文章目录
前言
本文主要介绍pytorch中常用的损失函数API的使用。
1. 分类损失
1.1. nn.BCELoss()

nn.BCELoss()用于计算二分类问题,使用时采用默认初始化即可,即reduction='mean’是返回loss在所有样本上的均值。在forward方法中,所接受的 input和target必须一样的shape,且target是one-hot编码,而input需提前经过sigmoid处理。
from math import log
import torch
import torch.nn as nn
import torch.nn.functional as F
# 二元交叉熵损失函数,只能处理二分类问题
# 假设处理 二分类问题,且批次=2
input = torch.Tensor([[-1,1],[1,2]]) # input: [2,2]
input = input.sigmoid()
# 转成one-hot
target = torch.Tensor([0,1]) # shape:[2]
onehot_target = torch.eye(2)[target.long(), :]
Loss = nn.BCELoss() # 采用默认初始化
loss1 = Loss(input, onehot_target)
loss2 = F.binary_cross_entropy(input, onehot_target) # 1.0167
1.2. nn.BCEWithLogitsLoss()
该损失函数就是集成了sigmoid的处理,即此时input是直接网络输出即可,不必人为加sigmoid处理。
from math import log
import torch
import torch.nn as nn
import torch.nn.functional as F
# 二元交叉熵损失函数,只能处理二分类问题
# 假设处理 二分类问题,且批次=2
input = torch.Tensor([[-1,1],[1,2]]) # input: [2,2]
# 转成one-hot
target = torch.Tensor([0,1]) # shape:[2]
onehot_target = torch.eye(2)[target.long(), :]
Loss = nn.BCEWithLogitsLoss() # 采用默认初始化
loss1 = Loss(input, onehot_target)
loss2 = F.binary_cross_entropy_with_logits(input, onehot_target)
print(loss1, loss2) # [1.0167]
1.3. 多分类交叉熵损失函数
1)在解决多分类问题时,公式如下:

其中N是总样本个数,K是类别,pic表示第i个样本所属第c个类别。这么说比较抽象,假设现在需要手动实现上述公式的代码: 假设有3个样本(N=3),其中每个p假设经过softmax处理,概率和为1,并将label转成one-hot编码。

首先不要考虑最外层的求和符号,先计算内层的求和计算:L1,L2,L3,在计算外层的求和符号即可。

from math import log
import torch
import torch.nn as nn
import torch.nn.functional as F
p = torch.Tensor([[0.2,0.3,0.5],[0.1,0.7,0.2],[0.4,0.5,0.1]])
label = torch.Tensor([0,1,2])
onehot = torch.eye(3)[label.long(), :]
# 分别计算每个样本的交叉熵
p = torch.log(p) # 取对数
loss = torch.sum(onehot * p)# 对应元素相乘并求和
# 在计算外层求和符号
loss = -loss / p.shape[0]
print(loss) # 1.4429
2)为了简化上述流程(label需one-hot=),torch用==nn.NLLLoss()==其进行了封装,将上述代码简化:
from math import log
import torch
import torch.nn as nn
import torch.nn.functional as F
Loss = nn.NLLLoss()
p = torch.Tensor([[0.2,0.3,0.5],[0.1,0.7,0.2],[0.4,0.5,0.1]])
label = torch.Tensor([0,1,2]).long()
#onehot = torch.eye(3)[label.long(), :]
# 分别计算每个样本的交叉熵
p = torch.log(p) # 取对数
loss = Loss(p, label)
#loss = torch.sum(onehot * p)# 对应元素相乘并求和
# 在计算外层求和符号
#loss = -loss / p.shape[0]
print(loss) # 1.4429
3)上述过程还是不够简化,因为p需要softmax+log操作,于是,torch进一步封装,就是:

先不必管参数,直接使用:
from math import log
import torch
import torch.nn as nn
import torch.nn.functional as F
p = torch.randn(4,3) # 网络直接输出,没有经过Softmax
label = torch.Tensor([0,1,2,0]).long() #
# 首先拿普通方法计算下
log_p = F.log_softmax(p)
Loss = nn.NLLLoss()
loss1 = Loss(log_p, label)
# 用CrossEP计算下
Loss = nn.CrossEntropyLoss()
loss2 = Loss(p, label)
print(loss1, loss2) #二者结果一致
简单做下总结: 交叉熵损失函数:log + softmax + one-hot的集大成者,此时pred只需是[N,C]未经Softmax处理的,label只需是[N]里面元素是正常类别标签即可。然后传入API就能得出交叉熵损失。
4)当然,这里有个额外参数需注意下:ignore_index,作用是忽略某个类别的损失。比如设置为0,就是去掉0这部分的损失值,并在非0元素上做损失的平均。
from math import log
import torch
import torch.nn as nn
import torch.nn.functional as F
p = torch.Tensor([[0.1, 0.2, 0.3],[0.4, 0.5, 0.6],[0.1,0.2,0.3]]) #[2,3]
label = torch.Tensor([0, 1, 1]).long() # [2]
# 现在假设去掉标签为0的损失
Loss = nn.CrossEntropyLoss(ignore_index=0)
loss3 = Loss(p, label)
print(loss3) # 1.1019
print('验证ignore_index')
p = F.softmax(p) # 对p进行softmax
onehot = torch.eye(3)[label.long(), :]
# 分别计算每个样本的交叉熵
p = torch.log(p)
v = (onehot * p)
loss = torch.sum(v[1:]) # 去掉标签为0的损失
# 在计算外层求和符号
loss = -loss / 2 # 2个非0,故/2
print(loss) #
1.4.Focal_loss
介绍完交叉熵损失后,不得不介绍下常用的Focal loss。首先看下focal loss的公式:
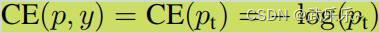
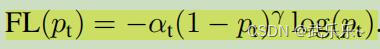
从公式上可以看出,实现focal loss首先实现CE(pt),即二维交叉熵损失函数,可以直接采用自带sigmoid操作的nn.BCEWithLogitsLoss(),且target需要one-hot编码。
在有了CE后,需要单独求下pt即可,注意此处需要人为加上sigmoid! 另外,论文中alpha_t的求解和pt一样:

这里贴下focal loss经典实现:
import torch
from torch import nn
import torch.nn.functional as F
class FocalLoss(nn.Module):
def __init__(self,alpha=0.25,gamma=2.0,reduce='sum'):
super(FocalLoss,self).__init__()
self.alpha = alpha
self.gamma = gamma
self.reduce = reduce
def forward(self,classifications,targets):
# classifcation:[N,K]
# targets: [N,K]的one-hot编码
alpha = self.alpha
gamma = self.gamma
classifications = classifications.view(-1) # 不经过sigmoid的classification;
targets = targets.view(-1) # 应该是 one-hot
# ce_loss: 对应公式中 -log(pt),也就是普通的 交叉熵损失;--> 该函数接收未经sigmoid的函数;
ce_loss = F.binary_cross_entropy_with_logits(classifications, targets.float(), reduction="none")
#focal loss
p = torch.sigmoid(classifications) # 经过sigmoid
p_t = p * targets + (1 - p) * (1 - targets) # 计算pt
loss = ce_loss * ((1 - p_t) ** gamma) # -log(pt) * (1-pt) ** ganmma
if alpha >= 0:
# 对应公式中alpha_t控制损失的权重
alpha_t = alpha * targets + (1 - alpha) * (1 - targets) # 和pt求解过程一样
loss = alpha_t * loss # 最终focal loss
if self.reduce=='sum':
loss = loss.sum()
elif self.reduce=='mean':
loss = loss.mean()
else:
raise ValueError('reduce type is wrong!')
return loss