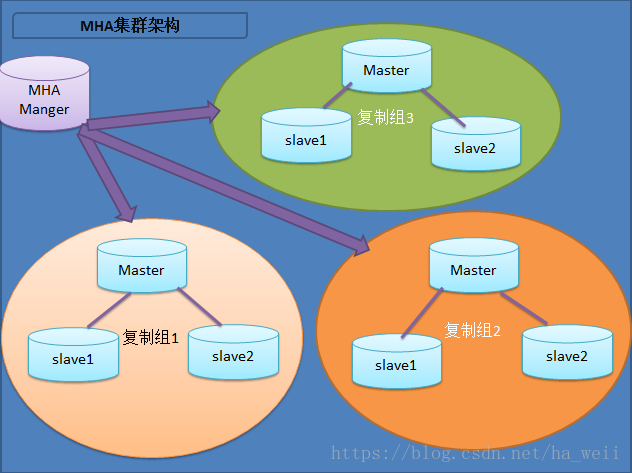
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
在MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用MySQL 5.5的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性。
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库,因为至少需要三台服务器,出于机器成本的考虑,淘宝也在该基础上进行了改造,目前淘宝TMHA已经支持一主一从。
server1:主机 管理节点
server2:从机
server3:从机
配置server1
1,关闭mysql,删除数据文件
[root@server1 ~]# chkconfig --list mysqld
mysqld 0:off 1:off 2:off 3:on 4:on 5:on 6:off
[root@server1 ~]# chkconfig mysqld off 关闭开机自启动
[root@server1 ~]# /etc/init.d/mysqld stop
Stopping mysqld: [ OK ]
[root@server1 ~]# cd /var/lib/mysql
[root@server1 mysql]# rm -rf *
2,修改配置文件
[root@server1 mysql]# vim /etc/my.cnf
添加以下代码
server_id=1
gtid_mode=ON
enforce_gtid_consistency=ON
master_info_repository=TABLE
relay_log_info_repository=TABLE
log_slave_updates=ON
log_bin=binlog
binlog_format=ROW
3,启动mysql
[root@server1 mysql]# /etc/init.d/mysqld start
Initializing MySQL database: [ OK ]
Installing validate password plugin: [ OK ]
Starting mysqld: [ OK ]
4,安全初始化
[root@server1 mysql]# mysql_secure_installation配置server2:
配置文件如下
server_id=2
gtid_mode=ON
enforce_gtid_consistency=ON
master_info_repository=TABLE
relay_log_info_repository=TABLE
log_slave_updates=ON
log_bin=binlog
binlog_format=ROW关闭开机自启chkconfig mysqld off
安全初始化
[root@server2 mysql]# mysql_secure_installation
配置server3
同serve2配置
一主两从制主从配置:
server1:
授权
mysql> grant replication slave on *.* to rep@'172.25.28.%' identified by 'Zming=1998';
Query OK, 0 rows affected, 1 warning (0.04 sec)
server2:
配置master为server1
mysql> change master to master_host='172.25.28.1',master_user='rep',master_password='Zming=1998',master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (0.66 sec)
mysql> start slave;
Query OK, 0 rows affected (0.06 sec)
mysql> show slave status\G;
这里会报错,这是因为主从数据不一样导致的,这里我们需要在slave,master做reset
(server1:mysql> reset master;
Query OK, 0 rows affected (0.54 sec)
mysql> stop slave;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> reset slave;
Query OK, 0 rows affected (0.35 sec)
mysql> start slave;
Query OK, 0 rows affected (0.28 sec)
此时再查看就没有报错了
mysql> show slave status\G;
)
server3:
方法同server2
mysql> change master to master_host='172.25.28.1',master_user='rep',master_password='Zming=1998',master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (0.41 sec)
mysql> start slave;
Query OK, 0 rows affected (0.06 sec)
mysql> show slave status\G;
没有报错
配置完成
在server1里面添加数据,可以在server2,server3看到
安装高可用集群软件
server1:
mha4mysql-node-0.56-0.el6.noarch.rpm
perl-Config-Tiny-2.12-7.1.el6.noarch.rpm
perl-Email-Date-Format-1.002-5.el6.noarch.rpm
perl-Log-Dispatch-2.27-1.el6.noarch.rpm
perl-Mail-Sender-0.8.16-3.el6.noarch.rpm
perl-Mail-Sendmail-0.79-12.el6.noarch.rpm
perl-MIME-Lite-3.027-2.el6.noarch.rpm
perl-MIME-Types-1.28-2.el6.noarch.rpm
perl-Parallel-ForkManager-0.7.9-1.el6.noarch.rpm
mha4mysql-manager-0.56-0.el6.noarch.rpm
server2,server3:
mha4mysql-node-0.56-0.el6.noarch.rpm
配置高可用集群
server1:
mkdir /etc/masterha
[root@server1 masterha]# vim app1.cnf
[server default]
manager_workdir=/etc/masterha/
manager_log=/etc/masterha/app1.log
master_binlog_dir=/var/lib/mysql
#master_ip_failover_script=/etc/masterha/master_ip_failover
#master_ip_online_change_script=/etc/masterha/master_ip_online_change
#report_script=/usr/local/send_report
password=Zming=1998
user=root
ping_interval=1
remote_workdir=/tmp
repl_password=Zming=1998
repl_user=rep
ssh_user=root
[server1]
hostname=172.25.28.1
port=3306
[server2]
hostname=172.25.28.2
port=3306
#candidate_master=1
#check_repl_delay=0
[server3]
hostname=172.25.28.3
port=3306server1的两个脚本检查
###1,免密
[root@server1 ~]# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
/root/.ssh/id_rsa already exists.
