写在前面
这是文本分类任务的第二个系列----基于RNN的文本分类实现(Text RNN)
复现的论文是2016年复旦大学IJCAI 上的发表的关于循环神经网络在多任务文本分类上的应用:Recurrent Neural Network for Text Classification with Multi-Task Learning
下面提及的代码可以在github中查看:https://github.com/KaiyuanGao/text_claasification/tree/master/rnn_classification
论文概览
在先前的许多工作中,模型的学习都是基于单任务,对于复杂的问题,也可以分解为简单且相互独立的子问题来单独解决,然后再合并结果,得到最初复杂问题的结果。这样做看似合理,其实是不正确的,因为现实世界中很多问题不能分解为一个一个独立的子问题,即使可以分解,各个子问题之间也是相互关联的,通过一些共享因素或共享表示(share representation)联系在一起。把现实问题当做一个个独立的单任务处理,往往会忽略了问题之间所富含的丰富的关联信息。
上面的问题引出了本文的重点——多任务学习(Multi-task learning)。把多个相关(related)的任务(task)放在一起学习。多个任务之间共享一些因素,它们可以在学习过程中,共享它们所学到的信息,这是单任务学习没有具备的。相关联的多任务学习比单任务学习能去的更好的泛化(generalization)效果。本文基于 RNN 循环神经网络,提出三种不同的信息共享机制,整体网络是基于所有的任务共同学习得到。
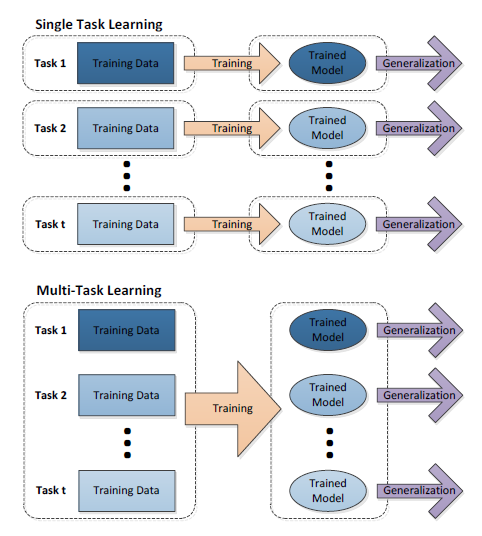
下图展示的是单任务学习和多任务学习的流程图,可以对比一下区别。
下面具体介绍一下文章中的三个模型。
Model I: Uniform-Layer Architecture
