文章目录
- Classification
- CNN
- text-cnn
- 1. 网络结构
- 2. 参数与超参数
- 3. Embedding Layer
- 4. Convolution Layer
- 5. Max-Pooling Layer
- 6. SoftMax分类Layer
- 7. 变种
- 实验
- Effective Use of Word Order for Text Categorization with Convolutional Neural Networks
- DPCNN
- Super Charactors
- Dynamic Convolutional Neural Network
- Fine-tuned Language Models for Text Classification
- 介绍
- Fine-tuned Language Models(FitLaM)
- 通用领域语言模型预训练
- 目标任务语言模型微调
- Target task classifier fine-tuning
- Discriminative fine-tuning
- BPTT for Text Classification(BPT3C)
- Bidrectional language model
- 实验
- fastText(Bag of Tricks for Efficient Text Classification)
- ULMFiT
- Att-BLSTM
Classification
CNN
卷积神经网络相比于基于词袋模型的DNN有以下优点:
- 能捕获局部的位置信息
- 能够方便的将不定长的输入转换成定长输入接入到DNN网络中
- 相比于RNN模型计算复杂度低,在很多任务中取得不错的效果
text-cnn
1. 网络结构
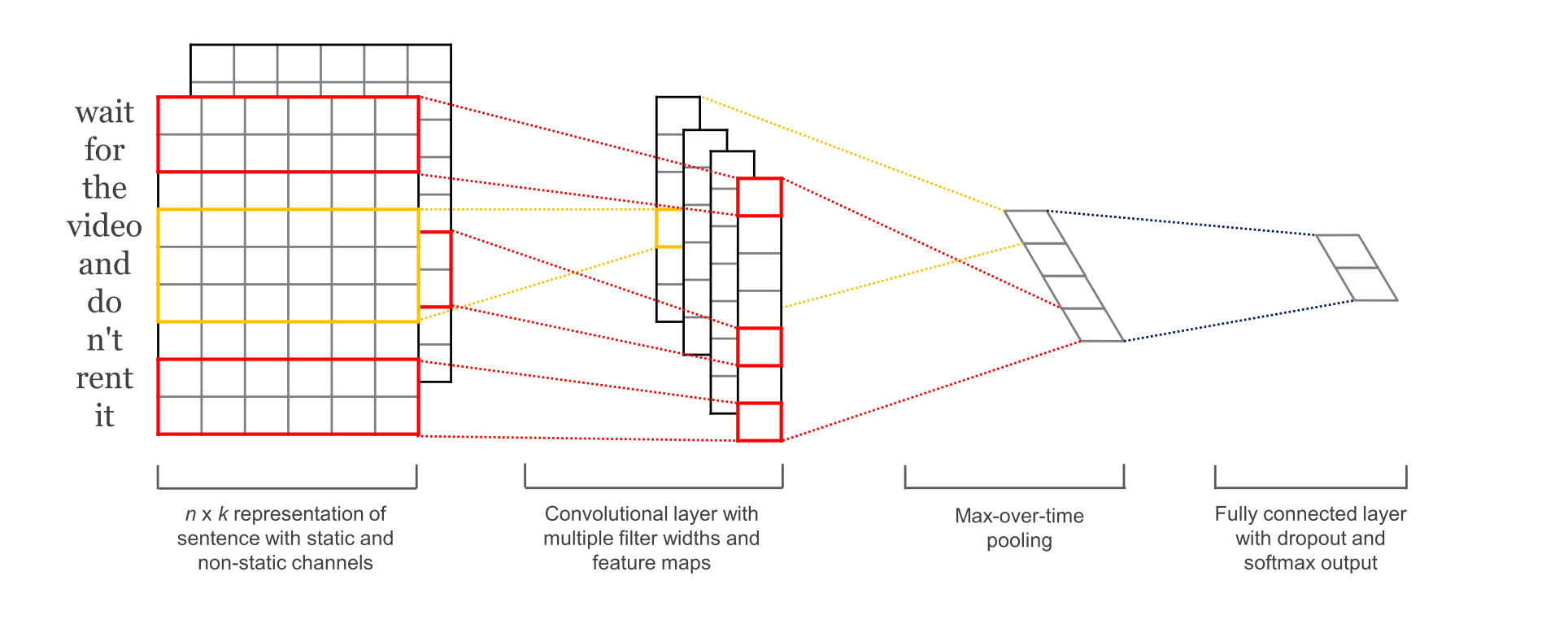
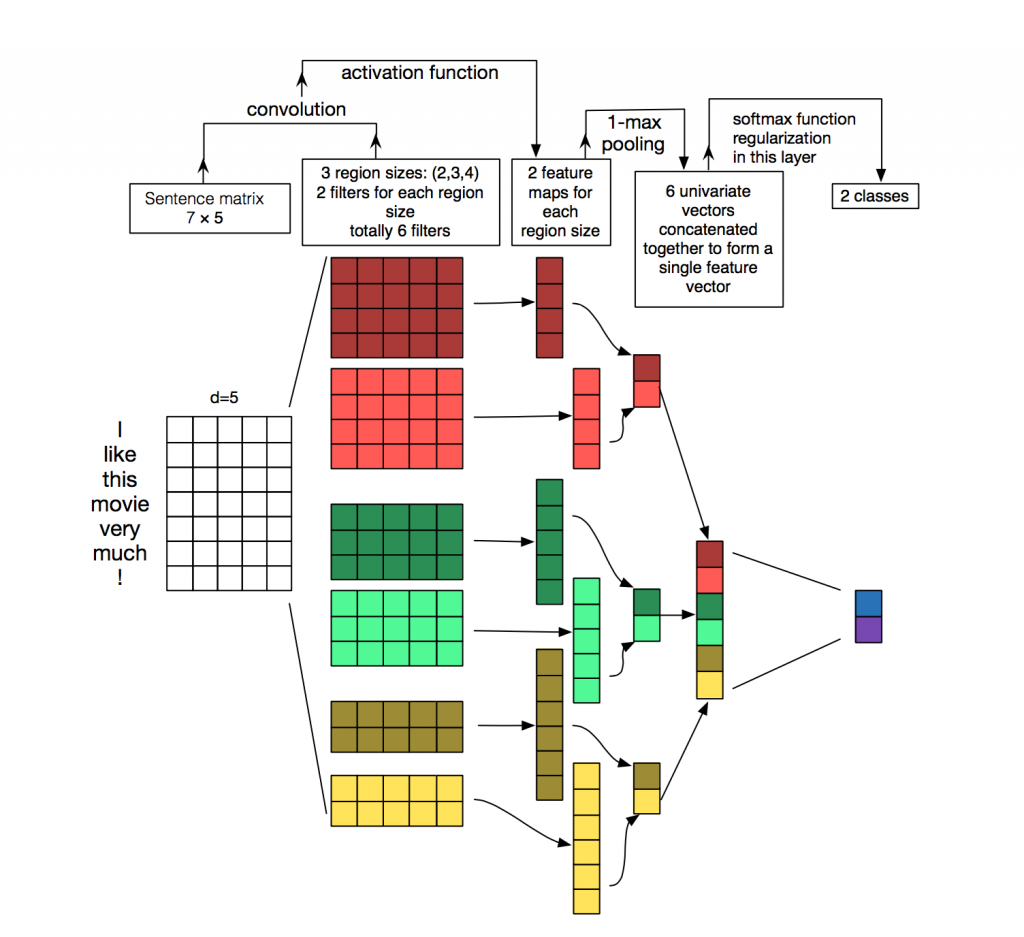
2. 参数与超参数