Overwrite (y/n)? y
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
e4:46:58:ca:8a:14:63:db:f2:9b:bd:67:18:e9:2b:8d root@server1
The key's randomart image is:
+--[ RSA 2048]----+
| + . |
| . = . + |
| + . + o |
| . + . + |
| . o .S |
| +o. |
| o+.o |
| E +.o |
| .o+ |
+-----------------+
[root@server1 ~]#
[root@server1 ~]# ssh-copy-id server1
The authenticity of host 'server1 (172.25.28.1)' can't be established.
RSA key fingerprint is 09:08:f5:72:ac:cd:2a:7d:d8:11:20:3c:66:3b:b3:5e.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'server1,172.25.28.1' (RSA) to the list of known hosts.
root@server1's password:
Now try logging into the machine, with "ssh 'server1'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[root@server1 ~]# ssh-copy-id 172.25.28.1
Now try logging into the machine, with "ssh '172.25.28.1'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[root@server1 ~]# scp -r .ssh/ server2:
root@server2's password:
known_hosts 100% 1965 1.9KB/s 00:00
id_rsa 100% 1671 1.6KB/s 00:00
id_rsa.pub 100% 394 0.4KB/s 00:00
authorized_keys 100% 1784 1.7KB/s 00:00
[root@server1 ~]# scp -r .ssh/ server3:
root@server3's password:
known_hosts 100% 1965 1.9KB/s 00:00
id_rsa 100% 1671 1.6KB/s 00:00
id_rsa.pub 100% 394 0.4KB/s 00:00
authorized_keys 100% 1784 1.7KB/s 00:00
免密互相连接测试:
[root@server1 ~]# ssh server2
Last login: Sat Aug 11 09:05:58 2018 from 172.25.28.250
[root@server2 ~]# logout
Connection to server2 closed.
[root@server1 ~]# ssh server3
Last login: Sat Aug 11 09:06:12 2018 from 172.25.28.250
[root@server3 ~]# logout
Connection to server3 closed.
[root@server1 ~]# ssh 172.25.28.2
Last login: Sat Aug 11 11:07:57 2018 from server1
[root@server2 ~]# logout
Connection to 172.25.28.2 closed.
[root@server1 ~]# ssh 172.25.28.3
Last login: Sat Aug 11 11:08:01 2018 from server1
[root@server3 ~]# logout
Connection to 172.25.28.3 closed.
[root@server2 ~]# ssh server1
[root@server1 ~]# logout
Connection to server1 closed.
[root@server2 ~]# ssh server3
Last login: Sat Aug 11 11:08:12 2018 from server1
[root@server3 ~]# logout
Connection to server3 closed.
[root@server2 ~]# ssh 172.25.28.1
[root@server1 ~]# logout
Connection to 172.25.28.1 closed.
[root@server2 ~]# ssh 172.25.28.3
Last login: Sat Aug 11 11:08:29 2018 from server2
[root@server3 ~]# logout
Connection to 172.25.28.3 closed.
[root@server3 ~]# ssh server1
[root@server1 ~]# logout
Connection to server1 closed.
[root@server3 ~]# ssh server2
Last login: Sat Aug 11 11:08:27 2018 from server2
[root@server2 ~]# logout
Connection to server2 closed.
[root@server3 ~]# ssh 172.25.28.1
[root@server1 ~]# logout
Connection to 172.25.28.1 closed.
[root@server3 ~]# ssh 172.25.28.2
Last login: Sat Aug 11 11:08:54 2018 from server3
[root@server2 ~]# logout
Connection to 172.25.28.2 closed.
serevr1
管理节点脚本验证:
[root@server1 ~]# masterha_check_ssh --conf=/etc/masterha/app1.cnf
Sat Aug 11 11:11:10 2018 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Sat Aug 11 11:11:10 2018 - [info] Reading application default configuration from /etc/masterha/app1.cnf..
