本文是香港科技大学的Yu Zhang和 杨强博士发表在Computer science上的一篇关于MTL的综述文章。
摘要
多任务学习(MTL),通过提取各任务之间的相关信息可以提高性能表现。本文,作者第一次给出了多任务学习的定义,对多任务学习做一个综述。文中介绍了几种不同的MTL,每一组都介绍了相关的典型模型。包含多任务监督学习,多任务非监督学习,多任务半监督学习,多任务主动学习。多任务强化学习,多任务在线学习以及多任务多视角学习。为了加速学习过程,介绍了并行以及分布式MTL模型。MTL模型应用在许多领域,比如计算机视觉,生物信息,健康信息,语音,自然语言处理,web应用以及普适计算。最后,本文介绍了MTL最新的研究进展。、
本文大篇幅介绍了MTL监督学习:
1.Introduction
机器学习往往需要大量的标注数据,但是诸如医疗图像领域,已有的标注数据很少,所以需要从其他相关任务中探索有用的信息解决数据稀疏问题。
多任务学习和迁移学习,多标签学习相关。与迁移学习不同的是,迁移学习是学习一个或者多个任务用于提高目标任务表现,MTL则是多个任务之间互相学习,互相提高。
2.多任务学习的定义
多任务学习即给定m个学习任务{Ti}i=1,...m,每一任务或者任务的子集都是相关的,但是不完全相同。多任务学习使用m个任务之间的相关信息提高每一个任务Ti的表现。
可以看出该定义包含两个基本要素:任务相关性和任务的定义。任务的定义包含监督任务,非监督任务等等,不同的任务定义产生了不同的MTL。下面逐一介绍:
3.MTL监督学习(multi-task supervised learning简称MTSL)
反映MTSL相关性体现在是三个方面:特征(feature),参数(parameter)以及实例(instance),所以可以分三类任务:feature-based, parameter-based, instance-based MTSL.
3.1 Feature-based MTSL
这类任务假设所有的任务共享特征,基于怎么呈现这些共享特征,可以分为三种方法:特征转换方法,特征选择方法以及深度学习方法。
(1)特征转换方法
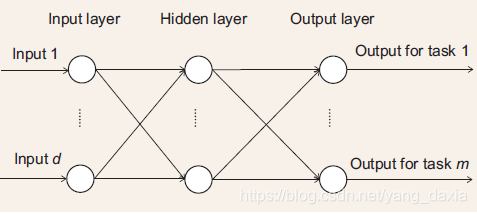
该方法把起始特征通过线性或者非线性准换,一个代表性的模型为多层前馈神经网络。如下图所示。输入层为d个特征单元,接受m个任务的数据,经过神经网络非线性映射,输出m个不同任务的输出。
除此之外,还有MTFL和MTSC[5,6]线性映射方法。首先把数据转化,然后学习以一个线性函数。公式如下:
![]()
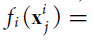
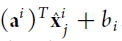
区别在于MTFL中的U阵为正交阵,通过L1,L2正则化后矩阵A低稀疏,而MTSC方法U阵列数远大于行数,通过L1正则以后矩阵A稀疏。
(2)特征选择方法
该方法目的在于从初始特征中选取一个子集作为多任务的共享特征。其中一种有效的方法是Lp,q正则化任务中的线性学习函数的权重矩阵W,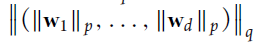 p,q可以是2,1;∞,1等。这样可以使W矩阵具有低稀疏性,滤除一些不重要的特征。
p,q可以是2,1;∞,1等。这样可以使W矩阵具有低稀疏性,滤除一些不重要的特征。
(3)深度学习方法
该方法类似前文提到的多层前馈神经网络,但是网络结构更深,包含CNN,RNN结构。大部分文献[18-22]都把一个隐层的输出作为共享特征。但是文献[23]中提出十字神经网络,将具有相同神经网络结构的两个任务中的特征,通过十字交叉操作生成新的特征,如下所示。该方法比之前的方法更灵活。
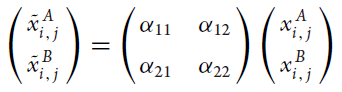
3.2Parameter-based MTSL
这类方法通过模型的参数建立多任务之间的相关性。基于建立相关性的方法,可以分为5类。
(1)low-rank approach
相似的任务具有相似的模型参数,所以参数矩阵W可能是低秩的。文献[24]通过矩阵分解
![]() 将矩阵分解为:所有任务共享的低秩子空间正交阵
将矩阵分解为:所有任务共享的低秩子空间正交阵![]() 用于移除矩阵冗余,ui为任务i的特殊矩阵。文献26通过正则化矩阵范数,文献27通过capped-trace 正则化产生低秩矩阵。
