在本教程中,我们将使用 PyTorch 从头开始构建一个基本的 Transformer 模型。Vaswani 等人提出的 Transformer 模型。在论文“Attention is All You Need”中,是一种专为序列到序列任务(例如机器翻译和文本摘要)而设计的深度学习架构。它基于自注意力机制,已成为许多最先进的自然语言处理模型(如 GPT 和 BERT)的基础。
要构建 Transformer 模型,我们将按照以下步骤操作:
- 导入必要的库和模块
- 定义基本构建块:多头注意力、位置前馈网络、位置编码
- 构建编码器和解码器层
- 组合编码器和解码器层以创建完整的 Transformer 模型
- 准备样本数据
- 训练模型
让我们首先导入必要的库和模块。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as data
import math
import copy
现在,我们将定义 Transformer 模型的基本构建块。
Multi-Head Attention
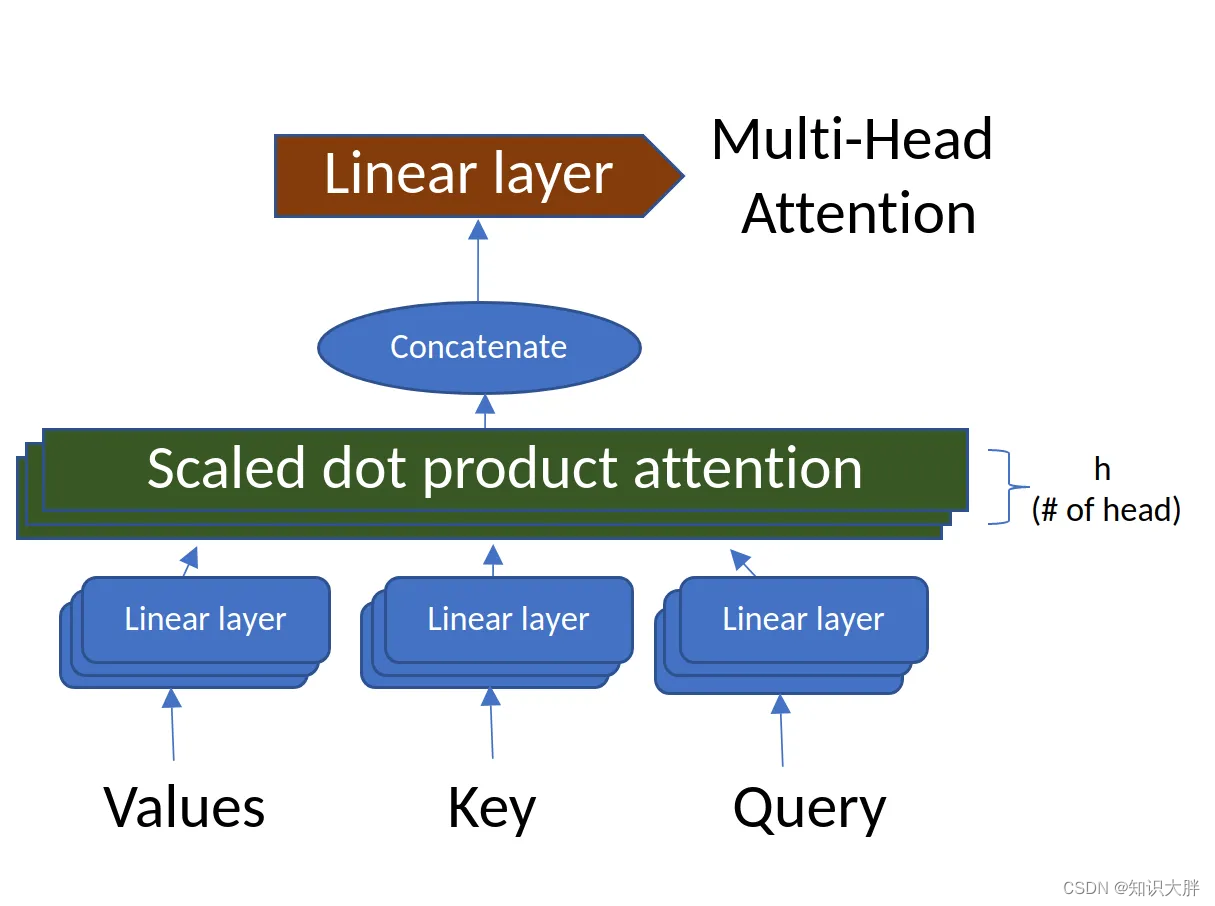
多头注意力机制计算序列中每对位置之间的注意力。它由多个“注意力头”组成,捕获输入序列的不同方面。
MultiHeadAttention 代码使用输入参数和线性变换层初始化模块。它计算注意力分数,将输入张量重塑为多个头,并组合所有头的注意力输出。前向方法