Sat Aug 11 11:11:10 2018 - [info] Reading server configuration from /etc/masterha/app1.cnf..
Sat Aug 11 11:11:10 2018 - [info] Starting SSH connection tests..
Sat Aug 11 11:11:10 2018 - [debug]
Sat Aug 11 11:11:10 2018 - [debug] Connecting via SSH from [email protected](172.25.28.1:22) to [email protected](172.25.28.2:22)..
Sat Aug 11 11:11:10 2018 - [debug] ok.
Sat Aug 11 11:11:10 2018 - [debug] Connecting via SSH from [email protected](172.25.28.1:22) to [email protected](172.25.28.3:22)..
Sat Aug 11 11:11:10 2018 - [debug] ok.
Sat Aug 11 11:11:11 2018 - [debug]
Sat Aug 11 11:11:10 2018 - [debug] Connecting via SSH from [email protected](172.25.28.2:22) to [email protected](172.25.28.1:22)..
Sat Aug 11 11:11:10 2018 - [debug] ok.
Sat Aug 11 11:11:10 2018 - [debug] Connecting via SSH from [email protected](172.25.28.2:22) to [email protected](172.25.28.3:22)..
Sat Aug 11 11:11:10 2018 - [debug] ok.
Sat Aug 11 11:11:11 2018 - [debug]
Sat Aug 11 11:11:11 2018 - [debug] Connecting via SSH from [email protected](172.25.28.3:22) to [email protected](172.25.28.1:22)..
Sat Aug 11 11:11:11 2018 - [debug] ok.
Sat Aug 11 11:11:11 2018 - [debug] Connecting via SSH from [email protected](172.25.28.3:22) to [email protected](172.25.28.2:22)..
Sat Aug 11 11:11:11 2018 - [debug] ok.
Sat Aug 11 11:11:11 2018 - [info] All SSH connection tests passed successfully.
###2,健康检查
可以直接运行脚本,根据报错解决问题
[root@server1 ~]# masterha_check_repl -conf=/etc/masterha/app1.cnf
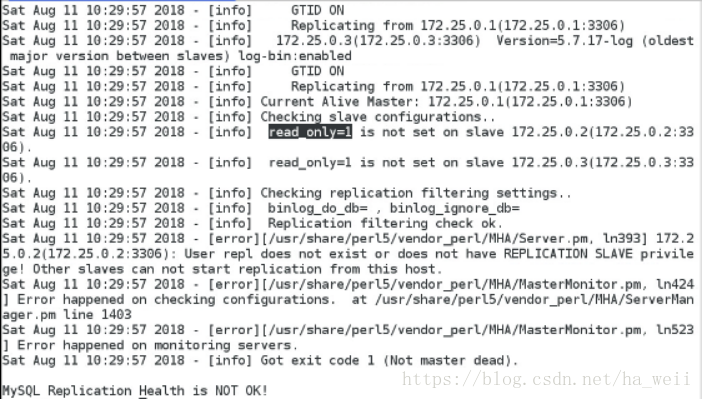
server2,server3:
在slave里面设置为只读
mysql> set global read_only=1;
Query OK, 0 rows affected (0.00 sec)
read_only不要直接写在my.cnf
server1:
(一般出现这样错误的原因分析
Sat Aug 11 11:31:06 2018 - [error][/usr/share/perl5/vendor_perl/MHA/ServerManager.pm, ln301] Got MySQL error when connecting 172.25.28.3(172.25.28.3:3306) :1045:Access denied for user 'root'@'server1' (using password: YES), but this is not a MySQL crash. Check MySQL server settings.
at /usr/share/perl5/vendor_perl/MHA/ServerManager.pm line 297
)
mysql> grant all privileges on *.* to root@'%' identified by 'Zming=1998';
Query OK, 0 rows affected, 1 warning (0.05 sec)
在一个节点里面做授权就行,其他会同步
脚本健康验证
[root@server1 ~]# masterha_check_repl -conf=/etc/masterha/app1.cnf
Sat Aug 11 11:33:45 2018 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Sat Aug 11 11:33:45 2018 - [info] Reading application default configuration from /etc/masterha/app1.cnf..
Sat Aug 11 11:33:45 2018 - [info] Reading server configuration from /etc/masterha/app1.cnf..
Sat Aug 11 11:33:45 2018 - [info] MHA::MasterMonitor version 0.56.
