时间复杂度
列表操作的大O效率:

字典操作的大O效率:

python的时间复杂度页面:
http://wiki.python.org/moin/TimeComplexity
基本数据结构
线性数据结构:栈、队列、双端队列、列表。
栈、队列、双端队列、列表都是有序的数据集合,其元素的顺序取决于添加顺序或移除顺序。一旦某个元素被添加进来,它与前后元素的相对位置将保持不变。这样的数据集合经常被称为线性数据结构。
线性数据结构可以看作有两端。这两端有时候被称作“左端”和“右端”,有时候也被称作“前端”和“后端”。当然,它们还可以被称作“顶端”和“底端”。名字本身并不重要,真正区分线性数据结构的是元素的添加方式和移除方式,尤其是添加操作和移除操作发生的位置。
栈
栈是有序集合,添加操作和移除操作总发生在同一端,即“顶端”,另一端则被称为“底端”。
栈中的元素离底端越近,代表其在栈中的时间越长,因此栈的底端具有非常重要的意义。最新添加的元素将被最先移除。这种排序原则被称作LIFO(last-in first-out),即后进先出。它提供了一种基于在集合中的时间来排序的方式。最近添加的元素靠近顶端,旧元素则靠近底端。
栈抽象数据类型:
stack()创建一个空栈。它不需要参数,且会返回一个空栈。
push(item)将一个元素添加到栈的顶端。它需要一个参数item,且无返回值。
pop()将栈顶端的元素移除。它不需要参数,但会返回顶端的元素,并且修改栈的内容。
peek()返回栈顶端的元素,但是并不移除该元素。它不需要参数,也不会修改栈的内容。
isEmpty()检查栈是否为空。它不需要参数,且会返回一个布尔值。
size()返回栈中元素的数目。它不需要参数,且会返回一个整数。
假设s是一个新创建的空栈。下表展示了对s进行一系列操作的结果。在“栈内容”一列中,栈顶端的元素位于最右侧。

用python实现栈:

也可以选择将列表的头部作为栈的顶端。不过在这种情况下,便无法直接使用pop方法和append方法,而必须要用pop方法和insert方法显式地访问下标为0的元素,即列表中的第1个元素。

不过,尽管上述两种实现都可行,但是二者在性能方面肯定有差异。append方法和pop()方法的时间复杂度都是O(1),这意味着不论栈中有多少个元素,第一种实现中的push操作和pop操作都会在恒定的时间内完成。第二种实现的性能则受制于栈中的元素个数,这是因为insert(0)和pop(0)的时间复杂度都是O(n),元素越多就越慢。显而易见,尽管两种实现在逻辑上是相等的,但是它们在进行基准测试时耗费的时间会有很大的差异。
括号匹配:
匹配括号是指每一个左括号都有与之对应的一个右括号,并且括号对有正确的嵌套关系。
由一个空栈开始,从左往右依次处理括号。如果遇到左括号,便通过push操作将其加入栈中,以此表示稍后需要有一个与之匹配的右括号。反之,如果遇到右括号,就调用pop操作。只要栈中的所有左括号都能遇到与之匹配的右括号,那么整个括号串就是匹配的;如果栈中有任何一个左括号找不到与之匹配的右括号,则括号串就是不匹配的。在处理完匹配的括号串之后,栈应该是空的。
 parChecker函数假设Stack类可用,并且会返回一个布尔值来表示括号串是否匹配。注意,布尔型变量balanced的初始值是True,这是因为一开始没有任何理由假设其为False。如果当前的符号是左括号,它就会被压入栈中(第9~10行)。注意第15行,仅通过pop()将一个元素从栈中移除。由于移除的元素一定是之前遇到的左括号,因此并没有用到pop()的返回值。在第19~22行,只要所有括号匹配并且栈为空,函数就会返回True,否则返回False。
parChecker函数假设Stack类可用,并且会返回一个布尔值来表示括号串是否匹配。注意,布尔型变量balanced的初始值是True,这是因为一开始没有任何理由假设其为False。如果当前的符号是左括号,它就会被压入栈中(第9~10行)。注意第15行,仅通过pop()将一个元素从栈中移除。由于移除的元素一定是之前遇到的左括号,因此并没有用到pop()的返回值。在第19~22行,只要所有括号匹配并且栈为空,函数就会返回True,否则返回False。
符号匹配:
符号匹配是许多编程语言中的常见问题,括号匹配问题只是一个特例。匹配符号是指正确地匹配和嵌套左右对应的符号。例如,在Python中,方括号[和]用于列表;花括号{和}用于字典;括号(和)用于元组和算术表达式。只要保证左右符号匹配,就可以混用这些符号。在正确的符号串的匹配中,不仅每一个左符号都有一个右符号与之对应,而且两个符号的类型也是一致的。
每一个左符号都将被压入栈中,以待之后出现对应的右符号。唯一的区别在于,当出现右符号时,必须检测其类型是否与栈顶的左符号类型相匹配。如果两个符号不匹配,那么整个符号串也就不匹配。同样,如果整个符号串处理完成并且栈是空的,那么就说明所有符号正确匹配。
 唯一的改动在第17行,我们调用了一个辅助函数来匹配符号。必须检测每一个从栈顶移除的符号是否与当前的右符号相匹配。如果不匹配,布尔型变量balanced就被设成False。
唯一的改动在第17行,我们调用了一个辅助函数来匹配符号。必须检测每一个从栈顶移除的符号是否与当前的右符号相匹配。如果不匹配,布尔型变量balanced就被设成False。
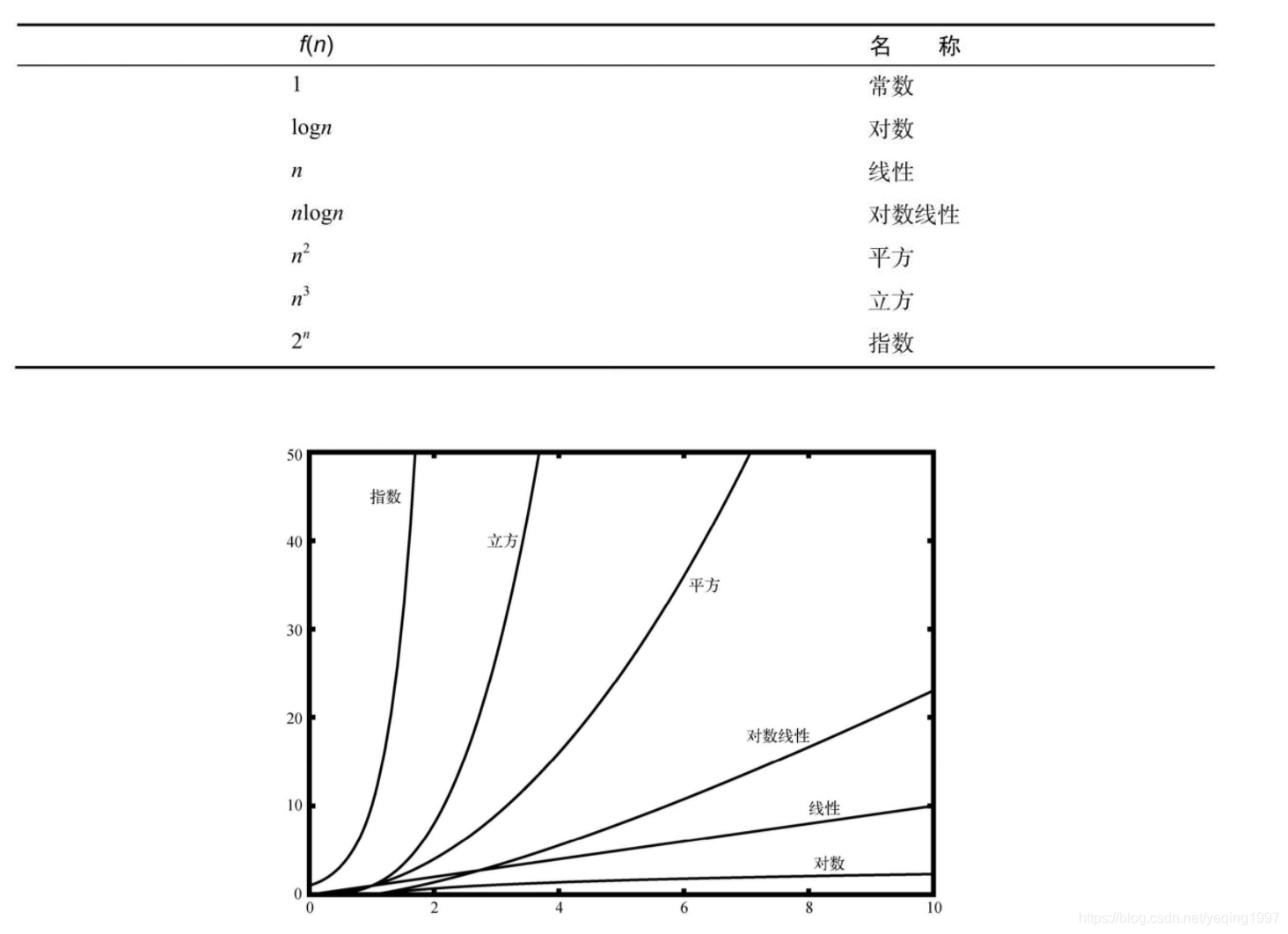
将十进制转化为二进制:
十进制数233(10)及其对应的二进制数11101001(2)可以分别按下面的形式表示。
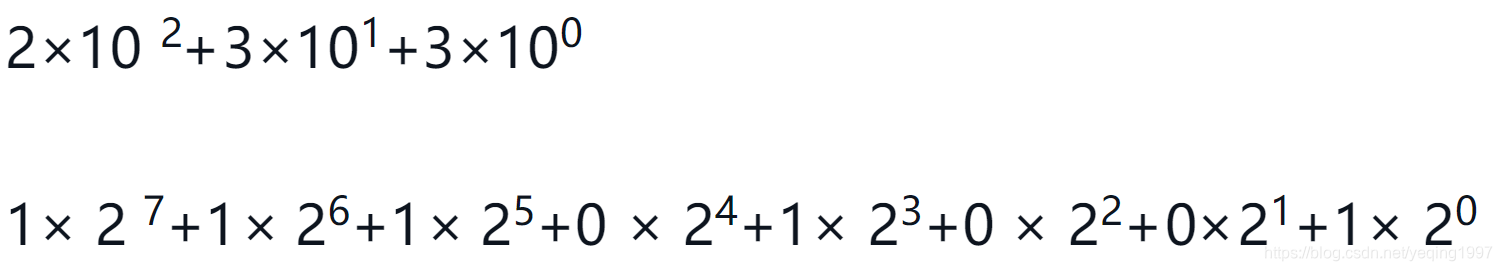
利用一种叫作“除以2”的算法,该算法使用栈来保存二进制结果的每一位。
“除以2”算法假设待处理的整数大于0。它用一个简单的循环不停地将十进制数除以2,并且记录余数。第一次除以2的结果能够用于区分偶数和奇数。如果是偶数,则余数为0,因此个位上的数字为0;如果是奇数,则余数为1,因此个位上的数字为1。可以将要构建的二进制数看成一系列数字;计算出的第一个余数是最后一位。
divideBy2函数接受一个十进制数作为参数,然后不停地将其除以2。第6行使用了内建的取余运算符%,第7行将求得的余数压入栈中。当除法过程遇到0之后,第10~12行就会构建一个二进制数字串。第10行创建一个空串。随后,二进制数字从栈中被逐个取出,并添加到数字串的最右边。最后,函数返回该二进制数字串。

