
背景:
本文针对GCN进行改进。用户的历史交互序列中,可能存在假阳性物品,会通过消息传递的方式对用户的兴趣表征造成污染。本文提出了一种软剪枝的方法,旨在切断与假阳性物品连接的边。形式上与GAT很相识,但性能却提升了很多,总的来说本文模型为:注意力+GNN。
方法:
用户/物品的特征表示构造如下:
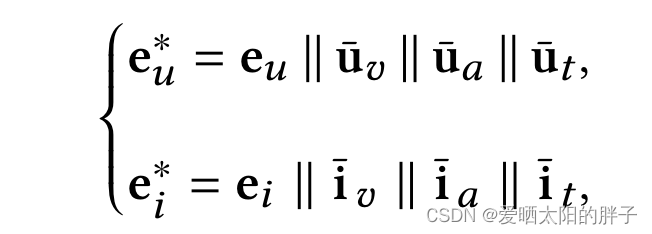
concatenate the multimodal features and the enriched ID embedding as a whole vector
让我们来剖析一下公式:
首先 ,其中
,
表示聚合了l跳邻居信息后的结果,可以看到,本文考虑了各层邻居的影响,将0……L层聚合结果求和作为最终的特征表示。
/
为初始的id embedding
公式是不是很简单,和GAT类似,都是在消息传递的时候添加了注意力。重头戏来了,让我们看一看注意力的计算方式。本文用的是短视屏数据集,对于短视频而言数据是多模态的(图像,声音,文字),以模态m为例,注意力分数计算公式如下:
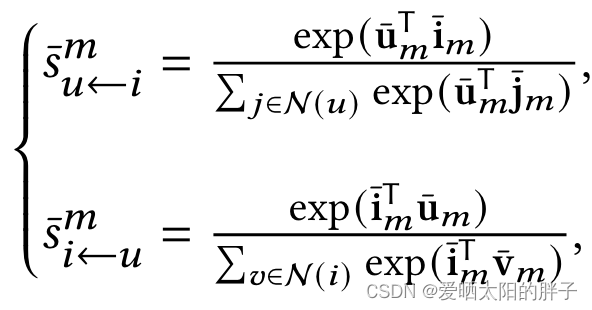
分别表示用户和物品在模态m上的特征表示。
对于物品来说,可以直接从原始数据上提取特征:
而用户特征是通过对交互物品的特征进行聚合得到的,为了使表征更贴合用户的真实情况,本文进行了T次迭代,并将结果作为用户的特征表示():
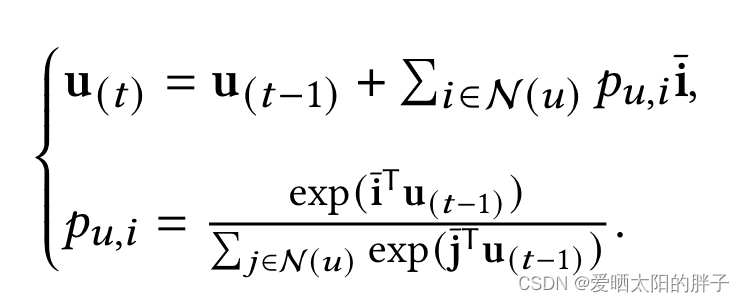
看到这儿,你可能会问:上面的公式是模态m上的注意力公式,那对于多模态数据,存在多个分数呢??到底用哪个啊??
本文提出了一种多模态分数融合方式:

可以提升表示能力。