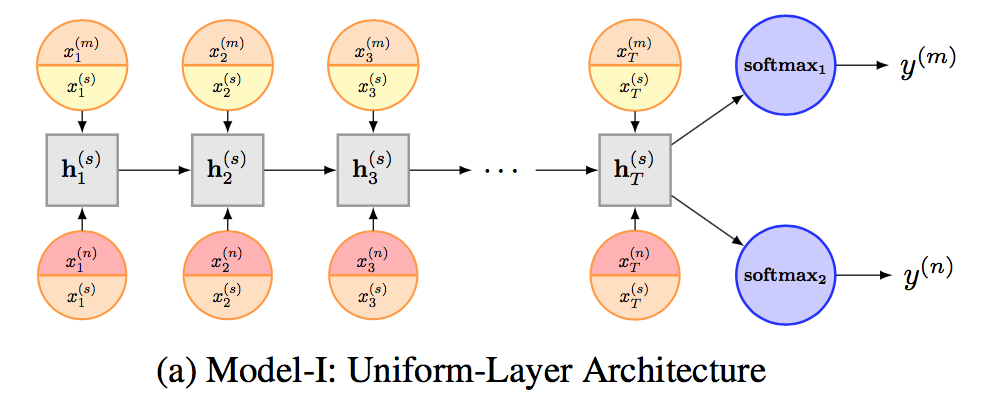
在他们提出的第一个模型中,不同的任务共享一个LSTM网络层和一个embedding layer,此外每个任务还有其自己的embedding layer。所以对于上图中的任务m,输入x包括了两个部分:

其中等号右侧第一项和第二项分别表示该任务特有的word embedding和该模型中共享的word embedding,两者做一个concatenation。
LSTM网络层是所有任务所共享的,对于任务m的最后sequence representation为LSTM的输出:

Model II: Coupled-Layer Architecture
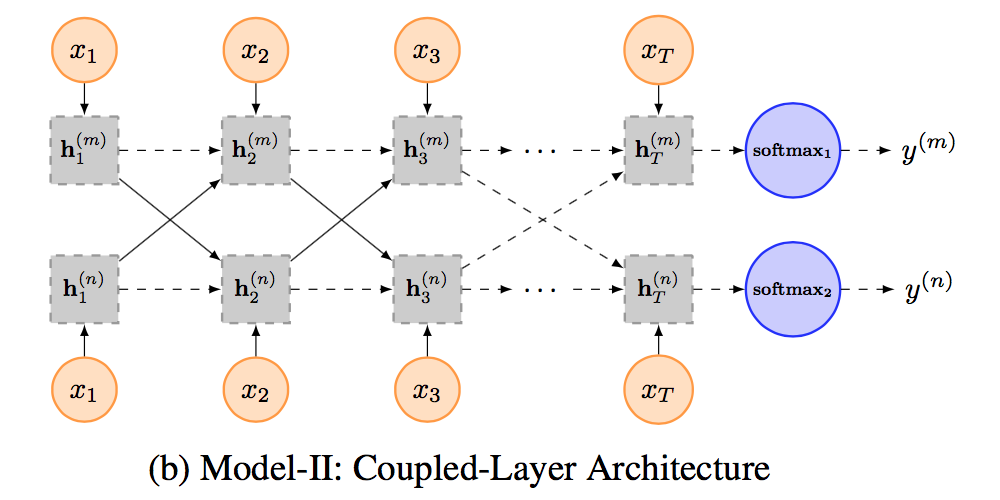
在第二个模型中,为每个任务都指定了特定的LSTM layer,但是不同任务间的LSTM layer可以共享信息。
为了更好地控制在不同LSTM layer之间的信息流动,作者提出了一个global gating unit,使得模型具有决定信息流动程度的能力。
为此,他们改写了LSTM中的表达式:

其中![]()
Model III: Shared-Layer Architecture
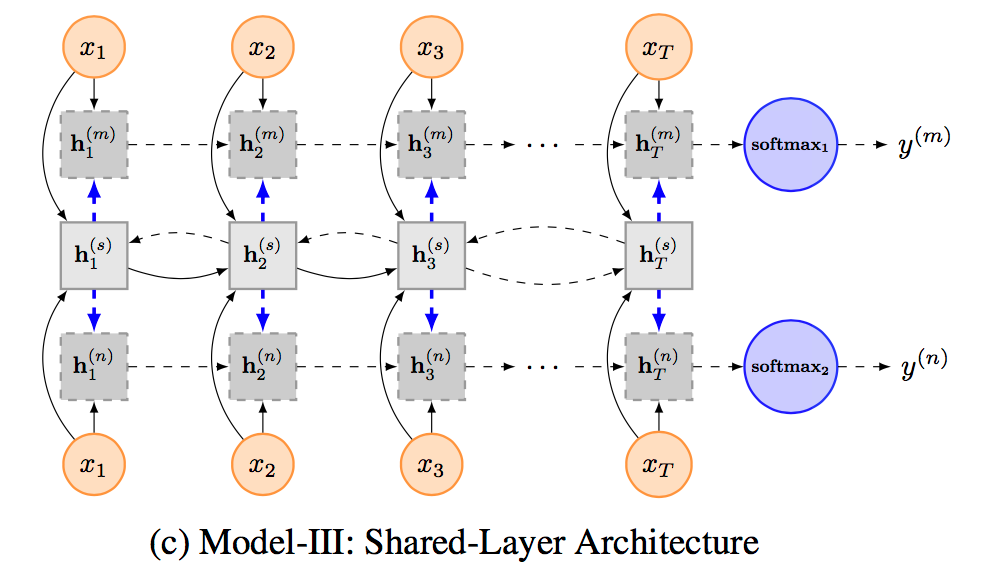
与模型二相似,作者也为每个单独的任务指派了特定的LSTM层,但是对于整体的模型使用了双向的LSTM,这样可以使得信息共享更为准确。
模型表现
论文作者在4个数据集上对上述模型做了评价,并和其他stae-of-the-art的网络模型进行了对比,


其中:
- RNTN Recursive Neural Tensor Network with tensorbased feature function and parse trees [Socher et al., 2013].
