'''
爬虫爬酷6网视频练习
version:01
author:jasn
Date:2020-02-18
'''
import requests
import re
filepath = r'C:\Users\Administrator\Desktop\Day\Jasn--70--Days\爬虫\Day 01\res\酷6视频'
i = 0
def get_page(index_url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
}
request = requests.get(index_url, headers=headers)
if request.status_code == 200:
return request.text
def get_content(res):
detail_urls = re.findall('class="video-image-warp".*?href="(.*?)">', res)
for url in detail_urls:
if url.startswith('/video'):
url = r'https://www.ku6.com' + url
yield url
def parse_videos(detail_url):
l = re.findall('type: "video/mp4", src: "(.*?)"', detail_url)
if l:
new_videos = l[0]
yield new_videos
def get_videos(url, i):
try:
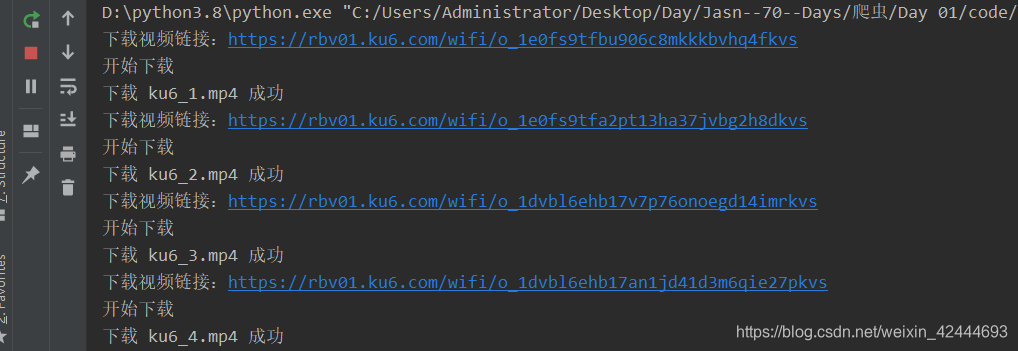
print('下载视频链接:%s' % url)
request = requests.get(url)
if request.status_code == 200:
print('开始下载')
name = 'ku6_'+str(i)
with open(r'%s/%s.mp4' % (filepath, name), 'wb')as f:
f.write(request.content)
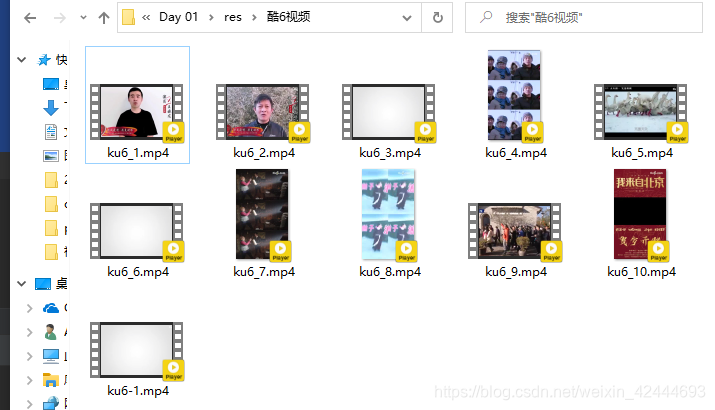
print('下载 %s.mp4 成功' % name)
except Exception:
print('链接超时!')
if __name__ == '__main__':
res = get_page('https://www.ku6.com/index')
videos_url = get_content(res)
for video_url in videos_url:
detail_url = get_page(video_url)
movie_url = parse_videos(detail_url)
for url in movie_url:
i = i+1
get_videos(url, i)
See you next time!