- sequence_length
CNN输入输出都是固定的,对句子做定长处理,超过的截断,不足的补0. - num_classes
类别数量 - vocabulary_size
语料库词典大小 - filter_size_list
多个不同size的filter
3. Embedding Layer
4. Convolution Layer
输入层通过卷积操作得到若干个Feature Map,卷积窗口的大小为 h×k ,其中 h 表示纵向词语的个数,而 k 表示word vector的维数。通过这样一个大型的卷积窗口,将得到若干个列数为1的Feature Map。
5. Max-Pooling Layer
接下来的池化层,文中用了一种称为Max-over-time Pooling的方法。这种方法就是简单地从之前一维的Feature Map中提出最大的值,文中解释最大值代表着最重要的信号。可以看出,这种Pooling方式可以解决可变长度的句子输入问题(因为不管Feature Map中有多少个值,只需要提取其中的最大值)。最终池化层的输出为各个Feature Map的最大值们,即一个一维的向量。
6. SoftMax分类Layer
池化层的一维向量的输出通过全连接的方式,连接一个Softmax层,Softmax层可根据任务的需要设置(通常反映着最终类别上的概率分布)。最终实现时,我们可以在倒数第二层的全连接部分上使用Dropout技术,即对全连接层上的权值参数给予L2正则化的限制。这样做的好处是防止隐藏层单元自适应(或者对称),从而减轻过拟合的程度。
7. 变种
- CNN-rand
设计好 embedding_size 这个 Hyperparameter 后, 对不同单词的向量作随机初始化, 后续BP的时候作调整. - static
pre-trained词向量固定,训练过程不再调整 - non-static
pretrained vectors + fine-tuning - multiple channel
static与non-static搭两个通道
实验
数据

