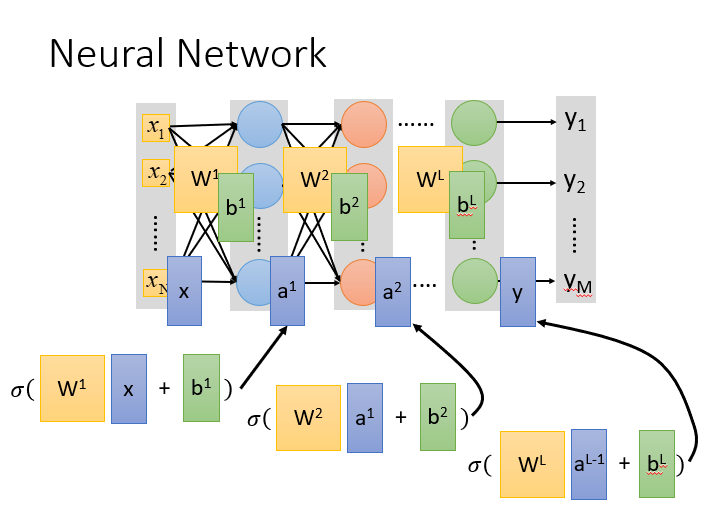
嗨,深度学习探险家们!在深度学习中,不平衡数据集和噪声数据是我们常常会遇到的挑战。它们可能导致模型性能下降和训练不稳定。在本文中,我们将探讨如何处理深度学习中的不平衡数据集与噪声数据,打造鲁棒高效的模型。
第一步:处理不平衡数据集
不平衡数据集指的是不同类别的样本数量差别很大。处理不平衡数据集的方法包括:
-
重采样技术:通过过采样少数类别样本或欠采样多数类别样本,平衡数据集中不同类别的样本数量。
-
类别权重调整:为不同类别设置不同的权重,让模型在训练过程中更关注少数类别。
-
合成样本:对于图像数据,可以使用数据增强技术合成新样本,增加少数类别的样本数量。
-
引入辅助任务:可以通过引入辅助任务,使得模型在多个任务上进行训练,从而更好地利用少数类别样本。
第二步:处理噪声数据
噪声数据指的是在训练数据中存在错误标签或异常样本。处理噪声数据的方法包括:
-
数据清洗:可以通过数据清洗技术,识别并剔除噪声数据,保持训练数据的质量。
-
弱监督学习:在数据标注不准确的情况下,可以使用弱监督学习方法,使用部分标注的数据进行训练。
-
鲁棒损失函数:使用鲁棒损失函数可以降低噪声数据对模型训练的影响,使得模型对噪声数据更加鲁棒。
第三步:集成学习
集成学习是一种有效的方法,通过结合多个模型的预测结果来提高模型的性能。在面对不平衡数据集和噪声数据时,集成学习可以提高模型的鲁棒性和泛化能力。
第四步:性能评估与监控
在处理不平衡数据集和噪声数据的过程中,我们需要及时评估模型的性能并进行监控。通过使用合适的性能评估指标,如精确度、召回率等,我们可以了解模型在不同类别上的表现,并及时调整模型和处理方法。
感谢大家对文章的喜欢,欢迎关注威 |
❤公众号【AI技术星球】回复(123) |
白嫖配套资料+60G入门进阶AI资源包+技术问题答疑+完整版视频 |
内含:深度学习神经网络+CV计算机视觉学习(两大框架pytorch/tensorflow+源码课件笔记)+NLP等 |


综上所述,处理深度学习中的不平衡数据集与噪声数据是提高模型性能的重要步骤。通过采用重采样技术、类别权重调整、数据清洗、集成学习等方法,我们可以打造鲁棒高效的模型,充分利用数据的信息,提高模型的准确性和稳定性。相信通过这些策略,你将能够处理不平衡数据集和噪声数据,训练出更加优秀的深度学习模型!加油,你是最棒的!