可以将divideBy2函数修改成接受一个十进制数以及希望转换的进制基数,“除以2”则变成“除以基数”。
baseConverter函数接受一个十进制数和一个2~16的基数作为参数。处理方法仍然是将余数压入栈中,直到被处理的值为0。之前的从左到右构建数字串的方法只需要修改一处。以2~10为基数时,最多只需要10个数字,因此0~9这10个整数够用。当基数超过10时,就会遇到问题。不能再直接使用余数,这是因为余数本身就是两位的十进制数。因此,需要创建一套数字来表示大于9的余数。
一种解决方法是添加一些字母字符到数字中。例如,十六进制使用10个数字以及前6个字母来代表16位数字。在代码清单3-6中,为了实现这一方法,第3行创建了一个数字字符串来存储对应位置上的数字。0在位置0,1在位置1, A在位置10, B在位置11,依此类推。当从栈中移除一个余数时,它可以被用作访问数字的下标,对应的数字会被添加到结果中。如果从栈中移除的余数是13,那么字母D将被添加到结果字符串的最后。

前序、中序和后序表达式:

A + B *C可以被重写为前序表达式+ A *B C。乘号出现在B和C之前,代表着它的优先级高于加号。加号出现在A和乘法结果之前。A + B *C对应的后序表达式是A B C *+。运算顺序仍然得以正确保留,这是由于乘号紧跟B和C出现,意味着它的优先级比加号更高。

