近期在阅读跨模态检索相关论文时,碰到很多处理文本的网络结构以及一些名词不是很了解,通过我的学习现在将这些知识点记录总结。本文中出现的图片来自于我学习的视频截屏:https://www.bilibili.com/video/BV1BR4y1g7LM?p=25&spm_id_from=pageDriver
目录
分词工具:Jieba分词(常用),SnowNLP,LTP,HanNLP。
-
文本处理的流程
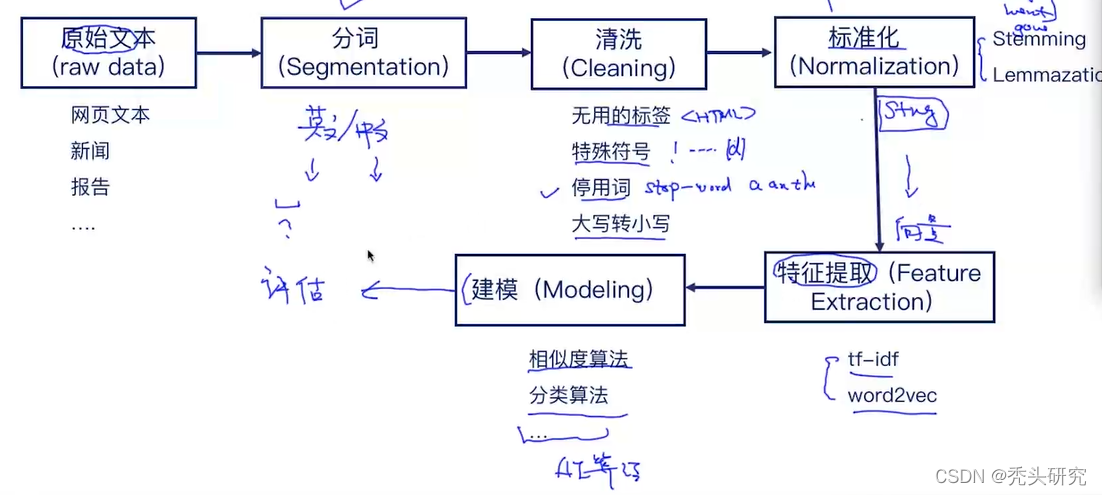
1、Word Segmentation(分词)
-
分词工具:Jieba分词(常用),SnowNLP,LTP,HanNLP。

当jieba本身词库中没有一些我们想要的词组的时候,他会把你原想要的词组也给拆了,比如上图中的“贪心学院”我们不想把他给拆分,这是就可以用“jieba.add_word(“贪心学院”)”语句把我们不想分割的词组添加进去。
-
分词的算法
1.最大匹配算法
1)前向最大匹配(forward-max matching)

先定义一个max_len最大的滑动长度,上图中例子定义为5,然后再例句中以5为单位进行选择词组,然后将这个词组依次和词典中的词语进行匹配,匹配一致的时候进行分割,就这样一致循环到句子结束。
2)后向最大匹配(backward-max matching)
后向匹配和前向匹配的过程类似,前向匹配从前到后,那后向匹配就是从后到前,算法过程和前向匹配差不多,不再赘述。
最大匹配算法的缺点:最大匹配算法是贪心的,只能达到局部最优;效率和时间复杂度取决于max_len,算法只能看到单词,不能考虑语义。
2.考虑语义的算法
算法思路:输入一个句子,生成所有可能的分割,然后利用“工具”选择其中一个最好的。其中在NLP中这个工具最经典的就是Language Model(语言模型)。
Language Model:可以计算出每个分割的概率,返回概率最大的那一项。 概率具体计算过程:统计每个单词出现的频率,然后根据独立得出每个单词的概率,然后再相乘。下图为举的例子。

上图中的概率相乘会出现一个问题,如果每个概率都很小,相乘会越来越小,会超出double或者float型的范围,产生溢出问题。为了解决这个问题,在概率前取log即可,让乘法变加法,如下图:

算法缺点:复杂度太高。
解决办法:维特比算法
取-log是因为习惯性的找最小,每一条路径是分词的路径,想要的路径是路径之和最小的那个路径。

下面问题就转换为解决最短路径的问题,核心是动态规划,即是把一个大的问题拆分为若干个小的子问题。采用一个一维数组把每个节点的数值存进去,这样避免重复计算,需要哪个节点的值直接取出来即可,这样大大减少了复杂度。

2、Spell Correction(拼写错误纠正)

在词典中进行循环,找出与输入的编辑距离最小的单词。根据动态规划算法计算出编辑距离:

上图中在词典中循环的方法时间复杂度很高,另一个新的方法可以解决这个问题:用户输入单词后,生成与此单词编辑距离为1和2的字符串,然后通过条件过滤,最后选择出最合适的字符串。
3、Filtering Words
把停用词以及出现频率很低的词汇过滤掉。
Stemming:one way to normalize,但是此方法并不能保证把单词转换为有效的原型,比如fly和flies可能转换为fli。
