摘要: 在这项工作中,我们研究了在训练端到端去雾神经网络时用感知导出的损失函数(SSIM,MS-SSIM等)替换L2损失的可能性。客观实验结果表明,与现有技术的端到端去雾神经网络(AOD-Net)使用L2损失相比,通过仅改变损失函数,我们可以在RESIDE数据集中设置的SOTS上获得显着更高的PSNR和SSIM分数。我们获得的最佳PSNR为23.50(相对改善率为4.2%),我们获得的最佳SSIM为0.8747(相对改善率为2.3%)。
简介
由于存在空气污染——灰尘,雾和烟雾,在室外环境中拍摄的图像通常会包含复杂的,非线性的和数据相关的噪声,称为雾,这会对许多高级计算机视觉任务提出挑战,例如目标检测和识别。以自动驾驶为例,有雾或模糊的天气会掩盖车载摄像机的视野,并通过雾颗粒的光散射造成对象的对比度损失,为自驾车任务增加了极大的困难。因此,去雾是一种非常理想的图像恢复技术,以增强计算摄影和计算机视觉任务的更好结果。
早期的去雾方法通常需要额外的信息,例如通过比较同一场景的多个不同图像来给出或捕获场景深度[1,2,3]。虽然这些方法可以有效地增强有雾图像的可见性,但是它们的易处理性受到限制,因为在实践中并不总是可获得所需的附加信息或多个图像。
为了解决这个问题,旨在从观察到的有雾图像恢复基础清晰图像的单图像去雾系统对于实际应用更加可行,并且近年来研究人员越来越关注这一方面。 传统的单幅图像去雾方法利用自然图像的同步和静态分析[4,5,6,7]。最近,基于神经网络[8,9,10]的去雾算法已经显示出最先进的性能,其中AOD-Net [10]具有训练端到端系统的能力,同时在多个评估指标上优于其他系统。AOD-Net最大限度地降低了有雾图像和清晰图像之间差异的L2范数。然而,L2范数受到一些已知的局限性的影响,这些局限性可能使AOD-Net的去雾图像输出远离最佳质量,特别是考虑到它与人类对图像质量的感知的相关性[11]。另一方面,L2范数隐含地假设白高斯噪声,这是一种过于简单的情况,在一般的除雾情况下无效。另一方面,L2独立地处理噪声对图像的局部特征(例如结构信息,亮度和对比度)的影响。然而,根据[12],人类视觉系统(HVS)对噪声的敏感性取决于视觉的局部特性和结构。
结构相似性指数(SSIM)被广泛用作从更感知的角度评估图像处理算法的度量。此外,它还具有差异性,可用作功能。因此,在这项工作中,受益于[13],我们建议使用与人类感知相匹配的损失函数(例如,SSIM [12],MS-SSIM [14])基于AOD-Net开发的去雾神经网络的主要目标[10]]。我们称之为感知辅助单幅图像去雾网络:PAD-Net。我们假设即使不改变神经网络架构,PAD-Net也会比基线AOD-Net带来更好的去雾性能。
相关工作
在本节中,我们简要总结了之前工作中提出的单幅图像去雾方法,并比较了它们的优点和缺点。然后,我们提出了感知引导的端到端去雾网络,与基线AOD-Net相比,提高了学习性能。
大气散射模型已广泛应用于以前的去雾工作[15,16,17]:
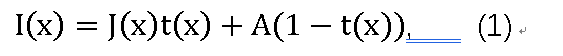
其中x是有雾图像中的像素,I(x)是有雾图像,并且J(x)是要恢复的清晰图像。参数A表示全局大气光,t(x)是介质传输图,表示为:
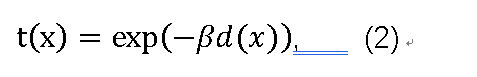
其中β是大气的散射系数,d(x)表示物体和相机之间的距离。
去雾算法的成功的关键是恢复传输图t(x),大多数去雾方法通过物理接地的先验或数据驱动的方法对其进行了聚焦。
传统的单幅图像去雾方法通常利用自然图像先验并进行静态分析。例如,[4,5]证明暗通道先验(DCP)对于计算传输图是有用的。[6]提出了一种颜色衰减先验,并为有雾图像的场景深度创建了一个线性模型,以允许一种有效的监督参数学习方法。[7]提出了一种基于观察的非局部先验,即给定聚类中的像素 通常是非局部的,清晰图像中的每个颜色簇都成为RGB空间中的雾浓度线。
最近,在许多其他计算机视觉任务中证明成功之后,CNN已经应用于去雾。[9]利用多尺度CNN(MSCNN)预测整个图像的粗尺度整体传输图并在本地重新细化。[8]提出了DehazeNet,一种可训练的传输图估计器,并结合估计的全球大气光恢复清晰的图像。这两种方法都首先从CNN学习传输图,并用单独计算的大气光恢复无雾图像。此外,[18]提出了一个完整的端到端去雾网络名称AOD-Net,它将有雾图像作为输入并直接生成清晰的图像输出。
在这个项目中,我们采用了[10]中提出的变换大气散射模型和卷积网络结构,旨在通过利用感知驱动的损失函数来改善其性能。
提出的工作
在本节中,解释了提议的PAD-Net。我们首先介绍了基于它的变换大气散射模型和去雾网络结构设计,我们采用[10]中的工作来促进端到端单图像去雾。然后,我们讨论将在我们的项目中探索的感知驱动的损失函数。
端对端去雾网络设计
基于大气散射模型(1),我们网络生成的清晰图像可以表示为:
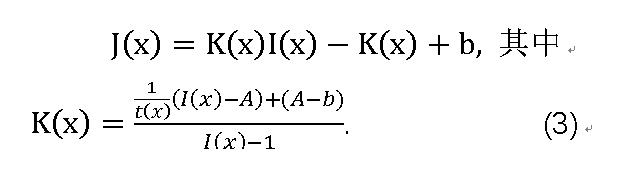
其中b是恒定偏差,其默认值设置为1。这里,核心思想是将(1)中t(x)和A中的两个参数统一为一个公式,即K(x),并直接最小化重建图像像素域中的误差。由于K(x)取决于输入I(x),因此我们构建了一个输入自适应深度模型,并通过最小化其输出J(x)和地面实况清晰图像之间的重建误差来训练模型。
因此,所提出的深度神经网络由两个主要部分组成:用于评估(3)中具有超卷积层的K(x)的K估计模块,以及随后通过逐元素计算产生恢复清晰图像的图像生成模块。PAD-Net的整个网络图如图1所示。
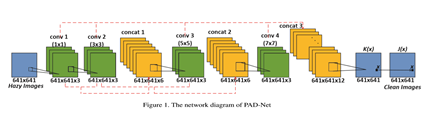
如图1所示,五个卷积层采用不同的滤波器尺寸实现,以捕获输入有雾图像的多尺度特征,并与中间层连接,以补偿卷积过程中的信息丢失,这受到[8,9]的启发。然后将来自网络的输出图像(即,(3)中的J(x))与损耗层处的地面实况清晰图像进行比较,以计算用于反向传播的误差函数。这种端到端的去雾网络可以很容易地与其他深度模型嵌入,作为高级计算机视觉任务的一个阶段,例如目标检测和目标分类。
值得一提的是,继承自AOD-Net [10]的PAD-Net是一种轻量级网络,只有三个卷积核。事实上,如果我们分析大气散射模型((1)和(2)),我们可以发现模型中只有三个未知参数,β,A和d(x)。 在我们采用的基准RESIDE数据集[18]中,β和A是成对选择的常数,深度图d(x)可以从深度数据集(如NYU2 [19])计算或用卷积神经网络估计[20]。因此,去雾模型的复杂性相对较低。鉴于这一观察结果,在我们的工作中,我们在AOD-Net中保持过滤器数量的设置,以便在获得良好学习成果的同时促进快速训练。
