原创不易,转载前请注明博主的链接地址:Blessy_Zhu https://blog.csdn.net/weixin_42555080
本次代码的环境:
运行平台: Windows
Python版本: Python3.x
IDE: PyCharm
一、 前言
今天这篇文章写的内容是爬取猫眼电影TOP100的电影名称、时间、评分、图片等信息,首先看一下待爬取的网站内容,如图1所示:

图1
通过网站可以看到,它的信息主要包括猫眼排名、电影名、主演、上映时间、评分以及电影海报图片。我们本次的目的是将前面的文本信息分类保存为CSV格式,并可以通过Excel打开,后面的图片信息保存到一个文件夹中。
接下来要将问题具体化:
- 通过查阅待爬取的内容,发现他的全部内容是分页展示在不同的网页上。那么如何爬取每一篇文章的内容
- 如何爬取全部的内容
- 如何将爬取到的内容写入到指定的CSV文件中
- 如何保存图片
既然已经明确了问题,然后根据已经掌握的爬虫经验(参考文章Python爬虫基础之requests+BeautifulSoup+Image 爬取图片并存到本地(五)Python爬虫之BeautifulSoup+Requests爬取喜欢博主的全部博文(六)),针对前三个通过定义一个函数获取全部的网页的URL,然后定义一个函数去解析函数中每个网页的全部内容并写到CSV格式的文件中。保存图片可以通过单独定义一个函数,通过图片的URL解析下载图片并保存到指定文件夹中。思路已经清晰,接下里开始实操。
在爬取网站之前,我也参考了许多类似爬取猫眼电影排行的代码,并进行总结归纳,我的代码的功能扩展点是:把内容保存到CSV文件中,下载电影海报图片。
免责说明:这篇文章爬取的内容是猫眼电影排行Top100网址为(https://maoyan.com/board/4?offset=0 ),本次代码仅仅只是用来交流学习,没有任何商业用途,如有侵权行为,请与本人联系,我会立刻加以整改
二、代码编写与效果展示
按照以往的惯例,还是先给出完整的代码和最终的效果:
2.1 代码展示
from requests.exceptions import RequestException
import re
import csv
import requests
from PIL import Image
from io import BytesIO
import os
import time
def get_one_page(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'
+ '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'
+ '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S)
items = re.findall(pattern, html)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5] + item[6]
}
def get_pages():
urls = []
for i in range(10):
offset=i * 10
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
urls.append(html)
return urls
def down_pics():
folder_path = './photo'
if os.path.exists(folder_path) == False:
os.makedirs(folder_path)
for index0,url in enumerate(get_pages()):
image_name0 = str(index0)
for index,item in enumerate(parse_one_page(url)):
img_name = folder_path+image_name0+str(index) + '.png'
print(item['image'])
picsUrl = str(item['image'])+""
response = requests.get(picsUrl)
image = Image.open(BytesIO(response.content))
image.save('C:/Users/Administrator/PycharmProjects/practice1/photo' + img_name)
time.sleep(1)
def readDown_CSVData():
with open('data1.csv', 'a', encoding='utf-8') as csvfile:
fieldnames = ['index','image','title','actor','time','score']
writer = csv.DictWriter(csvfile,fieldnames = fieldnames)
writer.writeheader()
for url in get_pages():
for item in parse_one_page(url):
writer.writerow(item)
time.sleep(1)
if __name__ == '__main__':
readDown_CSVData()
down_pics()
2.2 效果展示
如图2所示是把所有的文档信息保存到CSV格式的Excel里面

图2
如图3所示是下载的电影海报
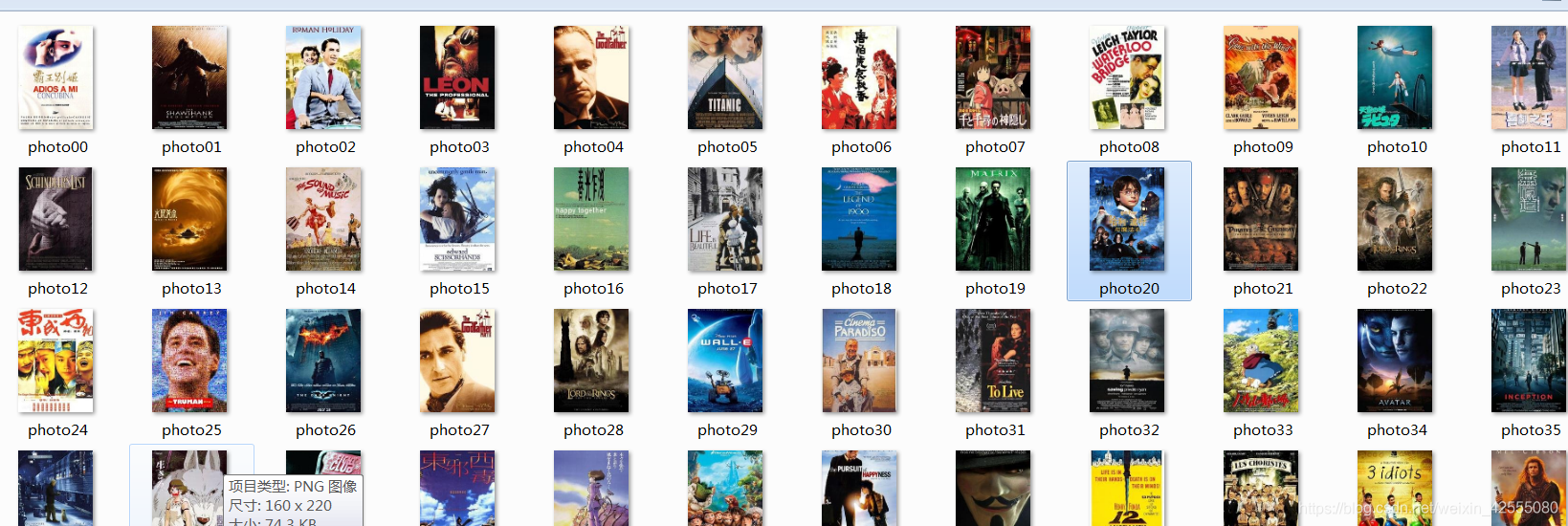
图3
三、代码讲解
3.1正则表达式相关内容
def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'