现在来看看中序表达式(A + B) *C。括号用来保证加号的优先级高于乘号。但是,当A+ B被写成前序表达式时,只需将加号移到操作数之前,即+ A B。于是,加法结果就成了乘号的第一个操作数。乘号被移到整个表达式的最前面,从而得到*+ A BC。同理,后序表达式A B +保证优先计算加法。乘法则在得到加法结果之后再计算。因此,正确的后序表达式为A B + C *。
在后两个表达式中,括号去哪里了?为什么前序表达式和后序表达式不需要括号?答案是,这两种表达式中的运算符所对应的操作数是明确的。只有中序表达式需要额外的符号来消除歧义。前序表达式和后序表达式的运算顺序完全由运算符的位置决定。鉴于此,中序表达式是最不理想的算式表达法。
①从中序向前序和后序的转换
从中序到后序的通用转换法:
再一次研究A + B *C这个例子。如前所示,其对应的后序表达式为A B C *+。操作数A、B和C的相对位置保持不变,只有运算符改变了位置。再观察中序表达式中的运算符。从左往右看,第一个出现的运算符是+。但是在后序表达式中,由于*的优先级更高,因此*先于+出现。在本例中,中序表达式的运算符顺序与后序表达式的相反。
在转换过程中,由于运算符右边的操作数还未出现,因此需要将运算符保存在某处。同时,由于运算符有不同的优先级,因此可能需要反转它们的保存顺序。本例中的加号与乘号就是这种情况。由于中序表达式中的加号先于优先级更高的乘号出现,因此后序表达式需要反转它们的出现顺序。鉴于这种反转特性,使用栈来保存运算符就显得十分合理。
对于(A + B) *C,情况会如何呢?它对应的后序表达式为A B +C *。从左往右看,首先出现的运算符是+。不过,由于括号改变了运算符的优先级,因此当处理到*时,+已经被放入结果表达式中了。现在可以来总结转换算法:当遇到左括号时,需要将其保存,以表示接下来会遇到高优先级的运算符;那个运算符需要等到对应的右括号出现才能确定其位置(回忆一下完全括号表达式的转换法);当右括号出现时,便可以将运算符从栈中取出来。
在从左往右扫描中序表达式时,我们利用栈来保存运算符。这样做可以提供反转特性。栈的顶端永远是最新添加的运算符。每当遇到一个新的运算符时,都需要对比它与栈中运算符的优先级。
假设中序表达式是一个以空格分隔的标记串。其中,运算符标记有*、/、+和-,括号标记有(和),操作数标记有A、B、C等。下面的步骤会生成一个后序标记串。
(1) 创建用于保存运算符的空栈opstack,以及一个用于保存结果的空列表。
(2) 使用字符串方法split将输入的中序表达式转换成一个列表。
(3) 从左往右扫描这个标记列表。
如果标记是操作数,将其添加到结果列表的末尾。
如果标记是左括号,将其压入opstack栈中。
如果标记是右括号,反复从opstack栈中移除元素,直到移除对应的左括号。将从栈中取出的每一个运算符都添加到结果列表的末尾。
如果标记是运算符,将其压入opstack栈中。但是,在这之前,需要先从栈中取出优先级更高或相同的运算符,并将它们添加到结果列表的末尾。
(4) 当处理完输入表达式以后,检查opstack。将其中所有残留的运算符全部添加到结果列表的末尾。
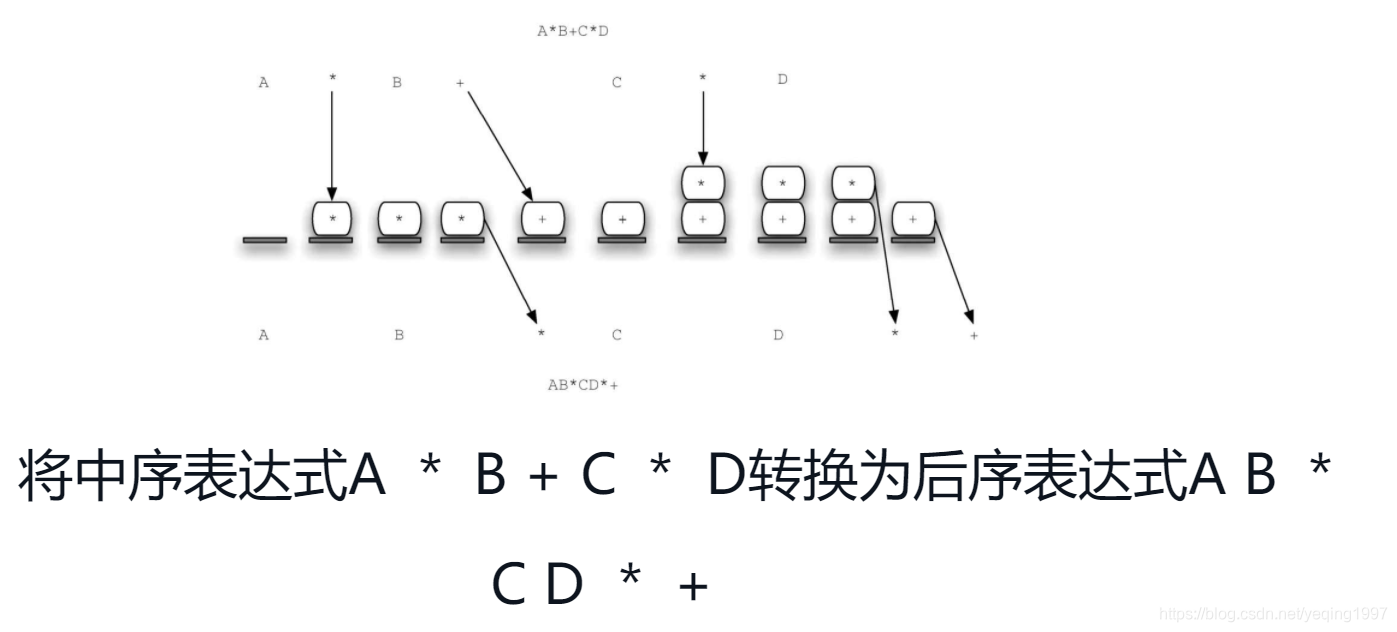
利用上述算法转换A *B + C *D的过程。注意,第一个*在处理至+时被移出栈。由于乘号的优先级高于加号,因此当第二个*出现时,+仍然留在栈中。在中序表达式的最后,进行了两次出栈操作,用于移除两个运算符,并将+放在后序表达式的末尾。
为了在Python中实现这一算法,我们使用一个叫作prec的字典来保存运算符的优先级值。该字典把每一个运算符都映射成一个整数。通过比较对应的整数,可以确定运算符的优先级(本例随意地使用了3、2、1)。左括号的优先级值最小。这样一来,任何与左括号比较的运算符都会被压入栈中。我们也将导入string模块,它包含一系列预定义变量。本例使用一个包含所有大写字母的字符串(string.ascii_uppercase)来代表所有可能出现的操作数。

②计算后序表达式
计算后序表达式时,栈再一次成为适合选择的数据结构。不过,当扫描后序表达式时,需要保存操作数,而不是运算符。换一个角度来说,当遇到一个运算符时,需要用离它最近的两个操作数来计算。
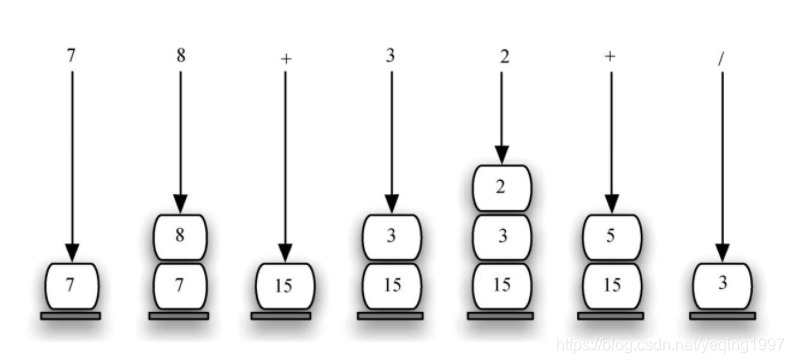
为了进一步理解该算法,考虑后序表达式45 6 *+。当从左往右扫描该表达式时,首先会遇到操作数4和5。在遇到下一个符号之前,我们并不确定要对它们进行什么运算。将它们都保存在栈中,便可以在需要时取用。
在本例中,紧接着出现的符号又是一个操作数。因此,将6也压入栈中,并继续检查后面的符号。现在遇到运算符*,这意味着需要将最近遇到的两个操作数相乘。通过执行两次出栈操作,可以得到相应的操作数,然后进行乘法运算(本例的结果是30)。
接着,将结果压入栈中。这样一来,当遇到后面的运算符时,它就可以作为操作数。当处理完最后一个运算符之后,栈中只剩一个值。将这个值取出来,并作为表达式的结果返回。下图展示了栈的内容在整个计算过程中的变化。

