1、问题、问题实例、算法的概念区分。
一个例子说明一下:
问题:判断一个正整数N是否为素数 #问题是需要解决的一个需求
问题实例:判断1314是否为素数? #问题实例是该问题的一个具体例子
算法:解决这个问题的一个计算过程描述。 #算法是对计算过程的严格描述
2、算法的性质。
有穷性、能行性、确定性、终止性、输入/输出。
3、算法的描述
自然语言(容易歧义)
自然语言+数学公式(简单方便,还是歧义)
严格形式描述(比如图灵机模型,非常麻烦,难以阅读)
类似编程语言描述
伪代码的形式
该书主要是采用后两者的描述方式进行的。
4、算法与程序的区别
对算法的描述中,有一种就是用编程语言来进行描述。基于这种认识,程序可以看做是采用编程语言进行描述算法的一种实现。但是程序自己的特点又跟具体编程语言的实现有关系。因此,一般我们把抽象描述一个计算过程称之为算法。而把一个计算在某种语言的实现称之为程序。
5、算法设计与分析
介绍了6种算法设计模式
枚举法(枚举全部、找出最优解)、贪心法(根据已有信息,先部分求解,再基于部分得到完整的解)、分治法(将一个复杂问题化解为很多简单的子问题,对这些子问题分别求解,并组合起来得到复杂问题的解)、动态规划法(对于一些复杂的问题,不能一下求解出来。在求解步骤中,不断积累已知信息,然后动态选择已知的最好求解路径)、回溯法(通过探索方式求解,当选择一个方向探索时发现无解,就回溯到前面探索的那个路口往其他方向继续探索,直到得出解)、分支界限法(回溯法的改良版本,它是在探索的过程中,根据已知的信息如果发现这个选择是错误的,就及早将其删除,用来缩小求解空间,加速问题求解的过程)。
当然,这些算法模式是可以混合使用的。
在计算过程中算法是会不断消耗资源的,包括空间资源跟时间资源。而弄清楚算法耗费资源的多少就是算法分析的主要任务。
6、算法的代价及其度量
当一个算法消耗资源时,那么怎么来度量消耗的资源就成为了一个问题。因为计算的代价通常与实例的规模有关系(比如计算1013是否为素数与计算1001313130113是否为素数所花费的时间通常是不同的),因此,人们提出一个方法就是把一个计算开销定义为问题规模的函数。
也就是说,算法分析就是针对一个具体的算法,来确定一个函数关系。这个函数以问题实例的规模n为参量,来反映出这个算法在处理规模n的问题时所消耗的时间(或者空间)代价。
还有一些问题。
1>对于同一个问题,如果它的衡量标准不统一的话,那么得到的算法代价就会差距很大
例如计算素数问题,按照整数的数值作为标准和按照数字串长度作为标准是完全不一样的。这里,整数的数值与其数字串长度有着指数的关系。因此肯定这两个不同标准下得到的算法分析将也会差异很大。
2>对于同一个问题,即使对于同样规模的实例,计算的代价也可能不同
例如同样100个十进制整数,如果为偶数的话,很快就能得出结果。如果为奇数,则要花费很长的时间。
针对这些情况,我们在度量算法的时候。存在几种考虑:
算法A完成工作最少需要多长时间? #这个没有意义,因为它没有代表价值。
算法A完成工作最长需要多长时间? #在实际中,最主要是关注这种情况。
算法A完成工作平均需要多长时间? #对算法A的一个全面评价,但是没有保证。
由于这些问题,对于一个算法分析,给出一个具体精确的描述通常是非常困难的。因此退而求其次,我们设法估算算法复杂性的量级。这样,对于算法的时间和空间性质,最重要的是其量级和趋势,这些是算法代价中的主要部分,而常量因子可以忽略不计了。
基于这些考虑,提出”大O记法“来描述算法的性质。
其中最常用是下面的一组渐进复杂度函数:
O(1)、O(logn)、O(n)、O(nlogn)、O(n²)、O(n³)、O(2n)
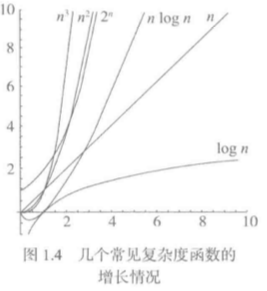
从图中就可以看出,随着实例规模的增大,它的算法复杂度增长趋势明显差异很大。算法的复杂度越高,其实施的代价随着规模增大而增大长的速度就快。
当然,这种算法复杂度的分析是具有实际的意义的。
比如,预测天气预报的程序,如果在今天晚上7点之前不能计算出预测明天的结果,那么这个算法就毫无意义。