Sat Aug 11 11:33:45 2018 - [info] GTID failover mode = 1
Sat Aug 11 11:33:45 2018 - [info] Dead Servers:
Sat Aug 11 11:33:45 2018 - [info] Alive Servers:
Sat Aug 11 11:33:45 2018 - [info] 172.25.28.1(172.25.28.1:3306)
Sat Aug 11 11:33:45 2018 - [info] 172.25.28.2(172.25.28.2:3306)
Sat Aug 11 11:33:45 2018 - [info] 172.25.28.3(172.25.28.3:3306)
Sat Aug 11 11:33:45 2018 - [info] Alive Slaves:
Sat Aug 11 11:33:45 2018 - [info] 172.25.28.2(172.25.28.2:3306) Version=5.7.17-log (oldest major version between slaves) log-bin:enabled
Sat Aug 11 11:33:45 2018 - [info] GTID ON
Sat Aug 11 11:33:45 2018 - [info] Replicating from 172.25.28.1(172.25.28.1:3306)
Sat Aug 11 11:33:45 2018 - [info] 172.25.28.3(172.25.28.3:3306) Version=5.7.17-log (oldest major version between slaves) log-bin:enabled
Sat Aug 11 11:33:45 2018 - [info] GTID ON
Sat Aug 11 11:33:45 2018 - [info] Replicating from 172.25.28.1(172.25.28.1:3306)
Sat Aug 11 11:33:45 2018 - [info] Current Alive Master: 172.25.28.1(172.25.28.1:3306)
Sat Aug 11 11:33:45 2018 - [info] Checking slave configurations..
Sat Aug 11 11:33:45 2018 - [info] read_only=1 is not set on slave 172.25.28.3(172.25.28.3:3306).
Sat Aug 11 11:33:45 2018 - [info] Checking replication filtering settings..
Sat Aug 11 11:33:45 2018 - [info] binlog_do_db= , binlog_ignore_db=
Sat Aug 11 11:33:45 2018 - [info] Replication filtering check ok.
Sat Aug 11 11:33:45 2018 - [info] GTID (with auto-pos) is supported. Skipping all SSH and Node package checking.
Sat Aug 11 11:33:45 2018 - [info] Checking SSH publickey authentication settings on the current master..
Sat Aug 11 11:33:45 2018 - [info] HealthCheck: SSH to 172.25.28.1 is reachable.
Sat Aug 11 11:33:45 2018 - [info]
172.25.28.1(172.25.28.1:3306) (current master)
+--172.25.28.2(172.25.28.2:3306)
+--172.25.28.3(172.25.28.3:3306)
Sat Aug 11 11:33:45 2018 - [info] Checking replication health on 172.25.28.2..
Sat Aug 11 11:33:45 2018 - [info] ok.
Sat Aug 11 11:33:45 2018 - [info] Checking replication health on 172.25.28.3..
Sat Aug 11 11:33:45 2018 - [info] ok.
Sat Aug 11 11:33:45 2018 - [warning] master_ip_failover_script is not defined.
Sat Aug 11 11:33:45 2018 - [warning] shutdown_script is not defined.
Sat Aug 11 11:33:45 2018 - [info] Got exit code 0 (Not master dead).
MySQL Replication Health is OK.
高可用集群测试:
在server1创建表,server2,server3可以看见,此时master是server1
mysql> create table westos.userlist(
-> username varchar(10) not null,
-> password varchar(15) not null);
Query OK, 0 rows affected (0.57 sec)
mysql> insert into westos.userlist values('user1','111');
Query OK, 1 row affected (0.08 sec)
一,管理节点上手动切换:
server1
masterha_master_switch --conf=/etc/masterha/app1.cnf --master_state=alive --new_master_host=172.25.28.2 --new_master_port=3306 --orig_master_is_new_slave此时server2:升级为master
server3,server1:
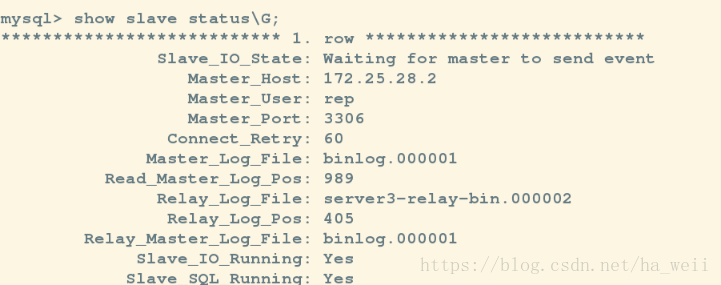
在server2上插入数据

server1,server3都可以看到
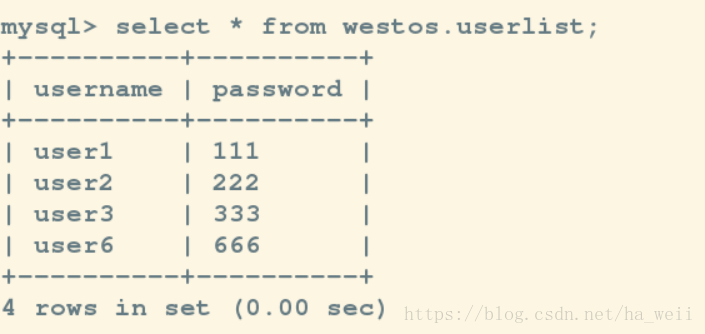
二,故障自动切换:
管理节点上打开监控:
nohup masterha_manager --conf=/etc/masterha/app1.cnf --ignore_last_failover & 会在当前目录下生成nohup.out文件
master端:
kill -9 mysql的两个进程
管理节点:cat app1.log会显示切换成功与否的日志
(此时管理终端会出现:
[root@server1 masterha]# ls
app1.cnf app1.failover.complete app1.log nohup.out
[1]- Done nohup masterha_manager --conf=/etc/masterha/app1.cnf --ignore_last_failover
[2]+ Exit 1 nohup masterha_manager --conf=/etc/masterha/app1.cnf --ignore_last_failover
)
----- Failover Report -----
app1: MySQL Master failover 172.25.28.2(172.25.28.2:3306) to 172.25.28.1(172.25.28.1:3306) succeeded
Master 172.25.28.2(172.25.28.2:3306) is down!