感知损失函数
在损耗层,将研究不同的误差函数以优化图像去雾结果,并且将比较结果。在以下部分中,我们将介绍将在项目中检查的误差度量标准。我们展示了它们的关键特性以及如何计算它们的反向传播步骤的导数。这些损失函数将单独或联合在损耗层实施,详见第4节。
L2损失
由于其简单性和凸性,通常选择误差的L2范数作为图像去雾的损失函数[10]。L2规范惩罚大错误,但不管图像中的底层结构如何,它都更容忍小错误。结果,它有时会在恢复的图像上产生可见的斑点伪影。另一方面,HVS对无纹理区域中的亮度和颜色变化更敏感[21]。P区域的损失功能可以写成:
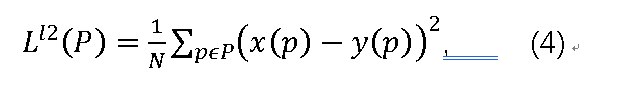
其中N是P区域像素的数量,p是像素的索引,x(p)和y(p)分别是生成图像和地面实况图像的像素值。由于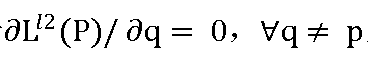 ,对于区域中的像素p,导数可以表示为:
,对于区域中的像素p,导数可以表示为:
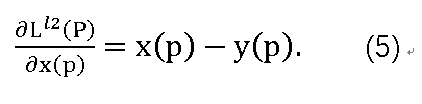
注意,即使L^l2 §是整个区域的函数,导数也会针对区域中的每个像素进行反向传播。
L1误差
研究L1误差是为了减少L2引入的伪像并带来不同的收敛特性。与L2范数不同,L1范数不会过度惩罚大错误。L1的误差函数为:
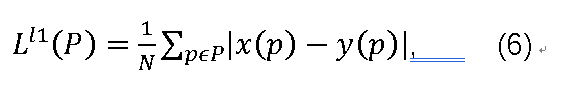
L1的导数也很简单。与L2范数类似,区域中某个像素的导数仅取决于其自身值与同一位置的地面实况值之间的差异,并且不依赖于同一区域中的其他像素。
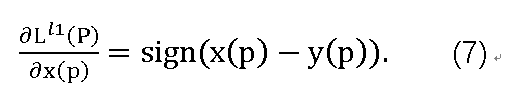
L^l1 §的导数不定义为0。但是,如果误差为0,我们不需要更新权重。 所以这里我们使用sign(0)= 0的约定。
SSIM
考虑到图像去雾是一种真实世界的应用程序,可以再现视觉上的清晰图像,因此像SSIM这样的感知动机度量值得研究。SSIM是基于感知的模型,其将图像降级视为结构信息中的感知变化,同时还结合重要的感知现象,包括亮度掩蔽和对比度掩蔽术语。继承(4)中x(p)和y(p)的定义,让μ_x,σ_x^2
和σ_xy为x的均值,x的方差,x和y的协方差。近似地,μ_x和σ_x^2可以被视为x的亮度和对比度的估计,并且μ_xy根据它们一起变化的趋势来测量x和y的结构相似性。然后,像素p的SSIM定义为:
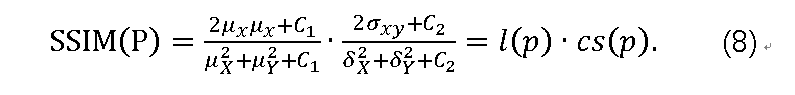
其中平均值和标准偏差用带有标准偏差σ_G的高斯滤波器G_σG计算,l(p)和cs(p)分别测量亮度的比较,以及与像素p处的x和y之间的结构相似性的组合对比度。然后可以将SSIM的损失函数定义为:
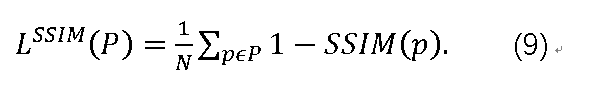
注意,(8)表示SSIM(p)的计算需要查看像素p的邻近,因为它涉及像素上的高斯滤波器G_σG的平均和标准偏差。这意味着无法在P的某些边界区域计算LSSIM(p)及其导数。