更复杂的例子:78 + 32 + /。有两处需要注意。首先,伴随着子表达式的计算,栈增大、缩小,然后再一次增大。其次,处理除法运算时需要非常小心。由于后序表达式只改变运算符的位置,因此操作数的位置与在中序表达式中的位置相同。当从栈中取出除号的操作数时,它们的顺序颠倒了。由于除号不是可交换的运算符(15/5和5/15的结果不相同),因此必须保证操作数的顺序没有颠倒。
假设后序表达式是一个以空格分隔的标记串。其中,运算符标记有*、/、+和-,操作数标记是一位的整数值。结果是一个整数。
(1) 创建空栈operandStack。
(2) 使用字符串方法split将输入的后序表达式转换成一个列表。
(3) 从左往右扫描这个标记列表。
如果标记是操作数,将其转换成整数并且压入operandStack栈中。
如果标记是运算符,从operandStack栈中取出两个操作数。第一次取出右操作数,第二次取出左操作数。进行相应的算术运算,然后将运算结果压入operandStack栈中。
(4) 当处理完输入表达式时,栈中的值就是结果。将其从栈中返回。
下面的代码是计算后序表达式的完整函数。为了方便运算,我们定义了辅助函数doMath。它接受一个运算符和两个操作数,并进行相应的运算。

需要注意的是,在后序表达式的转换和计算中,我们都假设输入表达式没有错误。
队列
队列是有序集合,添加操作发生在“尾部”,移除操作则发生在“头部”。新元素从尾部进入队列,然后一直向前移动到头部,直到成为下一个被移除的元素。
最新添加的元素必须在队列的尾部等待,在队列中时间最长的元素则排在最前面。这种排序原则被称作FIFO(first-in first-out),即先进先出,也称先到先得。
操作系统使用一些队列来控制计算机进程。调度机制往往基于一个队列算法,其目标是尽可能快地执行程序,同时服务尽可能多的用户。在打字时,我们有时会发现字符出现的速度比击键速度慢。这是由于计算机正在做其他的工作。击键操作被放入一个类似于队列的缓冲区,以便对应的字符按正确的顺序显示。
队列抽象数据类型
队列抽象数据类型由下面的结构和操作定义。如前所述,队列是元素的有序集合,添加操作发生在其尾部,移除操作则发生在头部。队列的操作顺序是FIFO,它支持以下操作。
Queue()创建一个空队列。它不需要参数,且会返回一个空队列。
enqueue(item)在队列的尾部添加一个元素。它需要一个元素作为参数,不返回任何值。
dequeue()从队列的头部移除一个元素。它不需要参数,且会返回一个元素,并修改队列的内容。
isEmpty()检查队列是否为空。它不需要参数,且会返回一个布尔值。
size()返回队列中元素的数目。它不需要参数,且会返回一个整数。
假设q是一个新创建的空队列。下表展示了对q进行一系列操作的结果。在“队列内容”一列中,队列的头部位于右端。4是第一个被添加到队列中的元素,因此它也是第一个被移除的元素。

用python实现队列
需要确定列表的哪一端是队列的尾部,哪一端是头部。
代码的实现假设队列的尾部在列表的位置0处。如此一来,便可以使用insert函数向队列的尾部添加新元素。pop则可用于移除队列头部的元素(列表中的最后一个元素)。这意味着添加操作的时间复杂度是O( )n,移除操作则是O(1)。

双端队列
与栈和队列不同的是,双端队列的限制很少。它的英文名为deque(与deck同音)。
双端队列是与队列类似的有序集合。它有一前、一后两端,元素在其中保持自己的位置。与队列不同的是,双端队列对在哪一端添加和移除元素没有任何限制。新元素既可以被添加到前端,也可以被添加到后端。同理,已有的元素也能从任意一端移除。某种意义上,双端队列是栈和队列的结合。
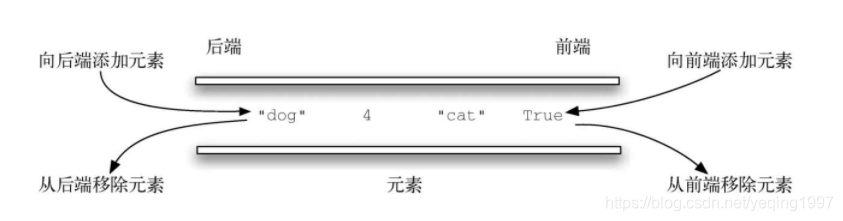
值得注意的是,尽管双端队列有栈和队列的很多特性,但是它并不要求按照这两种数据结构分别规定的LIFO原则和FIFO原则操作元素。具体的排序原则取决于其使用者。
双端队列抽象数据类型由下面的结构和操作定义。如前所述,双端队列是元素的有序集合,其任何一端都允许添加或移除元素。双端队列支持以下操作。
Deque()创建一个空的双端队列。它不需要参数,且会返回一个空的双端队列。
addFront(item)将一个元素添加到双端队列的前端。它接受一个元素作为参数,没有返回值。
addRear(item)将一个元素添加到双端队列的后端。它接受一个元素作为参数,没有返回值。
removeFront()从双端队列的前端移除一个元素。它不需要参数,且会返回一个元素,并修改双端队列的内容。
removeRear()从双端队列的后端移除一个元素。它不需要参数,且会返回一个元素,并修改双端队列的内容。
isEmpty()检查双端队列是否为空。它不需要参数,且会返回一个布尔值。
size()返回双端队列中元素的数目。它不需要参数,且会返回一个整数。
假设d是一个新创建的空双端队列,下表展示了对d进行一系列操作的结果。注意,前端在列表的右端。记住前端和后端的位置可以防止混淆。