Check MHA Manager logs at server1:/etc/masterha/app1.log for details.
Started automated(non-interactive) failover.
Selected 172.25.28.1(172.25.28.1:3306) as a new master.
172.25.28.1(172.25.28.1:3306): OK: Applying all logs succeeded.
172.25.28.3(172.25.28.3:3306): OK: Slave started, replicating from 172.25.28.1(172.25.28.1:3306)
172.25.28.1(172.25.28.1:3306): Resetting slave info succeeded.
Master failover to 172.25.28.1(172.25.28.1:3306) completed successfully.在新的master上建立数据

仅存的一个slave上可以查看
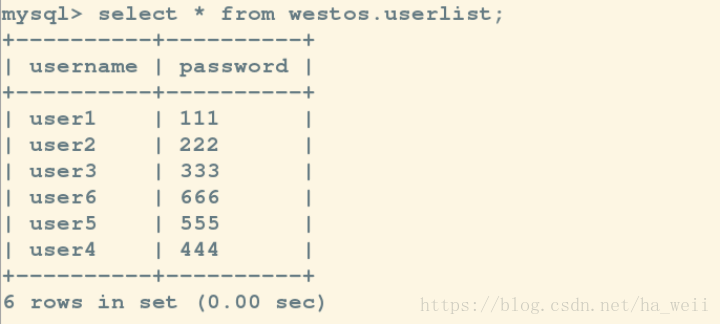
三,在线热切换:
先把之前的kill的server2启动,此时查看数据肯定是没有在它死亡期间master建立的
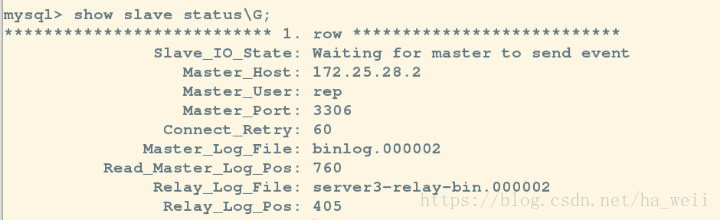
1,设置server2的master为server1
change master to master_host='172.25.28.1',master_user='rep',master_password='Zming=1998',master_auto_position=1;
mysql> start slave;
Query OK, 0 rows affected (0.05 sec)
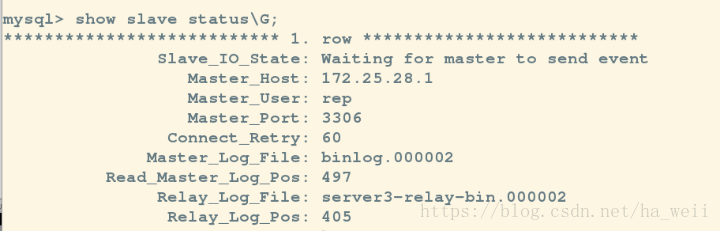
mysql> show slave status\G;
现在就可以看到数据都是同步的了
注意:每次切换都应该添加一些数据,这样更新日志。
直接在停掉matser端的mysql
在管理节点
[root@server1 masterha]# masterha_master_switch --master_state=dead --conf=/etc/masterha/app1.cnf --dead_master_host=172.25.28.1 --dead_master_port=3306 --new_master_host=172.25.28.2 --new_master_port=3306 --ignore_last_failoverserver2:
server3:
启动之前停止的master,配置其master为server2
[root@server1 masterha]# /etc/init.d/mysqld start
Starting mysqld: [ OK ]
[root@server1 masterha]# mysql -pZming=1998
server2:插入数据
mysql> insert into westos.userlist values('user9','999');
Query OK, 1 row affected (0.07 sec)
在server3,server1查看:
四,脚本自动切换:
修改/etc/my.cnf
1,master_ip_failover_script=/etc/masterha/master_ip_failover
脚本内容为
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
my $vip = '172.25.28.100/24';
my $ssh_start_vip = "/sbin/ip addr add $vip dev eth0";
my $ssh_stop_vip = "/sbin/ip addr del $vip dev eth0";
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
);
exit &main();
sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
sub stop_vip() {
return 0 unless ($ssh_user);
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
2,master_ip_online_change_script=/etc/masterha/master_ip_online_change
脚本内容为
#!/usr/bin/env perl
use strict;
use warnings FATAL =>'all';
use Getopt::Long;
my $vip = '172.25.28.100/24'; # Virtual IP
my $ssh_start_vip = "/sbin/ip addr add $vip dev eth0";
my $ssh_stop_vip = "/sbin/ip addr del $vip dev eth0";
my $exit_code = 0;
my (
$command, $orig_master_is_new_slave, $orig_master_host,
$orig_master_ip, $orig_master_port, $orig_master_user,
$orig_master_password, $orig_master_ssh_user, $new_master_host,
$new_master_ip, $new_master_port, $new_master_user,
$new_master_password, $new_master_ssh_user,
);
GetOptions(
'command=s' => \$command,
'orig_master_is_new_slave' => \$orig_master_is_new_slave,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'orig_master_user=s' => \$orig_master_user,
'orig_master_password=s' => \$orig_master_password,
'orig_master_ssh_user=s' => \$orig_master_ssh_user,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
'new_master_user=s' => \$new_master_user,
'new_master_password=s' => \$new_master_password,
