.step()2.模型
本图引用:https://blog.csdn.net/leviopku/article/details/82660381

yolov3采用了配置文件来构制网络层,由于yolov3较大的网络层数目,由配置文件来编写网络层可以使得代码量少很多.配置文件中每个网络块都有一个题名,按照题名划分来构建网络层.一共六种模块,对应与yolov3网络的不同结构
def create_modules(module_defs):
# yolov3网络使用了非常多的卷积层,为了减少构建模型的麻烦,
# 原作者使用配置文件来辅助构建网络,减小了模型构建所需要的代码量
hyperparams = module_defs.pop(0)
output_filters = [int(hyperparams["channels"])]
module_list = nn.ModuleList() # 模型序列
for i, module_def in enumerate(module_defs):
modules = nn.Sequential() # 子序列 代表一个子结构
if module_def["type"] == "convolutional": # 卷积块 conv bn leaky
bn = int(module_def["batch_normalize"])
filters = int(module_def["filters"])
kernel_size = int(module_def["size"])
pad = (kernel_size - 1) // 2 if int(module_def["pad"]) else 0
modules.add_module(
"conv_%d" % i,
nn.Conv2d(
in_channels=output_filters[-1],
out_channels=filters,
kernel_size=kernel_size,
stride=int(module_def["stride"]),
padding=pad,
bias=not bn,
),
)
if bn:
modules.add_module("batch_norm_%d" %
i, nn.BatchNorm2d(filters))
if module_def["activation"] == "leaky":
modules.add_module("leaky_%d" % i, nn.LeakyReLU(0.1))
elif module_def["type"] == "maxpool": # 池化层 maxpooling
kernel_size = int(module_def["size"])
stride = int(module_def["stride"])
if kernel_size == 2 and stride == 1:
padding = nn.ZeroPad2d((0, 1, 0, 1))
modules.add_module("_debug_padding_%d" % i, padding)
maxpool = nn.MaxPool2d(
kernel_size=int(module_def["size"]),
stride=int(module_def["stride"]),
padding=int((kernel_size - 1) // 2),
)
modules.add_module("maxpool_%d" % i, maxpool)
elif module_def["type"] == "upsample": # 上采样
upsample = nn.Upsample(scale_factor=int(
module_def["stride"]), mode="nearest")
modules.add_module("upsample_%d" % i, upsample)
elif module_def["type"] == "route": # 空层
layers = [int(x) for x in module_def["layers"].split(",")]
filters = sum([output_filters[layer_i] for layer_i in layers])
modules.add_module("route_%d" % i, EmptyLayer())
elif module_def["type"] == "shortcut": # 空层
filters = output_filters[int(module_def["from"])]
modules.add_module("shortcut_%d" % i, EmptyLayer())
elif module_def["type"] == "yolo": # 最后一个检测层
anchor_idxs = [int(x) for x in module_def["mask"].split(",")]
# Extract anchors
anchors = [int(x) for x in module_def["anchors"].split(",")]
anchors = [(anchors[i], anchors[i + 1])
for i in range(0, len(anchors), 2)]
anchors = [anchors[i] for i in anchor_idxs]
num_classes = int(module_def["classes"])
img_height = int(hyperparams["height"])
# Define detection layer
yolo_layer = YOLOLayer(anchors, num_classes, img_height)
modules.add_module("yolo_%d" % i, yolo_layer)
# Register module list and number of output filters
module_list.append(modules)
output_filters.append(filters)
return hyperparams, module_list3.YOLO层
该层对应的是网络的最后一层(y1,y2,y3).首先获得预测结果prediction(x,y,w,h,con,cls).
prediction = x.view(nB, nA, self.bbox_attrs, nG, nG).permute(
0, 1, 3, 4, 2).contiguous() # 维度转换, contiguous()相当于复制
# prediction.shape:(1, 3, 13, 13, 85)
# 输出预测结果,说明的是x,y是预测的b-box中心点相对于网格单元左上角的相对坐标
x = torch.sigmoid(prediction[..., 0]) # Center x (1,3,13,13)
y = torch.sigmoid(prediction[..., 1]) # Center y
w = prediction[..., 2] # Width
h = prediction[..., 3] # Height
pred_conf = torch.sigmoid(prediction[..., 4]) # bbox的置信度
pred_cls = torch.sigmoid(prediction[..., 5:]) # 每个类别的概率再计算网格单元左上角坐标和锚节点对应比例,这个锚节点是聚类计算过的大小,大小固定,所以直接可以使用.
grid_x = torch.arange(nG).repeat(nG, 1).view(
[1, 1, nG, nG]).type(FloatTensor)
grid_y = torch.arange(nG).repeat(nG, 1).t().view(
[1, 1, nG, nG]).type(FloatTensor) # 五个单元左上角坐标
scaled_anchors = FloatTensor(
[(a_w / stride, a_h / stride) for a_w, a_h in self.anchors])
anchor_w = scaled_anchors[:, 0:1].view((1, nA, 1, 1))
anchor_h = scaled_anchors[:, 1:2].view((1, nA, 1, 1)) # prior先验
在通过相对坐标和偏移量计算实际坐标.
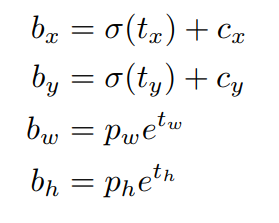
pred_boxes = FloatTensor(prediction[..., :4].shape)
pred_boxes[..., 0] = x.data + grid_x
pred_boxes[..., 1] = y.data + grid_y
pred_boxes[..., 2] = torch.exp(w.data) * anchor_w
pred_boxes[..., 3] = torch.exp(h.data) * anchor_h # 计算出实际坐标再计算真值标签相对于gird的真值标签.
最后计算损失
loss_x = self.mse_loss(x[mask], tx[mask])
loss_y = self.mse_loss(y[mask], ty[mask])
loss_w = self.mse_loss(w[mask], tw[mask])
loss_h = self.mse_loss(h[mask], th[mask])
loss_conf = self.bce_loss(pred_conf[conf_mask_false],tconf[conf_mask_false]) + self.bce_loss(
pred_conf[conf_mask_true], tconf[conf_mask_true]
)
loss_cls = (1 / nB) * \
self.ce_loss(pred_cls[mask], torch.argmax(tcls[mask], 1))
loss = loss_x + loss_y + loss_w + loss_h + loss_conf + loss_cls4.总网络
总网络编写了卷积层,cat连接层,点加层,输出层.
def forward(self, x, targets=None):
is_training = targets is not None
output = []
self.losses = defaultdict(float)
layer_outputs = []
for i, (module_def, module) in enumerate(zip(self.module_defs, self.module_list)):
if module_def["type"] in ["convolutional", "upsample", "maxpool"]:
x = module(x)
elif module_def["type"] == "route": # 拼接层
layer_i = [int(x) for x in module_def["layers"].split(",")]
x = torch.cat([layer_outputs[i] for i in layer_i], 1)
elif module_def["type"] == "shortcut": # add层
layer_i = int(module_def["from"])
x = layer_outputs[-1] + layer_outputs[layer_i]
elif module_def["type"] == "yolo":
# Train phase: get loss
if is_training:
# 返回YOLO层损失
xx = module[0](x, targets)
x = xx[0] # 总损失
losses = xx[1:] # 其他部分损失
for name, loss in zip(self.loss_names, losses):
self.losses[name] += loss
# Test phase: Get detections
else:
x = module(x)
output.append(x) # 每个输出的损失
layer_outputs.append(x)
self.losses["recall"] /= 3
self.losses["precision"] /= 3
return sum(output) if is_training else torch.cat(output, 1)