步骤和集群规划
1)保存完全分布式模式配置
2)在full配置的基础上修改为高可用HA
3)第一次启动HA
4)常规启动HA
5)运行wordcount
集群规划:
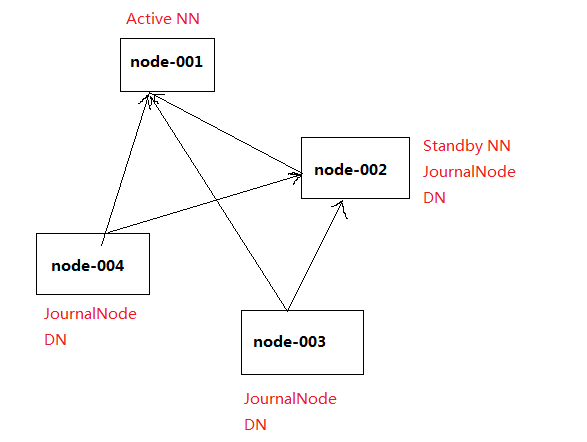
centos虚拟机:node-001、node-002、node-003、node-004
node-001:Active NN、JournalNode、resourcemanger
node-002:Standby NN、DN、JournalNode、nodemanger
node-003:DN、JournalNode、nodemanger
node-004:DN、JournalNode、nodemanger
扫描二维码关注公众号,回复:
5671706 查看本文章

一、保存full完全分布式配置
cp -r hadoop/ hadoop-full
二、修改配置成为HA(yarn部署)
主要修改core-site.xml、hdfs-site.xml、yarn-site.xml
1.修改core-site.xml文件
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://node-001:8020</value> </property> </configuration>
2.修改hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <!--定义nameservices逻辑名称--> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <!--映射nameservices逻辑名称到namenode逻辑名称--> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <!--映射namenode逻辑名称到真实主机名称(RPC)--> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>node-001:8020</value> </property> <!--映射namenode逻辑名称到真实主机名称(RPC)--> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>node-002:8020</value> </property> <!--映射namenode逻辑名称到真实主机名称(HTTP)--> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>node-001:50070</value> </property> <!--映射namenode逻辑名称到真实主机名称(HTTP)--> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>node-002:50070</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///home/lims/bd/hdfs/name</value> <description>Determines where on the local filesystem the DFS name node should store the name table(fsimage). If this is a comma-delimited list of directories then the name table is replicated in all of the directories, for redundancy. </description> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///home/lims/bd/hdfs/data</value> <description>Determines where on the local filesystem an DFS data node should store its blocks. If this is a comma-delimited list of directories, then data will be stored in all named directories, typically on different devices. Directories that do not exist are ignored. </description> </property> <!--配置journalnode集群位置信息及目录--> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node-002:8485;node-003:8485;node-004:8485/mycluster</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/lims/bd/hdfs/journal</value> </property> <!--配置故障切换实现类--> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!--指定切换方式为SSH免密钥方式--> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/lims/.ssh/id_dsa</value> </property> <!--设置自动切换--> <property> <name>dfs.ha.automatic-failover.enabled.mycluster</name> <value>false</value> </property> </configuration>
3.用scp分发到各个节点
scp hadoop/* lims@node-002:/home/lims/bd/hadoop-2.8.5/etc/hadoop scp hadoop/* lims@node-003:/home/lims/bd/hadoop-2.8.5/etc/hadoop scp hadoop/* lims@node-004:/home/lims/bd/hadoop-2.8.5/etc/hadoop
三、第一次启动HA
1)分别在node-002,node-003,node-004三个节点启动journalnode
hadoop-daemon.sh start journalnode
2)在node-001上格式化namenode
hdfs namenode -format
3)在node-001上启动namenode
hadoop-daemon.sh start namenode
4)在node-002,即另一台namenode上同步nn1的CID等信息
hdfs namenode -bootstrapStandby
5)手动切换node-001为active状态
hdfs haadmin -transitionToActive nn1
6)在node-001上启动其他服务
start-dfs.sh
四、常规启动HA
1)启动hdfs
start-dfs.sh
2)启动yarn
start-yarn.sh