'new_master_ssh_user=s' => \$new_master_ssh_user,
);
exit &main();
sub main {
#print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
# $orig_master_host, $orig_master_ip, $orig_master_port are passed.
# If you manage master ip address at global catalog database,
# invalidate orig_master_ip here.
my $exit_code = 1;
eval {
print "\n\n\n***************************************************************\n";
print "Disabling the VIP - $vip on old master: $orig_master_host\n";
print "***************************************************************\n\n\n\n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
# all arguments are passed.
# If you manage master ip address at global catalog database,
# activate new_master_ip here.
# You can also grant write access (create user, set read_only=0, etc) here.
my $exit_code = 10;
eval {
print "\n\n\n***************************************************************\n";
print "Enabling the VIP - $vip on new master: $new_master_host \n";
print "***************************************************************\n\n\n\n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
`ssh $orig_master_ssh_user\@$orig_master_host \" $ssh_start_vip \"`;
exit 0;
}
else {
&usage();
exit 1;
}
}
# A simple system call that enable the VIP on the new master
sub start_vip() {
`ssh $new_master_ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
# A simple system call that disable the VIP on the old_master
sub stop_vip() {
`ssh $orig_master_ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
[root@server1 masterha]# chmod +x master_ip_online_change master_ip_failover
在master server2上添加vip,这里我们没有keepalived,所以需要手动在master上添加
[root@server2 ~]# ip addr add 172.25.28.100/24 dev eth0
[root@server2 ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:2c:0a:1d brd ff:ff:ff:ff:ff:ff
inet 172.25.28.2/24 brd 172.25.28.255 scope global eth0
inet 172.25.28.100/24 scope global secondary eth0
inet6 fe80::5054:ff:fe2c:a1d/64 scope link
valid_lft forever preferred_lft forever真机作为客户端访问的是vip
[root@server1 masterha]# nohup masterha_manager --conf=/etc/masterha/app1.cnf --ignore_last_failover &
[1] 5022
[root@server1 masterha]# nohup: ignoring input and appending output to `nohup.out'
直接kill master端的mysql进程
管理节点查看:
[root@server1 masterha]# cd /etc/masterha/
[1]+ Done nohup masterha_manager --conf=/etc/masterha/app1.cnf --ignore_last_failover
[root@server1 masterha]# ls
app1.cnf app1.log master_ip_online_change
app1.failover.complete master_ip_failover nohup.out
[root@server1 masterha]# cat app1.log
切换成功
----- Failover Report -----
app1: MySQL Master failover 172.25.28.2(172.25.28.2:3306) to 172.25.28.1(172.25.28.1:3306) succeeded
Master 172.25.28.2(172.25.28.2:3306) is down!
Check MHA Manager logs at server1:/etc/masterha/app1.log for details.
Started automated(non-interactive) failover.
Invalidated master IP address on 172.25.28.2(172.25.28.2:3306)
Selected 172.25.28.1(172.25.28.1:3306) as a new master.
172.25.28.1(172.25.28.1:3306): OK: Applying all logs succeeded.
172.25.28.1(172.25.28.1:3306): OK: Activated master IP address.