用python实现双端队列

removeFront使用pop方法移除列表中的最后一个元素,removeRear则使用pop(0)方法移除列表中的第一个元素。同理,之所以addRear使用insert方法,是因为append方法只能在列表的最后添加元素。
实现双端队列的Python代码与实现栈和队列的有许多相似之处。在双端队列的Python实现中,在前端进行的添加操作和移除操作的时间复杂度是O(1),在后端的则是O( )n。考虑到实现时采用的操作,这不难理解。再次强调,记住前后端的位置非常重要。
回文检测器
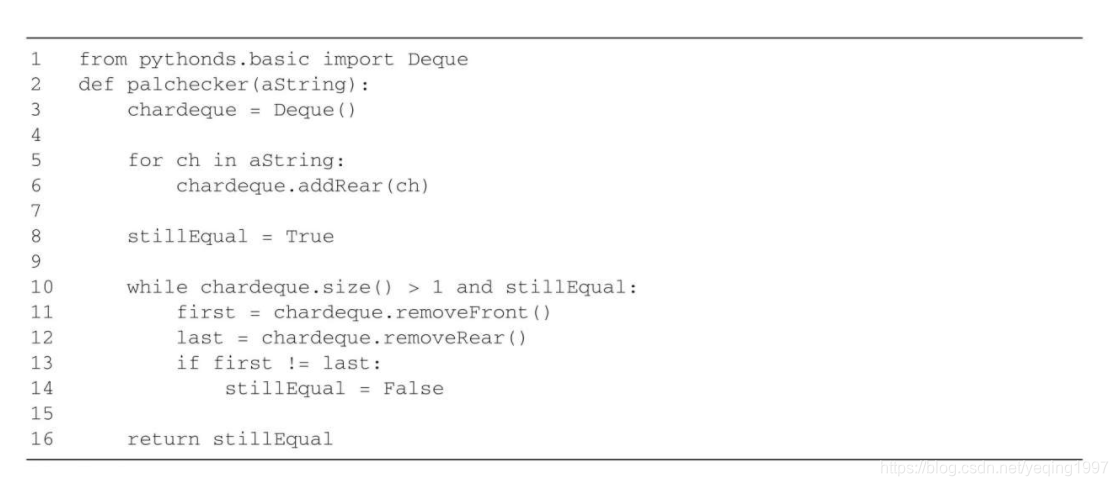
运用双端队列可以解决一个非常有趣的经典问题:回文问题。回文是指从前往后读和从后往前读都一样的字符串,例如radar、toot,以及madam。我们将构建一个程序,它接受一个字符串并且检测其是否为回文。该问题的解决方案是使用一个双端队列来存储字符串中的字符。按从左往右的顺序将字符串中的字符添加到双端队列的后端。此时,该双端队列类似于一个普通的队列。然而,可以利用双端队列的双重性,其前端是字符串的第一个字符,后端是字符串的最后一个字符。
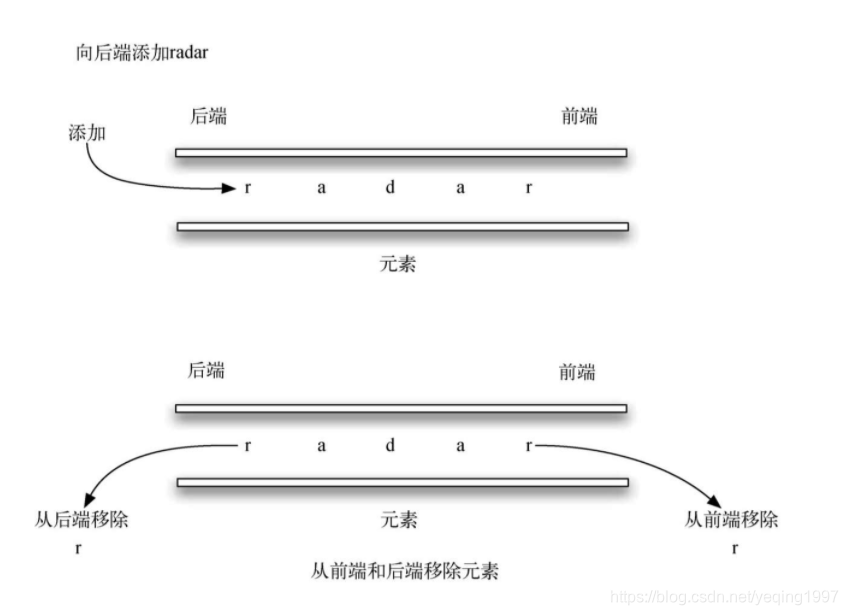
由于可以从前后两端移除元素,因此我们能够比较两个元素,并且只有在二者相等时才继续。如果一直匹配第一个和最后一个元素,最终会处理完所有的字符(如果字符数是偶数),或者剩下只有一个元素的双端队列(如果字符数是奇数)。任意一种结果都表明输入字符串是回文。
列表
列表是元素的集合,其中每一个元素都有一个相对于其他元素的位置。更具体地说,这种列表称为无序列表。可以认为列表有第一个元素、第二个元素、第三个元素,等等;也可以称第一个元素为列表的起点,称最后一个元素为列表的终点。为简单起见,我们假设列表中没有重复元素。
①无序列表抽象数据类型
无序列表是元素的集合,其中每一个元素都有一个相对于其他元素的位置。以下是无序列表支持的操作。
List()创建一个空列表。它不需要参数,且会返回一个空列表。
add(item)假设元素item之前不在列表中,并向其中添加item。它接受一个元素作为参数,无返回值。
remove(item)假设元素item已经在列表中,并从其中移除item。它接受一个元素作为参数,并且修改列表。
search(item)在列表中搜索元素item。它接受一个元素作为参数,并且返回布尔值。
isEmpty()检查列表是否为空。它不需要参数,并且返回布尔值。
length()返回列表中元素的个数。它不需要参数,并且返回一个整数。
append(item)假设元素item之前不在列表中,并在列表的最后位置添加item。它接受一个元素作为参数,无返回值。
index(item)假设元素item已经在列表中,并返回该元素在列表中的位置。它接受一个元素作为参数,并且返回该元素的下标。
insert(pos, item)假设元素item之前不在列表中,同时假设pos是合理的值,并在位置pos处添加元素item。它接受两个参数,无返回值。
pop()假设列表不为空,并移除列表中的最后一个元素。它不需要参数,且会返回一个元素。
pop(pos)假设在指定位置pos存在元素,并移除该位置上的元素。它接受位置参数,且会返回一个元素。
②实现无序列表:链表
为了实现无序列表,我们要构建链表。无序列表需要维持元素之间的相对位置,但是并不需要在连续的内存空间中维护这些位置信息。以下图中的元素集合为例,这些元素的位置看上去都是随机的。如果可以为每一个元素维护一份信息,即下一个元素的位置,那么这些元素的相对位置就能通过指向下一个元素的链接来表示。


需要注意的是,必须指明列表中第一个元素的位置。一旦知道第一个元素的位置,就能根据其中的链接信息访问第二个元素,接着访问第三个元素,依此类推。指向链表第一个元素的引用被称作头。最后一个元素需要知道自己没有下一个元素。
Node类
节点(node)是构建链表的基本数据结构。每一个节点对象都必须持有至少两份信息。首先,节点必须包含列表元素,我们称之为节点的数据变量。其次,节点必须保存指向下一个节点的引用。
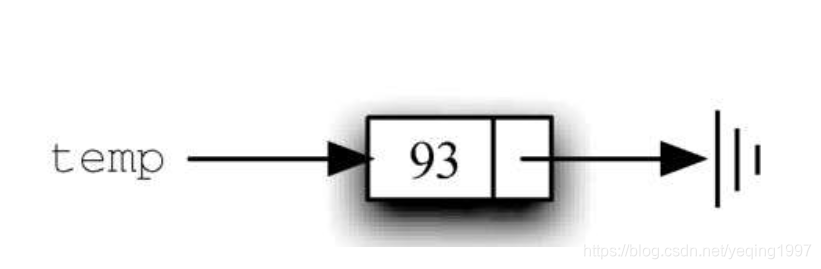
代码展示了Node类的Python实现。在构建节点时,需要为其提供初始值。执行下面的赋值语句会生成一个包含数据值93的节点对象。
需要注意的是,一般会像图2所示的那样表示节点。
Node类也包含访问和修改数据的方法,以及指向下一个元素的引用。


特殊的Python引用值None在Node类以及之后的链表中起到了重要的作用。指向None的引用代表着后面没有元素。注意,Node的构造方法将next的初始值设为None。由于这有时被称为“将节点接地”,因此我们使用接地符号来代表指向None的引用。将None作为next的初始值是不错的做法。

UnorderedList类
如前所述,无序列表(unordered list)是基于节点集合来构建的,每一个节点都通过显式的引用指向下一个节点。只要知道第一个节点的位置(第一个节点包含第一个元素),其后的每一个元素都能通过下一个引用找到。因此,UnorderedList类必须包含指向第一个节点的引用。代码展示了UnorderedList类的构造方法。注意,每一个列表对象都保存了指向列表头部的引用。