用于移除矩阵冗余,ui为任务i的特殊矩阵。文献26通过正则化矩阵范数,文献27通过capped-trace 正则化产生低秩矩阵。
(2)Task-clustering approach
类似于数据聚类的思想,把任务聚类几个不同的簇,每一个簇共享模型参数。多任务贝叶斯网络采取的方法包括高斯混合模型,狄利克雷过程。另一种方法受K-MEANS激发,采用各种正则化的方式,如MTFL等。
(3)Task-relation learning approach
之前的研究使用模型假设或者给定先验信息表征任务相关性。现在主要通过数据学习任务之间的相关性。文献42提出多任务高斯过程,通过高斯分布中的协方差矩阵刻画任务相关性。在此基础上演变了多任务关系学习(MTRL)、多任务boosting和多label学习,K最邻近分类等方法。
(4)Dirty approach
该方法将参数矩阵W分解为U和V,(W = U+V)两者分别刻画不同的任务相关性。U通过低秩化刻画任务之间的相关性,V通过系数化刻画任务之间的噪声。目标函数为:在所有的任务以及正则化U和V基础上最小化训练损失。学者提出了5中正则化U和V的方法,如下表所示:这些方法为了使矩阵U低秩或者低稀疏,矩阵V稀疏或者列稀疏。

(5)Multi-level approach
该方法是方法4的推广,将W分解为h个(W=W1+W2+...+Wh)。该方法不仅仅只关注噪声信息,可以刻画更复杂的任务结构,如树形结构,簇任务结构。
3.3Instance-based MTSL
这一类学习的研究很少。文献61首先估计每一个任务中的数据实例占所有任务的权重,然后通过softmax函数确定数据实例的实际权重。最后通过具有权重的数据实例进行多任务学习。
3.4本节总结
feature-based更适用于任务起始特征不是很明确,区别不大的场所,如计算机视觉,自然语言处理,语音方面。但是其泛化能力不好。parameter-based可以学习更具体的参数,相对来说鲁棒性更好。两者可以互相促进。在MTL中MTSL占了90%,应用的更广泛。
4.MTL无监督学习(multi-task unsupervised learning)
无监督学习数据没有label,多任务无监督学习主要关注多任务聚类,把不同数据分成几个不同的数据簇,提取有用信息。此方面的研究也很少,主要有两个方法。MTFL和MTRL,前文已经提高,区别就是没有label。
5.MULTI-TASK SEMI-SUPERVISED LEARNING
训练集中既有带有标签的数据,也有无标签的数据。通过学习探索无标签数据中的有效信息。可以分为两类:多任务半监督分类和多任务半监督回归。对于前者,文献63,64使用狄利克雷过程进行任务聚类;对于后者,文献65在使用高斯过程,用无标签数据定义核函数。
6.MULTI-TASK ACTIVE LEARNING
数据中大部分都是无标签数据,所以要采取不同的方法选择有用的无标签数据。如潜在狄利克雷分布等。
7.MULTI-TASK REINFORCEMENT LEARNING
增强学习通过环境学习采用行动,最大化累积回报。通过马尔科夫决策过程建立增强学习模型。
8.MULTI-TASK ONLINE LEARNING
训练数据为连续不断产生时可以采用在线学习。文献76在在线学习算法中对任务中的行动施加约束。文献78提出贝叶斯下在线学习算法,使用高斯过程共享核参数。文献79使用MTRL在线学习算法共享模型参数以及协方差。
9.MULTI-TASK MULTI-VIEW LEARNING
在计算机视觉中,一个数据点可以用不同的特征描述,称之为多视角学习。文献80提出第一个多任务多视角分类器,分类器共享每一个任务中的多视角。文献81通过每一个任务中的无标签数据中的多视角表征多任务之间的相关性。
10PARALLEL AND DISTRIBUTED MTL
如果任务过多的,需要使用多个GPU并行计算,文献82提出了一种并行计算算法解决MTRL中的子问题。如果不同任务的训练数据在不同的机器上时,需要使用分布式计算。文献83提出一种分布式计算方法,提高了计算的效率。
11THEORETICAL ANALYSIS
MTL的理论分析集中在探讨其泛化模型的派生边界。文献133第一次推导出MTL模型派生边界,研究人员随后在特征转换方法,特征选择方法,低秩方法,任务相关性学习方法,噪声方法等方面探究了模型派生的边界。