版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/xianqianshi3004/article/details/88203206
针对文本预处理问题,我们经常用到几个常见的语言模型,这里我就不做过多的介绍,如果大家想了解可以参考我的这篇博客。
接下来本文主要才去用了Word2Vec模型进行文本预处理。
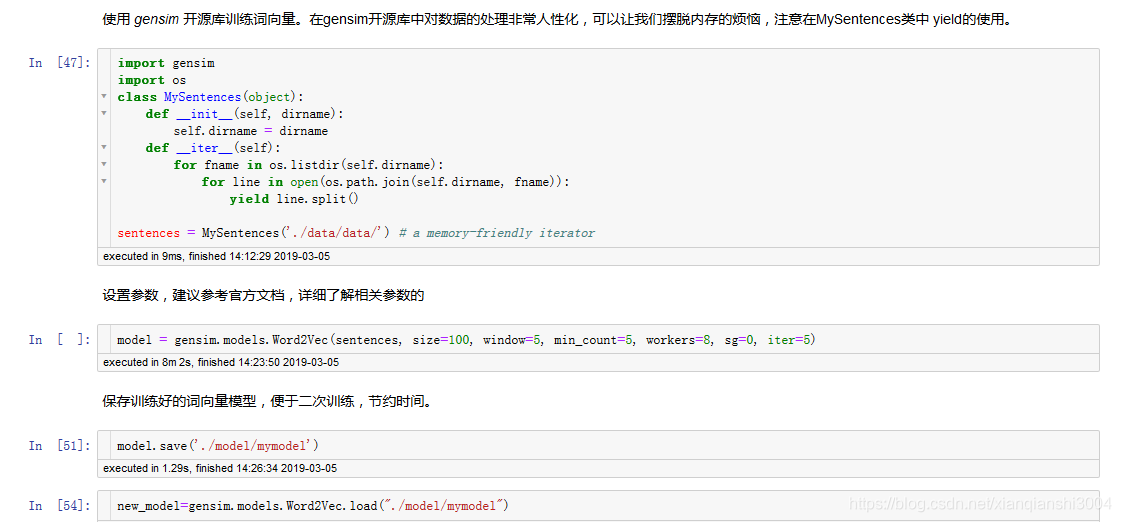
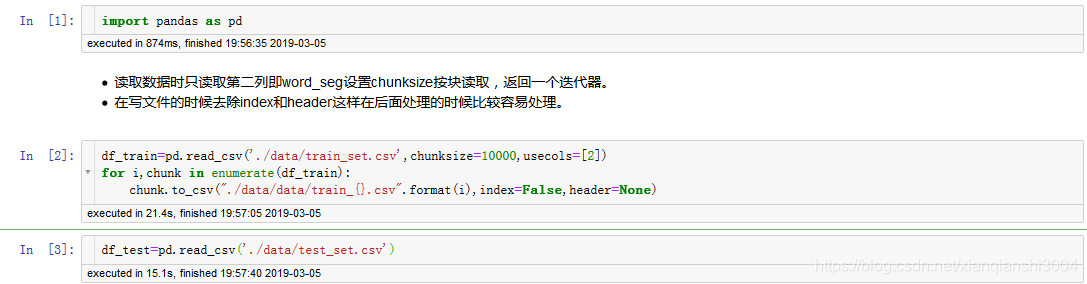
因为我的电脑内存只有八G,不能一下处理所有的数据,我采用了分批次训练的方法,先把文件切成小文件,然后依次去取,采用生成器的方法,每次读完就释放内存。
训练词向量