最开始构建列表时,其中没有元素。赋值语句mylist =UnorderedList()将创建如图3-22所示的链表。与在Node类中一样,特殊引用值None用于表明列表的头部没有指向任何节点。最终,前面给出的样例列表将由如图所示的链表来表示。列表的头部指向包含列表第一个元素的节点。这个节点包含指向下一个节点(元素)的引用,依此类推。非常重要的一点是,列表类本身并不包含任何节点对象,而只有指向整个链表结构中第一个节点的引用。
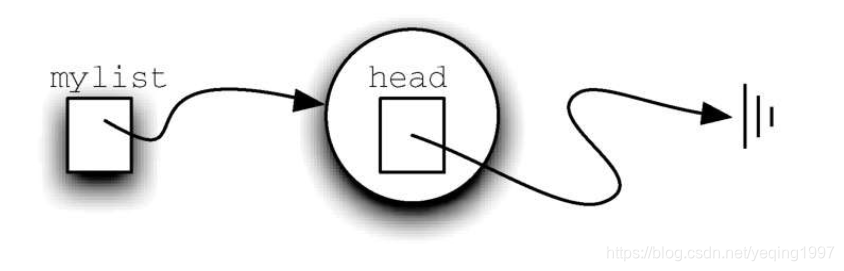

在代码中,isEmpty方法检查列表的头部是否为指向None的引用。布尔表达式self.head == None当且仅当链表中没有节点时才为真。由于新的链表是空的,因此构造方法必须和检查是否为空的方法保持一致。这体现了使用None表示链表末尾的好处。在Python中,None可以和任何引用进行比较。如果两个引用都指向同一个对象,那么它们就是相等的。我们将在后面的方法中经常使用这一特性。

为了将元素添加到列表中,需要实现add方法。但在实现之前,需要解决一个重要问题:新元素要被放在链表的哪个位置?由于本例中的列表是无序的,因此新元素相对于已有元素的位置并不重要。新的元素可以在任意位置。因此,将新元素放在最简便的位置是最合理的选择。
由于链表只提供一个入口(头部),因此其他所有节点都只能通过第一个节点以及next链接来访问。这意味着添加新节点最简便的位置就是头部,或者说链表的起点。我们把新元素作为列表的第一个元素,并且把已有的元素链接到该元素的后面。
通过多次调用add方法,可以构建出上图的链表。

注意,由于31是第一个被加入列表的元素,因此随着后续元素不断被加入列表,它最终成了最后一个元素。同理,由于54是最后一个被添加的元素,因此它成为链表中第一个节点的数据值。
下面的代码展示了add方法的实现。列表中的每一个元素都必须被存放在一个节点对象中。第2行创建一个新节点,并且将元素作为其数据。现在需要将新节点与已有的链表结构链接起来。这一过程需要两步,如图所示。第1步(第3行),将新节点的next引用指向当前列表中的第一个节点。这样一来,原来的列表就和新节点正确地链接在了一起。第2步,修改列表的头节点,使其指向新创建的节点。第4行的赋值语句完成了这一操作。
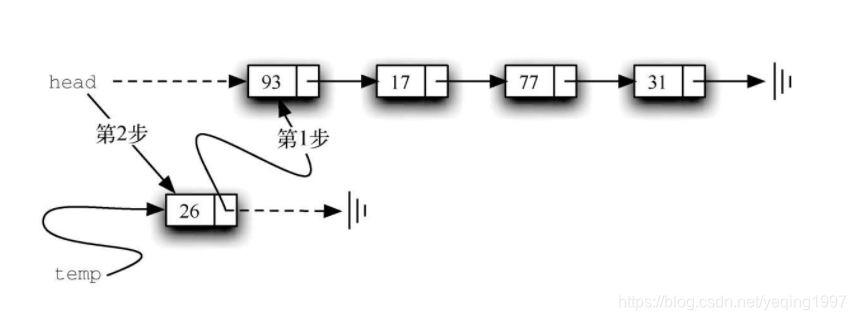

上述两步的顺序非常重要。如果颠倒第3行和第4行的顺序,会发生什么呢?如果先修改列表的头节点,将得到如图所示的结果。由于头节点是唯一指向列表节点的外部引用,因此所有的已有节点都将丢失并且无法访问。

接下来要实现的方法——length、search以及remove——都基于链表遍历这个技术。遍历是指系统地访问每一个节点,具体做法是用一个外部引用从列表的头节点开始访问。随着访问每一个节点,我们将这个外部引用通过“遍历”下一个引用来指向下一个节点。
为了实现length方法,需要遍历链表并且记录访问过多少个节点。代码展示了计算列表中节点个数的Python代码。current就是外部引用,它在第2行中被初始化为列表的头节点。在计算开始时,由于没有访问到任何节点,因此count被初始化为0。第4~6行实现遍历过程。只要current引用没有指向列表的结尾(None),就将它指向下一个节点(第6行)。引用能与None进行比较,这一特性非常重要。每当current指向一个新节点时,将count加1。最终,循环完成后返回count。下图展示了整个处理过程。


在无序列表中搜索一个值同样也会用到遍历技术。每当访问一个节点时,检查该节点中的元素是否与要搜索的元素相同。在搜索时,可能并不需要完整遍历列表就能找到该元素。事实上,如果遍历到列表的末尾,就意味着要找的元素不在列表中。如果在遍历过程中找到所需的元素,就没有必要继续遍历了。
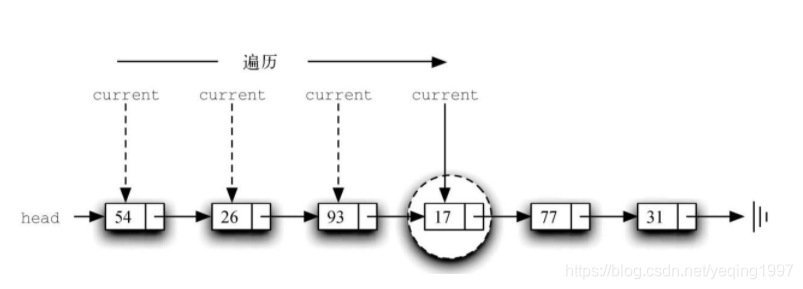
代码展示了search方法的实现。与在length方法中相似,遍历从列表的头部开始(第2行)。我们使用布尔型变量found来标记是否找到所需的元素。由于一开始时并未找到该元素,因此第3行将found初始化为False。第4行的循环既考虑了是否到达列表末尾,也考虑了是否已经找到目标元素。只要还有未访问的节点并且还没有找到目标元素,就继续检查下一个节点。第5行检查当前节点中的元素是否为目标元素。如果是,就将found设为True。