结论
- CNN-static较与CNN-rand好,说明pre-training的word vector确实有较大的提升作用;
- CNN-non-static较于CNN-static大部分要好,说明适当的Fine tune也是有利的,是因为使得vectors更加贴近于具体的任务;
- CNN-multichannel较于CNN-single在小规模的数据集上有更好的表现,实际上CNN-multichannel体现了一种折中思想,即既不希望Fine tuned的vector距离原始值太远,但同时保留其一定的变化空间。
Effective Use of Word Order for Text Categorization with Convolutional Neural Networks
主要思路:
不做word embedding,直接输入one-hot
- seq-CNN
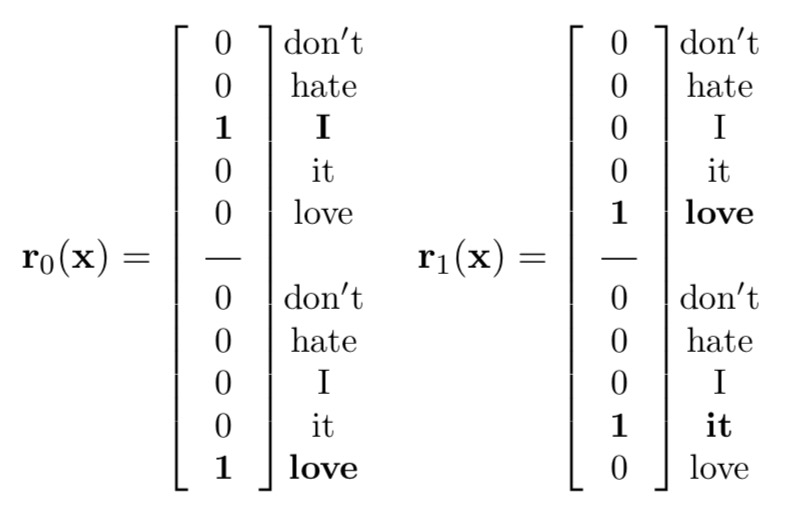
- bow-CNN
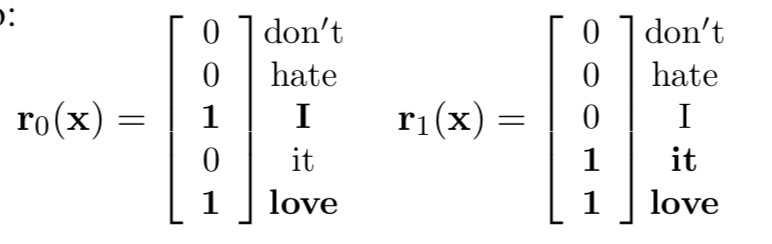
- Extension: parallel CNN
首先将句子序列中每个词onhot表示,然后可以通过不同size的卷积池化层来对其进行特征抽取,得到结果之后再进行concat,然后再接全连接输出层进行输出。

