介绍:https://cloud.tencent.com/developer/article/1347777
Mnist 是手写数字识别数据集,分别为1到10,大小为12MB左右。
CIFAR 数据集,分为两种CIFAR10和CIFAR100,类别也根据名称就可以知道,一类为10类加一个背景,另一个为100类加一个背景。大小在170MB左右。
PASCAL VOC数据集,地址:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html
任务:目标分类,目标检测,实例分割,动作分类(是对图像做的预测,分析静止图片中人物所作的动作),分类,主要有20类
人:人
动物:鸟,猫,牛,狗,马,羊
车辆:飞机,自行车,船,公共汽车,汽车,摩托车,火车
室内:瓶子,椅子,餐桌,盆栽,沙发,电视/显示器
主要有VOC2007和VOC2012,我们以VOC2012为例,下载解压之后可以看到下面几个文件,分别为:
JPEGImages中包含了PASCAL VOC所提供的所有的图片信息,包含了训练集和测试集。这些图片是以”年_id“命名的图片的尺寸大小不一。
Annotations文件夹中存放的是xml格式的文件,每一个xml文件都是对应JPEGImages中的一张图片。Xml格式如下所示:
<annotation>
<folder>VOC2012</folder>
<filename>2007_000392.jpg</filename>
<source>
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
</source>
<size>
<width>500</width>
<height>332</height>
<depth>3</depth>
</size>
<segmented>1</segmented>
<object>
<name>horse</name>
<pose>Right</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>100</xmin>
<ymin>96</ymin>
<xmax>355</xmax>
<ymax>324</ymax>
</bndbox>
</object>
<object>
<name>person</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>198</xmin>
<ymin>58</ymin>
<xmax>286</xmax>
<ymax>197</ymax>
</bndbox>
</object>
</annotation>
3为ImageSets存放的是每一个类型的challenge对应的图像数据。Imagesets存放的是四个文件夹
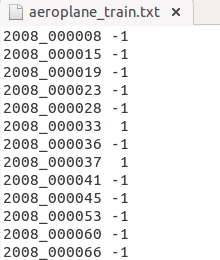
其中Actions存放的是人的动作,Layout存放的是人体部位的数据,Main存放 的是图像识别的数据,总共20类。Segmentation下存放的是分割的数据。Main文件下包含了20个分类的**_train.txt和**_val.txt,这些文件的内容示例如上:前面表示图像的name,后面的1代表正样本,-1代表负样本SegmentationClass和SegmentationObject这两个文件夹下保存的是物体分割后的图片。
coco数据集:
是微软发布的一个数据集,主要任务包括,detection,segmentation,keypoints等任务。与PASCAL VOC数据集相比,COCO中的图片包含了自然图片以及生活中常见的目标图片,背景比较复杂,目标数量比较多,目标尺寸更小,因此COCO数据集上的任务更难,对于检测任务来说,现在衡量一个模型好坏的标准更加倾向于使用COCO数据集上的检测结果。MSCOCO包括91个类别
Imagenet,这个数据集大家都比较熟悉了,主要做图像分类。