- DCNN Dynamic Convolutional Neural Network with dynamic k-max pooling [Kalchbrenner et al., 2014].
- PV Logistic regression on top of paragraph vectors [Le and Mikolov, 2014]. Here, we use the popular open source implementation of PV in Gensim3.
- Tree-LSTM A generalization of LSTMs to treestructured network topologies. [Tai et al., 2015]
代码实现
RNN的代码框架和前面一篇的CNN类似,首先定义一个RNN类来实现论文中的模型
class RNN(BaseModel):
"""
A RNN class for sentence classification
With an embedding layer + Bi-LSTM layer + FC layer + softmax
"""
def __init__(self, sequence_length, num_classes, vocab_size,
embed_size, learning_rate, decay_steps, decay_rate,
hidden_size, is_training, l2_lambda, grad_clip,
initializer=tf.random_normal_initializer(stddev=0.1)):
这里的模型包括了一层embedding,一层双向LSTM,一层全连接层最后接上一个softmax分类函数。
然后依次定义模型,训练,损失等函数在后续调用。
def inference(self):
"""
1. embedding layer
2. Bi-LSTM layer
3. concat Bi-LSTM output
4. FC(full connected) layer
5. softmax layer
"""
# embedding layer
with tf.name_scope('embedding'):
self.embedded_words = tf.nn.embedding_lookup(self.Embedding, self.input_x)
# Bi-LSTM layer
with tf.name_scope('Bi-LSTM'):
lstm_fw_cell = rnn.BasicLSTMCell(self.hidden_size)
lstm_bw_cell = rnn.BasicLSTMCell(self.hidden_size)
if self.dropout_keep_prob is not None:
lstm_fw_cell = rnn.DropoutWrapper(lstm_fw_cell, output_keep_prob=self.dropout_keep_prob)
lstm_bw_cell = rnn.DropoutWrapper(lstm_bw_cell, output_keep_prob=self.dropout_keep_prob)
outputs, output_states = tf.nn.bidirectional_dynamic_rnn(lstm_fw_cell, lstm_bw_cell,
self.embedded_words,
dtype=tf.float32)
output = tf.concat(outputs, axis=2)
output_last = tf.reduce_mean(output, axis=1)
# FC layer
with tf.name_scope('output'):
self.score = tf.matmul(output_last, self.W_projection) + self.b_projection
return self.score
def loss(self):
# loss
with tf.name_scope('loss'):
losses = tf.nn.softmax_cross_entropy_with_logits(labels=self.input_y, logits=self.score)
data_loss = tf.reduce_mean(losses)
l2_loss = tf.add_n([tf.nn.l2_loss(cand_v) for cand_v in tf.trainable_variables()
if 'bias' not in cand_v.name]) * self.l2_lambda
data_loss += l2_loss
return data_loss
def train(self):
learning_rate = tf.train.exponential_decay(self.learning_rate, self.global_step,
self.decay_steps, self.decay_rate, staircase=True)
optimizer = tf.train.AdamOptimizer(learning_rate)
grads_and_vars = optimizer.compute_gradients(self.loss_val)
grads_and_vars = [(tf.clip_by_norm(grad, self.grad_clip), val) for grad, val in grads_and_vars]
train_op = optimizer.apply_gradients(grads_and_vars, global_step=self.global_step)
return train_op训练部分的数据集这里就直接采用CNN那篇文章相同的数据集(懒...),预处理的方式与函数等都是一样的,,,
import tensorflow as tf
import numpy as np
import os
import time
import datetime
from cnn_classification import data_process
from rnn import RNN
from tensorflow.contrib import learn
# define parameters
#data load params
tf.flags.DEFINE_float("dev_sample_percentage", .1, "Percentage of the training data to use for validation")
tf.flags.DEFINE_string("positive_data_file", "../cnn_classification/data/rt-polarity.pos", "Data source for the positive data.")