解决同一问题的不同算法
例子:求斐波那契数列
1>递归算法
def fib(n):
if n < 2:
return1
return fib(n-1) + fib(n-2)
2>递推算法
def fib(n):
f1, f2 = 1, 1
for i in range(1, n):
f1, f2 = f2, f1+f2
return f2
当使用递归算法的时候,它的时间代价是呈指数增长的。因此,当n比较大时候,这一计算就需要很长的一段时间。
当使用递推算法的时候,它的时间代价是呈线性增长的。所以,相比较递归算法,这个有明显的时间优势。
7、算法分析
算法分析的目的是为了推导出算法的复杂度。书中给出了一些简单的规则
1> 基本操作
其时间复杂度为O(1)。如果是函数调用,应该将其时间复杂度带入,参与整体时间复杂度的计算。
2> 加法规则(顺序复合)
如果算法时两个部分的顺序复合,其复杂度是这两个部分的复杂度之和。
T(n) = T1(n) + T2(n) = O(T1(n)) + O(T2(n)) = O(max(T1(n), T2(n)))
由于忽略了常量因子,加法等于求最大值,所以取T1(n) 和 T2(n)中复杂度较高的一个。
3> 乘法规则(循环结构)
如果算法是一个循环,循环体将执行T1(n)次,每次执行需要T2(n)时间,那么:
T(n) = T1(n) * T2(n) = O(T1(n)) * O(T2(n)) = O(T1(n) * T2(n))
4> 取最大规则(分支结构)
如果算法时条件分支,两个分支的时间复杂性分别为T1(n)和T2(n),那么:
T(n) = O(max(T1(n), T2(n)))
利用一个例子计算一下:
for i in range(n):
for j in range(n):
x = 0.0 #O(1)
for k in range(n):
x = x + m1[i][k] * m2[k][j] #O(1)
m[i][j] = x #O(1)
x = x + m1[i][k] * m2[k][j] 这个操作是基本操作O(1)。
在for k in range(n)这个循环体内,它要执行n次。因此,这里就是O(1) * n = O(n)
在for j in range(n)这个循环体内,执行一次需要的时间为O(1) * n + O(1) + O(1) = O(max(O(n), O(1), O(1))) = O(n),而它也需要执行n次。因此这里就是O(n) * n = O(n²)
在for i in range(n)这个循环内,执行一次需要时间为O(n²),它也需要执行n次。因此整个算法时间复杂度为O(n³)。
8、python的计算代价
时间开销
python的很多基本操作并不是常量时间的。因此,需要我们在写程序的时候要注意使用合适的数据结构。在书中列举了很多,比如list的一般加入/删除。还有dict操作的查询和加入新的关键码(平均是O(1),但是最坏的是O(n),主要是利用哈希表技术构造成的)
空间开销
python关于空间开销有两个问题需要注意。
1> python的组合对象没有设置最大的元素个数。当对一个表不断添加元素,后来又删除元素,让表变小,但是占用的存储空间并不会变少。
2> python有着自己的存储管理系统,会将不用的对象进行回收(也就是python的垃圾回收机制)。
最后,还有一点需要注意。就是在考虑程序开发的时候,不但要选择比较好的算法,还要考虑如何做出良好的实现。例如:
def test1(n):
lst = []
for i in range(n*10000):
lst = lst + [i]
return lst
def test4(n):
return lst(range(n*10000))
上面的两种方式都能建立一个包含0-10000的整数,但是test1毫无必要的构造了很多的复杂结构,这样使整个算法的时间代价变得更高,从而损害了其可用性。这种情况就是高级语言程序中存在的一些“效率陷阱”。