+ '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'
+ '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S)
items = re.findall(pattern, html)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5] + item[6]
}
这个函数是解析匹配一个网页上的内容全部,其中涉及到re.compile()正则表达式解析函数和findall()函数可以参考一下内容:Python小知识-正则表达式和Re库(一)Python小知识-正则表达式和Re库(二)yield关键字的内容可以参考这篇文章:Python小知识-yield的彻底理解
3.2 get_pages()函数
def get_pages():
urls = []
for i in range(10):
offset=i * 10
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
urls.append(html)
return urls
这个函数的功能是获取全部的网页URL,通过观察不同分页网址
https://maoyan.com/board/4?offset=0
https://maoyan.com/board/4?offset=10
https://maoyan.com/board/4?offset=20
可以发现他的offset的偏移量是10所以通过一些变换可以将所有的URL都append到urls变量里面,获得总的url以便后用。
3.3 PIL库和BytesIO来下载图片
def down_pics():
folder_path = './photo'
if os.path.exists(folder_path) == False:
os.makedirs(folder_path)
for index0,url in enumerate(get_pages()):
image_name0 = str(index0)
for index,item in enumerate(parse_one_page(url)):
img_name = folder_path+image_name0+str(index) + '.png'
print(item['image'])
picsUrl = str(item['image'])+""
response = requests.get(picsUrl)
image = Image.open(BytesIO(response.content))
image.save('C:/Users/Administrator/PycharmProjects/practice1/photo' + img_name)
time.sleep(1)
这部分内容可以参考博客文章:
Python爬虫基础之requests+BeautifulSoup+Image 爬取图片并存到本地(五)其实下载图片的核心代码就是:
import requests
from PIL import Image
from io import BytesIO
response = requests.get('https://p1.meituan.net/movie/dc2246233a6f5ac1e34c7176b602c8ca174557.jpg@160w_220h_1e_1c')
image = Image.open(BytesIO(response.content))
image.save('D:/9.jpg')
现将图片的URL解析成爬取对象,然后通过Image.open()和BytesIO()图片进行二进制的读写通过save()方法保存到指定的目录下。
3.4 将爬取内容写到CSV格式的文件中
def readDown_CSVData():
with open('data1.csv', 'a', encoding='utf-8') as csvfile:
fieldnames = ['index','image','title','actor','time','score']
writer = csv.DictWriter(csvfile,fieldnames = fieldnames)
writer.writeheader()
for url in get_pages():
for item in parse_one_page(url):
writer.writerow(item)
time.sleep(1)
这段代码的核心就是CSV文件的存储,可以参考这篇文章数据存储之三-CSV文件存储,讲的很明白。同时,CSV格式的文件打开,中文字符可能会出现乱码,如果你也遇到这个情况可以参考文章Python问题解决-Excel打开CSV格式内容时中文出现了乱码
四 总结
本文的内容是爬虫初学者可以很快上手爬取的部分,知识点通过相应的链接地址关联到相应的博客,可以进行相关内容的学习。这次爬取的依然是静态网页的内容,主要涉及的Python库为:异常库RequestException、正则表达式库 re、CSV文件处理库csv、图片处理库 PIL、二进制处理库BytesIO、等,通过定义几个函数:get_one_page()获取一个准确无误的网站URL;parse_one_page()解析爬取网站内容,并通过yield关键字进行内容返回;get_pages()获取全部网站的准确无误的URL;down_pics()下载电影海报图片的函数;readDown_CSVData()下载文本信息并生成CSV格式文件;并通过main函数进行调用。这篇文章就到这里了,欢迎大佬们多批评指正,也欢迎大家积极评论多多交流。