172.25.28.3(172.25.28.3:3306): OK: Slave started, replicating from 172.25.28.1(172.25.28.1:3306)
172.25.28.1(172.25.28.1:3306): Resetting slave info succeeded.
Master failover to 172.25.28.1(172.25.28.1:3306) completed successfully.
server3:
客户端正常使用:
vip 也自动转到了master server1
[root@server1 masterha]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:d4:f7:b9 brd ff:ff:ff:ff:ff:ff
inet 172.25.28.1/24 brd 172.25.28.255 scope global eth0
inet 172.25.28.100/24 scope global secondary eth0
inet6 fe80::5054:ff:fed4:f7b9/64 scope link
valid_lft forever preferred_lft forever
[root@server2 ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:2c:0a:1d brd ff:ff:ff:ff:ff:ff
inet 172.25.28.2/24 brd 172.25.28.255 scope global eth0
inet6 fe80::5054:ff:fe2c:a1d/64 scope link
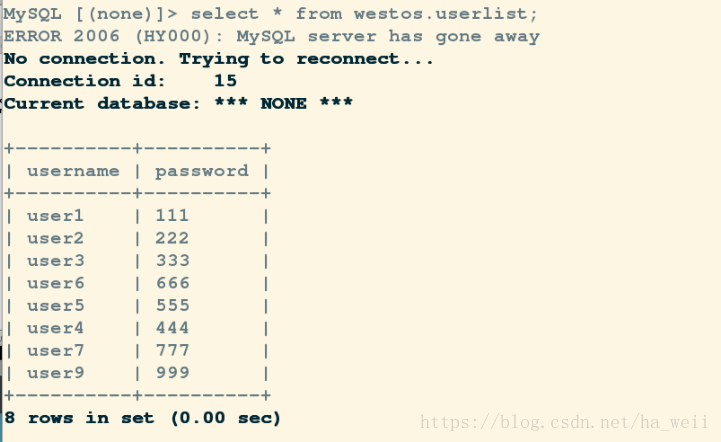
valid_lft forever preferred_lft forevermaster插入数据:
mysql> insert into westos.userlist values('user10','1010');
Query OK, 1 row affected (0.14 sec)
客户端,slave:
启动被kill的server2
配置server2的master为新的masetr
change master to master_host='172.25.28.1',master_user='rep',master_password='Zming=1998',master_auto_position=1;
mysql> start slave;
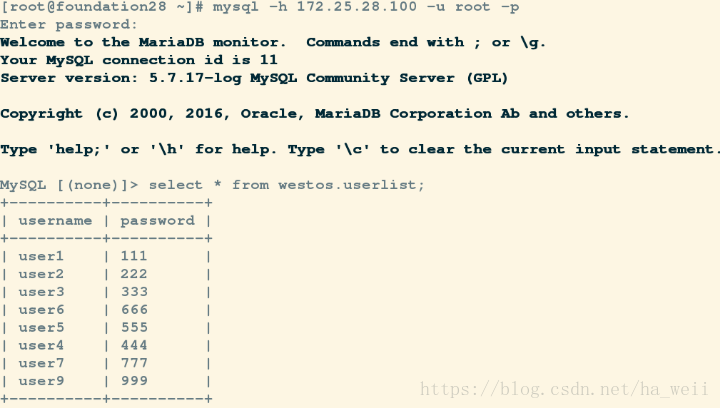
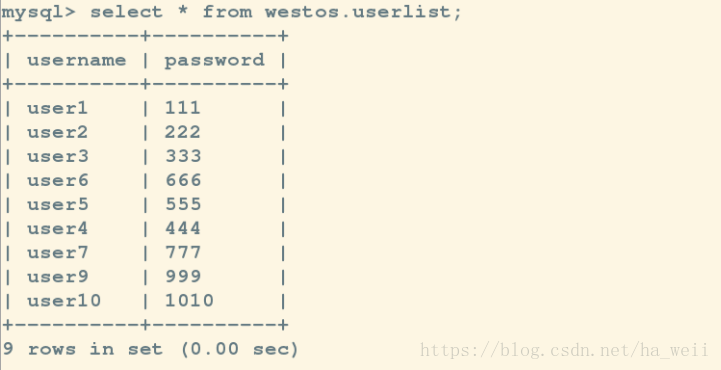
Query OK, 0 rows affected (0.05 sec)
mysql> show slave status\G;已经可以看到在它死亡期间添加的数据
mysql> select * from westos.userlist;
+----------+----------+
| username | password |
+----------+----------+
| user1 | 111 |
| user2 | 222 |
| user3 | 333 |
| user6 | 666 |
| user5 | 555 |
| user4 | 444 |
| user7 | 777 |
| user9 | 999 |
| user10 | 1010 |
+----------+----------+
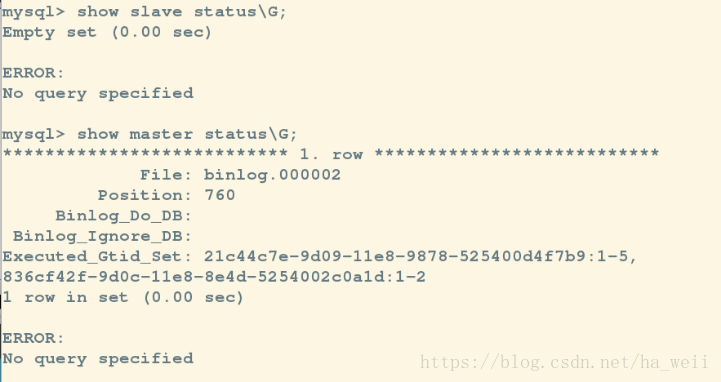
9 rows in set (0.00 sec)注意:在做change master之前可以
show tables;