DPCNN
Super Charactors
主要思想:把文字转化成图,然后用图片进行训练。

Dynamic Convolutional Neural Network
一、介绍
模型采用动态k-max pooling取出得分topk的特征值,能处理不同的句子,不依赖解析树。网络包含两种类型的层:一维的卷积层和动态k-max池化层(Dynamic k-max pooling)。
k-max pooling:
- pooling的结果不是返回一个最大值,而是返回k组最大值,这些最大值是原输入的一个子序列;
- pooling中的参数k可以是一个动态函数,具体的值依赖于网络的其他参数。
二、模型的特点
- 保留了句子中词序信息和词语之间的相对位置;
- 宽卷积的结果是传统卷积的一个扩展,某种意义上,也是n-gram的一个扩展,更加考虑句子边缘的信息;
- 模型不需要任何先验知识,并且模型考虑了句子中相隔较远的词语之间的语义信息。
三、模型结构及原理

1. 宽卷积
卷积层使用 宽卷积(Wide Convolution) 的方式。
与传统卷积操作相比,宽卷积输出Feature Map宽度更宽,因为卷积窗口并不需要覆盖所有的输入值。(感觉就是padding?)

2. k-max池化
k-max pooling选择序列p中的前k个最大值,这些最大值保留原来序列的词序。
k-max pooling的好处在于,既提取句子中的较重要信息(不止一个),同时保留了它们的次序信息。同时,由于应用在最后的卷积层上只需要提取出k个值,所以这种方法允许不同长度的输入。
3. 动态k-max池化
动态k-max池化中k是输入句子长度和网络深度两个参数的函数。
表示当前卷积的层数,
是网络总共卷积层的层数;
为最顶层卷积层pooling对应的k值,是一个固定值;s是输入句子的长度。
动态k-max池化的意义在于,从不同长度的句子中提取出相应数量的语义特征信息,以保证后续卷积层的统一性。
4. 非线性特征函数
5. 多个Feature Map
6. 折叠操作(Folding)
在卷积之后,pooling之前将相邻两行相加。该操作没有增加参数数量,但是提前(在最后的全连接层之前)考虑了特征矩阵中行与行之间的某种关联。
Fine-tuned Language Models for Text Classification
介绍
提出一种fine-tuned的语言模型(FitLaM)。
基于一个简单的RNN,没有其他额外修改。
主要贡献点:
- 分析CV和NLP迁移学习的相似性,为NLP迁移学习提供理论依据;
- 提出FitLaM,一种可以用来实现NLP各种任务的迁移学习方法;
- 提出判别微调方法,保留以前的知识,避免微调过程中发生灾难性遗忘;
- 引入了文本分类的"通过时间反向传播"(BPT3C),这是一种通过线性层将分类器丢失反向传播到任意序列大小的rnn输出的新方法;
- 介绍微调预训练语言模型的关键技术;
- 在5个代表性文本分类数据集上达到state-of-the-art,在主要数据集上错误率下降18-24%;
Fine-tuned Language Models(FitLaM)
统计语言模型目的是通过给定之前词语,预测下个词的概率。作者选择使用AWD-LSTM模型。
FitLaM主要包括三步:
- 通用领域语言模型预训练;
- 目标任务语言模型微调;
- 目标任务分类器微调;
通用领域语言模型预训练
利用Wikitext-103进行模型预训练。
目标任务语言模型微调
给定任务数据和之前预训练数据分布有偏差,需要微调。
Gradual unfreezing
从最后一层逐步解冻,微调所有解冻层。与之前做法区别:解冻层是一个集合,而不是每次只训练单独一层。
Fine-tuning with cosine annealing
只训练一个epoch,每个batch降低一次学习率。
Warm-up reverse annealing
Target task classifier fine-tuning
针对目标任务分类器微调,在预训练模型基础上增加一或多个额外的线性块。每个块使用batch normalization和dropout,内部层使用ReLU,输出使用softmax。
Concat pooling
Discriminative fine-tuning
太激进的微调可能导致灾难性的遗忘,而太谨慎的微调又会使收敛太缓慢。
之前SGD更新:
作者希望不同层学习率不同,
代表不同层学习率
BPTT for Text Classification(BPT3C)
将文本分为大小为b的固定长度batches,在每个batch开始之前,将模型用上个batch最后状态初始化。
Bidrectional language model
训练一个双向的语言模型,使用BPT3C对正向和反向分别进行微调,对他们的预测结果取平均。
实验
分了三个分类任务:情感分析,问题分类,主题分类
fastText(Bag of Tricks for Efficient Text Classification)
介绍
fastText提供简单而高效的文本分类和表征学习,性能比肩深度学习而且速度更快。fastText结合自然语言处理和机器学习中最成功的理念,比如词袋模型、n-gram,并通过隐藏表征在类别间共享信息。另外,采用hierarchical softmax加速运算过程。

Model architecture
模型输入一段文本或一句话,输出该文本属于不同类别的概率
损失函数:
Hierarchical softmax
分类类别很多时,训练线性分类器的计算量比较大,计算复杂度为$O(kh)$,k是类别数,h是文本表示的维度。为了提高运行速度,使用层次softmax,在训练期间,计算复杂度降到$O(hlog_2(k))$。同时,在测试时查找类别速度也得到提升。
N-gram features
使用hashing trick捕捉词序特征。
总结
fastText的学习速度比较快,效果还不错。fastText适用与分类类别非常大而且数据集足够多的情况,当分类类别比较小或者数据集比较少的话,很容易过拟合。可以完成无监督的词向量的学习,可以学习出来词向量,来保持住词和词之间,相关词之间是一个距离比较近的情况;
也可以用于有监督学习的文本分类任务
ULMFiT
//TODO
Att-BLSTM
Model
- Input layer: input sentence to this model;
- Embedding layer: map each word into a low dimension vector;
- LSTM layer: utilize BLSTM to get high level features from step2;
- Attention layer: produce a weight vector, and merge word-level features from each time step into a sentence-level feature vector, by multiplying the weight vector;
- Output layer: the sentence-level feature vector is finally used for relation classification.

Bidirectional Network

LSTM:
BiLSTM:
Attention
Classifying