以下调用search方法来寻找元素17。

由于17在列表中,因此遍历过程只需进行到含有17的节点即可。此时,found变量被设为True,从而使while循环退出,最终得到上面的输出结果。如图展示了这一过程。
remove方法在逻辑上需要分两步。第1步,遍历列表并查找要移除的元素。一旦找到该元素(假设元素在列表中),就必须将其移除。第1步与search非常相似。从一个指向列表头节点的外部引用开始,遍历整个列表,直到遇到需要移除的元素。由于假设目标元素已经在列表中,因此我们知道循环会在current抵达None之前结束。这意味着可以在判断条件中使用布尔型变量found。
当found被设为True时,current将指向需要移除的节点。该如何移除它呢?一种做法是将节点包含的值替换成表示其已被移除的值。这种做法的问题是,节点的数量和元素的数量不再匹配。更好的做法是移除整个节点。
为了将包含元素的节点移除,需要将其前面的节点中的next引用指向current之后的节点。然而,并没有反向遍历链表的方法。由于current已经指向了需要修改的节点之后的节点,此时做修改为时已晚。
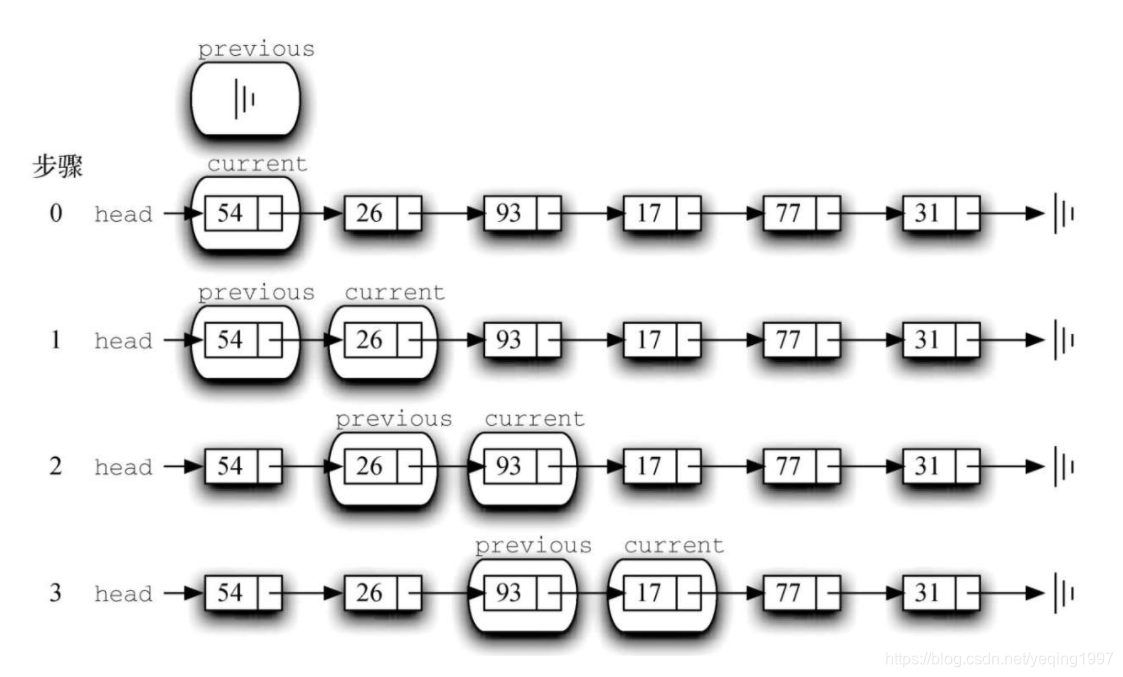
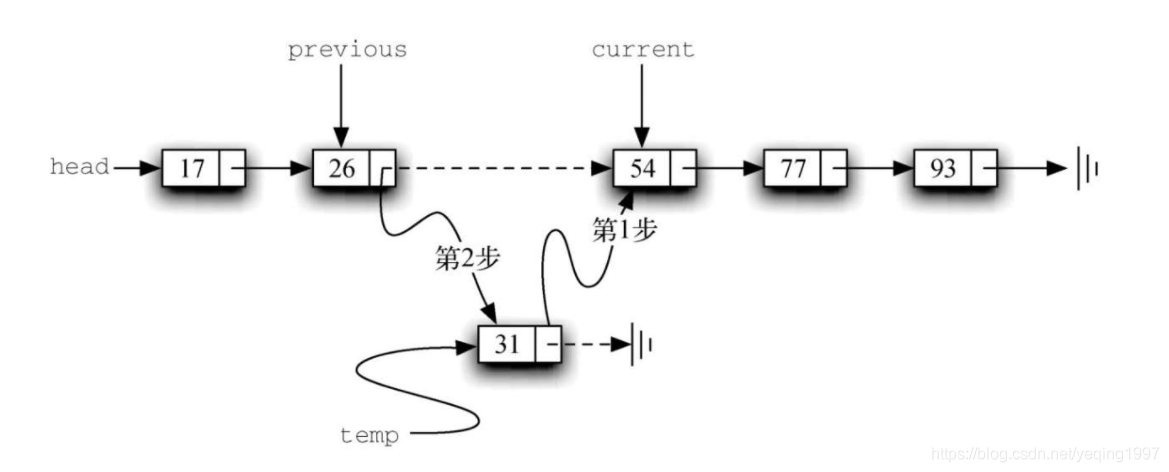
这一困境的解决方法就是在遍历链表时使用两个外部引用。current与之前一样,标记在链表中的当前位置。新的引用previous总是指向current上一次访问的节点。这样一来,当current指向需要被移除的节点时,previous就刚好指向真正需要修改的节点。
代码展示了完整的remove方法。第2~3行对两个引用进行初始赋值。注意,current与其他遍历例子一样,从列表的头节点开始。由于头节点之前没有别的节点,因此previous的初始值是None,如图所示。布尔型变量found再一次被用来控制循环。
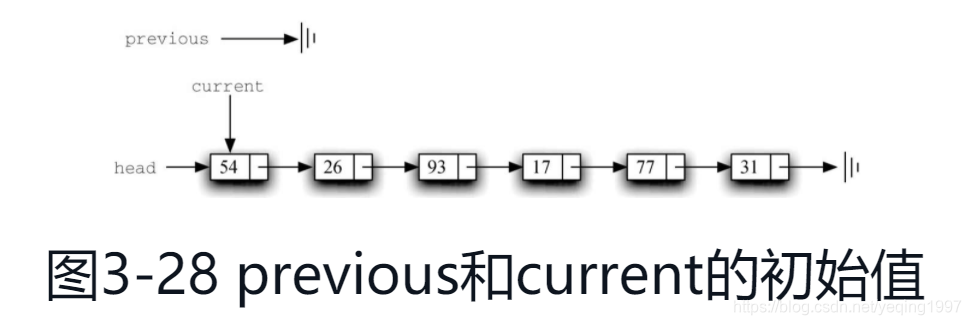