tf.flags.DEFINE_string("negative_data_file", "../cnn_classification/data/rt-polarity.neg", "Data source for the negative data.")
#configuration
tf.flags.DEFINE_float("learning_rate", 0.01, "learning rate")
tf.flags.DEFINE_integer("num_epochs", 60, "embedding size")
tf.flags.DEFINE_integer("batch_size", 100, "Batch size for training/evaluating.") #批处理的大小 32-->128
tf.flags.DEFINE_integer("decay_steps", 12000, "how many steps before decay learning rate.")
tf.flags.DEFINE_float("decay_rate", 0.9, "Rate of decay for learning rate.") # 0.5一次衰减多少
tf.flags.DEFINE_string("ckpt_dir", "text_rnn_checkpoint/", "checkpoint location for the model")
tf.flags.DEFINE_integer('num_checkpoints', 10, 'save checkpoints count')
tf.flags.DEFINE_integer("sequence_length", 300, "max sentence length")
tf.flags.DEFINE_integer("embed_size", 128, "embedding size")
tf.flags.DEFINE_integer('hidden_size', 128, 'cell output size')
tf.flags.DEFINE_boolean("is_training", True, "is traning.true:tranining,false:testing/inference")
tf.flags.DEFINE_integer("validate_every", 5, "Validate every validate_every epochs.") #每10轮做一次验证
# tf.flags.DEFINE_float('validation_percentage',0.1,'validat data percentage in train data')
tf.flags.DEFINE_integer('dev_sample_max_cnt', 1000, 'max cnt of validation samples, dev samples cnt too large will case high loader')
tf.flags.DEFINE_float("dropout_keep_prob", 0.5, "Dropout keep probability (default: 0.5)")
tf.flags.DEFINE_float("l2_reg_lambda", 0.0001, "L2 regularization lambda (default: 0.0)")
tf.flags.DEFINE_float('grad_clip', 5.0, 'grad_clip')
tf.flags.DEFINE_boolean("allow_soft_placement", True, "Allow device soft device placement")
tf.flags.DEFINE_boolean("log_device_placement", False, "Log placement of ops on devices")
FLAGS = tf.flags.FLAGS
def prepocess():
"""
For load and process data
:return:
"""
print("Loading data...")