select * from gtid_executed;查看
change master之后就会同步这里的interval_end数字就会变化,如果没有变化,用这个命令查看日志
[root@server1 mysql]# mysqlbinlog --base64-output=DECODE-ROWS -v mysql
五,自动切换发送邮件
手动切换才发送
vim /etc/masterha/app1.cnf
添加
report_script=/usr/local/send_report
脚本内容
#!/usr/bin/perl
# Copyright (C) 2011 DeNA Co.,Ltd.
#
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation; either version 2 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc.,
# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
## Note: This is a sample script and is not complete. Modify the script based on your environment.
use strict;
use warnings FATAL => 'all';
use Mail::Sender;
use Getopt::Long;
#new_master_host and new_slave_hosts are set only when recovering master succeeded
my ( $dead_master_host, $new_master_host, $new_slave_hosts, $subject, $body );
my $smtp='smtp.163.com';
my $mail_from='[email protected]'; ####这部分需要修改
my $mail_user='[email protected]';
my $mail_pass='password';
my $mail_to='[email protected]';
GetOptions(
'orig_master_host=s' => \$dead_master_host,
'new_master_host=s' => \$new_master_host,
'new_slave_hosts=s' => \$new_slave_hosts,
'subject=s' => \$subject,
'body=s' => \$body,
);
mailToContacts($smtp,$mail_from,$mail_user,$mail_pass,$mail_to,$subject,$body);
sub mailToContacts {
my ( $smtp, $mail_from, $user, $passwd, $mail_to, $subject, $msg ) = @_;
open my $DEBUG, "> /tmp/monitormail.log"
or die "Can't open the debug file:$!\n";
my $sender = new Mail::Sender {
ctype => 'text/plain; charset=utf-8',
encoding => 'utf-8',
smtp => $smtp,
from => $mail_from,
auth => 'LOGIN',
TLS_allowed => '0',
authid => $user,
authpwd => $passwd,
to => $mail_to,
subject => $subject,
debug => $DEBUG
};
$sender->MailMsg(
{ msg => $msg,
debug => $DEBUG
}
) or print $Mail::Sender::Error;
return 1;
}
# Do whatever you want here
exit 0;需要修改脚本的部分内容,必须是163邮箱
/etc/masterha/app1.cnf文件解释
[server default]
manager_workdir=/var/log/masterha/app1.log //设置manager的工作目录
manager_log=/var/log/masterha/app1/manager.log //设置manager的日志
master_binlog_dir=/data/mysql //设置master 保存binlog的位置,以便MHA可以找到master的日志,我这里的也就是mysql的数据目录
master_ip_failover_script= /usr/local/bin/master_ip_failover //设置自动failover时候的切换脚本
master_ip_online_change_script= /usr/local/bin/master_ip_online_change //设置手动切换时候的切换脚本
password=123456 //设置mysql中root用户的密码,这个密码是前文中创建监控用户的那个密码
user=root 设置监控用户root
ping_interval=1 //设置监控主库,发送ping包的时间间隔,默认是3秒,尝试三次没有回应的时候自动进行railover
remote_workdir=/tmp //设置远端mysql在发生切换时binlog的保存位置
repl_password=123456 //设置复制用户的密码
repl_user=repl //设置复制环境中的复制用户名
report_script=/usr/local/send_report //设置发生切换后发送的报警的脚本
secondary_check_script= /usr/local/bin/masterha_secondary_check -s server03 -s server02
shutdown_script="" //设置故障发生后关闭故障主机脚本(该脚本的主要作用是关闭主机放在发生脑裂,这里没有使用)
ssh_user=root //设置ssh的登录用户名
[server1]
hostname=192.168.0.50
port=3306
[server2]
hostname=192.168.0.60
port=3306
candidate_master=1 //设置为候选master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slave
check_repl_delay=0 //默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
[server3]
hostname=192.168.0.70
port=3306