第6~7行检查当前节点中的元素是否为要移除的元素。如果是,就设found为True。如果否,则将previous和current往前移动一次。这两条语句的顺序十分重要。必须先将previous移动到current的位置,然后再移动current。这一过程经常被称为“蠕动”,因为previous必须在current向前移动之前指向其当前位置。下图展示了在遍历列表寻找包含17的节点的过程中,previous和current的移动过程。
一旦搜索过程结束,就需要执行移除操作。下图1展示了修改过程。有一种特殊情况需要注意:如果被移除的元素正好是链表的第一个元素,那么current会指向链表中的第一个节点,previous的值则是None。在这种情况下,需要修改链表的头节点,而不是previous指向的节点,如图2所示。
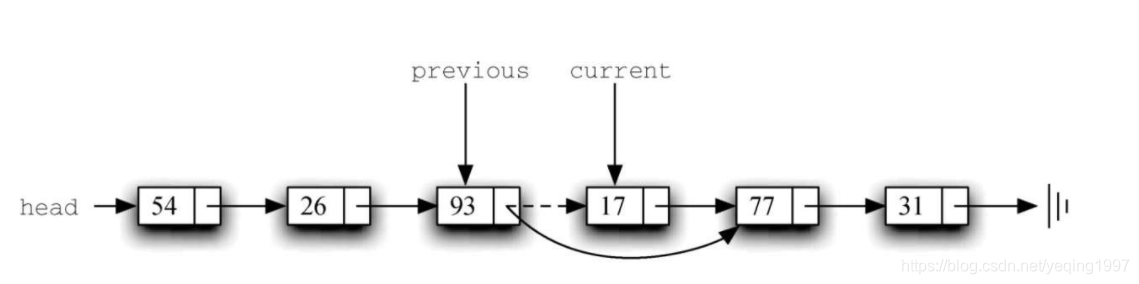
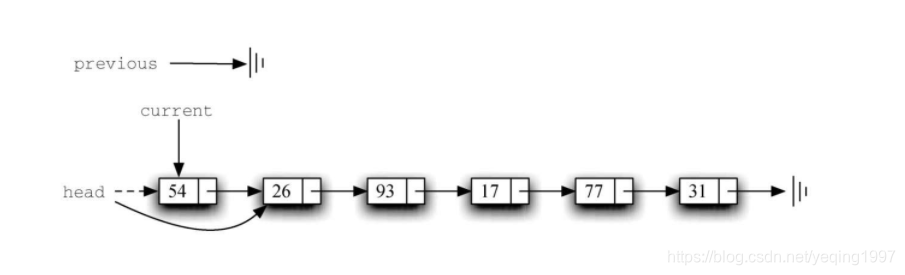
第12行检查是否遇到上述特殊情况。如果previous没有移动,当found被设为True时,它的值仍然是None。在这种情况下(第13行),链表的头节点被修改成指向当前头节点的下一个节点,从而达到移除头节点的效果。但是,如果previous的值不是None,则说明需要移除的节点在链表结构中的某个位置。在这种情况下,previous指向了next引用需要被修改的节点。第15行使用previous的setNext方法来完成移除操作。注意,在两种情况中,修改后的引用都指向current.getNext()。一个常被提及的问题是,已有的逻辑能否处理移除最后一个节点的情况。
③有序列表抽象数据类型
接下来学习有序列表。如果前文中的整数列表是以升序排列的有序列表,那么它会被写作17, 26, 31, 54, 77, 93。由于17是最小的元素,因此它就成了列表的第一个元素。同理,由于93是最大的元素,因此它在列表的最后一个位置。
在有序列表中,元素的相对位置取决于它们的基本特征。它们通常以升序或者降序排列,并且我们假设元素之间能进行有意义的比较。有序列表的众多操作与无序列表的相同。
orderedList()创建一个空有序列表。它不需要参数,且会返回一个空列表。
add(item)假设item之前不在列表中,并向其中添加item,同时保持整个列表的顺序。它接受一个元素作为参数,无返回值。
remove(item)假设item已经在列表中,并从其中移除item。它接受一个元素作为参数,并且修改列表。
search(item)在列表中搜索item。它接受一个元素作为参数,并且返回布尔值。
isEmpty()检查列表是否为空。它不需要参数,并且返回布尔值。
length()返回列表中元素的个数。它不需要参数,并且返回一个整数。
index(item)假设item已经在列表中,并返回该元素在列表中的位置。它接受一个元素作为参数,并且返回该元素的下标。
pop()假设列表不为空,并移除列表中的最后一个元素。它不需要参数,且会返回一个元素。
pop(pos)假设在指定位置pos存在元素,并移除该位置上的元素。它接受位置参数,且会返回一个元素。
④实现有序列表
在实现有序列表时必须记住,元素的相对位置取决于它们的基本特征。整数有序列表17, 26, 31, 54, 77, 93可以用如图所示的链式结构来表示。

OrderedList类的构造方法与UnorderedList类的相同。head引用指向None,代表这是一个空列表,代码如下。

因为isEmpty和length仅与列表中的节点数目有关,而与实际的元素值无关,所以这两个方法在有序列表中的实现与在无序列表中一样。同理,由于仍然需要找到目标元素并且通过更改链接来移除节点,因此remove方法的实现也一样。剩下的两个方法,search和add,需要做一些修改。
在无序列表中搜索时,需要逐个遍历节点,直到找到目标节点或者没有节点可以访问。这个方法同样适用于有序列表,但前提是列表包含目标元素。如果目标元素不在列表中,可以利用元素有序排列这一特性尽早终止搜索。
举一个例子。下图展示了在有序列表中搜索45的情况。从列表的头节点开始遍历,首先比较45和17。由于17不是要查找的元素,因此移向下一个节点,即26。它也不是要找的元素,所以继续向前比较31和之后的54。由于54不是要查找的元素,因此在无序列表中,我们会继续搜索。但是,在有序列表中不必这么做。一旦节点中的值比正在查找的值更大,搜索就立刻结束并返回False。这是因为,要查找的元素不可能存在于链表后序的节点中。
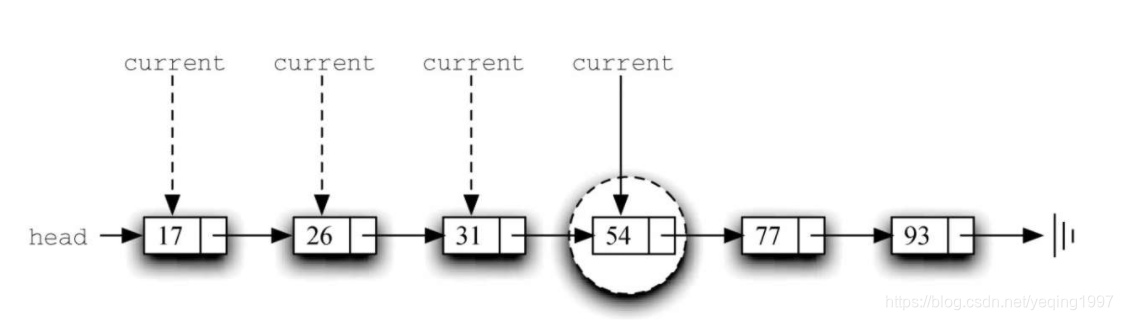
代码展示了完整的search方法。通过增加新的布尔型变量stop,并将其初始化为False(第4行),可以将上述条件轻松整合到代码中。当stop是False时,我们可以继续搜索链表(第5行)。如果遇到其值大于目标元素的节点,则将stop设为True(第9~10行)。之后的代码与无序列表中的一样。

需要修改最多的是add方法。对于无序列表,add方法可以简单地将一个节点放在列表的头部,这是最简便的访问点。不巧,这种做法不适合有序列表。我们需要在已有链表中为新节点找到正确的插入位置。假设要向有序列表17, 26, 54, 77, 93中添加31。add方法必须确定新元素的位置在26和54之间。下图展示了我们期望的结果。像之前解释的一样,需要遍历链表来查找新元素的插入位置。当访问完所有节点(current是None)或者当前值大于要添加的元素时,就找到了插入位置。在本例中,遇到54使得遍历过程终止。
和无序列表一样,由于current无法提供对待修改节点的访问,因此使用额外的引用previous是十分必要的。代码展示了完整的add方法。第2~3行初始化两个外部引用,第9~10行保证previous一直跟在current后面。只要还有节点可以访问,并且当前节点的值不大于要插入的元素,判断条件就会允许循环继续执行。在循环停止时,就找到了新节点的插入位置。

一旦创建了新节点,唯一的问题就是它会被添加到链表的开头还是中间某个位置。previous== None(第13行)可以提供答案。
链表分析
在分析链表操作的时间复杂度时,考虑其是否需要遍历列表。
以有 n 个节点的链表为例,isEmpty方法的时间复杂度是O(1),这是因为它只需要执行一步操作,即检查head引用是否为None。
length方法则总是需要执行 n步操作,这是因为只有完全遍历整个列表才能知道究竟有多少个元素。因此,length方法的时间复杂度是O( )n。
向无序列表中添加元素是O(1),这是因为只是简单地将新节点放在链表的第一个位置。但是,有序列表的search、remove以及add都需要进行遍历操作。尽管它们平均都只需要遍历一半的节点,但是这些方法的时间复杂度都是O( )n。这是因为在最坏情况下,它们都需要遍历所有节点。