x_text, y = data_process.load_data_and_labels(FLAGS.positive_data_file, FLAGS.negative_data_file)
# bulid vocabulary
max_document_length = max(len(x.split(' ')) for x in x_text)
vocab_processor = learn.preprocessing.VocabularyProcessor(max_document_length)
x = np.array(list(vocab_processor.fit_transform(x_text)))
# shuffle
np.random.seed(10)
shuffle_indices = np.random.permutation(np.arange(len(y)))
x_shuffled = x[shuffle_indices]
y_shuffled = y[shuffle_indices]
# split train/test dataset
dev_sample_index = -1 * int(FLAGS.dev_sample_percentage * float(len(y)))
x_train, x_dev = x_shuffled[:dev_sample_index], x_shuffled[dev_sample_index:]
y_train, y_dev = y_shuffled[:dev_sample_index], y_shuffled[dev_sample_index:]
del x, y, x_shuffled, y_shuffled
print('Vocabulary Size: {:d}'.format(len(vocab_processor.vocabulary_)))
print('Train/Dev split: {:d}/{:d}'.format(len(y_train), len(y_dev)))
return x_train, y_train, vocab_processor, x_dev, y_dev
def train(x_train, y_train, vocab_processor, x_dev, y_dev):
with tf.Graph().as_default():
session_conf = tf.ConfigProto(
# allows TensorFlow to fall back on a device with a certain operation implemented
allow_soft_placement= FLAGS.allow_soft_placement,
# allows TensorFlow log on which devices (CPU or GPU) it places operations
log_device_placement=FLAGS.log_device_placement
)
sess = tf.Session(config=session_conf)
with sess.as_default():
# initialize cnn
rnn = RNN(sequence_length=x_train.shape[1],
num_classes=y_train.shape[1],
vocab_size=len(vocab_processor.vocabulary_),
embed_size=FLAGS.embed_size,
l2_lambda=FLAGS.l2_reg_lambda,
is_training=True,
grad_clip=FLAGS.grad_clip,
learning_rate=FLAGS.learning_rate,
decay_steps=FLAGS.decay_steps,
decay_rate=FLAGS.decay_rate,
hidden_size=FLAGS.hidden_size
)
# output dir for models and summaries
timestamp = str(time.time())
out_dir = os.path.abspath(os.path.join(os.path.curdir, 'run', timestamp))
if not os.path.exists(out_dir):
os.makedirs(out_dir)
print('Writing to {} \n'.format(out_dir))
# checkpoint dir. checkpointing – saving the parameters of your model to restore them later on.
checkpoint_dir = os.path.abspath(os.path.join(out_dir, FLAGS.ckpt_dir))
checkpoint_prefix = os.path.join(checkpoint_dir, 'model')
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
saver = tf.train.Saver(tf.global_variables(), max_to_keep=FLAGS.num_checkpoints)
# Write vocabulary
vocab_processor.save(os.path.join(out_dir, 'vocab'))
# Initialize all
sess.run(tf.global_variables_initializer())
def train_step(x_batch, y_batch):
"""
A single training step
:param x_batch:
:param y_batch:
:return:
"""
feed_dict = {
rnn.input_x: x_batch,
rnn.input_y: y_batch,
rnn.dropout_keep_prob: FLAGS.dropout_keep_prob
}
_, step, loss, accuracy = sess.run(
[rnn.train_op, rnn.global_step, rnn.loss_val, rnn.accuracy],
feed_dict=feed_dict
)
time_str = datetime.datetime.now().isoformat()
print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy))
def dev_step(x_batch, y_batch):
"""
Evaluate model on a dev set
Disable dropout
:param x_batch:
:param y_batch:
:param writer:
:return:
"""
feed_dict = {
rnn.input_x: x_batch,
rnn.input_y: y_batch,
rnn.dropout_keep_prob: 1.0
}
step, loss, accuracy = sess.run(
[rnn.global_step, rnn.loss_val, rnn.accuracy],
feed_dict=feed_dict
)
time_str = datetime.datetime.now().isoformat()
print("dev results:{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy))
# generate batches
batches = data_process.batch_iter(list(zip(x_train, y_train)), FLAGS.batch_size, FLAGS.num_epochs)
# training loop
for batch in batches:
x_batch, y_batch = zip(*batch)
train_step(x_batch, y_batch)
current_step = tf.train.global_step(sess, rnn.global_step)
if current_step % FLAGS.validate_every == 0:
print('\n Evaluation:')
dev_step(x_dev, y_dev)
print('')
path = saver.save(sess, checkpoint_prefix, global_step=current_step)
print('Save model checkpoint to {} \n'.format(path))
def main(argv=None):
x_train, y_train, vocab_processor, x_dev, y_dev = prepocess()
train(x_train, y_train, vocab_processor, x_dev, y_dev)
if __name__ == '__main__':
tf.app.run()完整的代码可以查看本文开篇的github。
以上~