文章目录
redis是一个开源的高性能的基于键值对的缓存存储系统,通过提供多种键值数据类型,来针对业务需求。 redis是一家意大利的公司,因为之前要做一款网站的实时统计,放在mysql中性能太差,继而开源。
redis的优势
存储结构
1.字符类型
2.散列类型
3.列表类型
4.集合类型
5.有序集合
功能
- 可以为每个key设置超时时间;
- 可以通过列表类型来实现分布式队列的操作。
- 支持发布订阅的消息模式(类似消息中间件)
简单
1.提供了很多命令与redis进行交互
redis的应用场景
1.数据缓存(商品数据、新闻、热点数据)
2.单点登录
3.秒杀、抢购
4.网站访问排名
5.应用的模块开发
6.粉丝关注,可能认识的人
redis的安装
Redis是c语言开发的。
安装redis需要c语言的编译环境。如果没有gcc需要在线安装。yum install gcc-c++
- 下载redis安装包
- tar -zxvf 安装包
- 在redis目录下执行make进行编译
- 没有报错执行make test进行测试,报错则说明缺少了相应的三方依赖
- make install 去完成安装 PREFIX=/usr/local/redis
后台启动
设置后台启动 copy redis.conf文件移动到我们的目录 编辑文件redis.conf,
daemonize yes 进行保存
启动/停止redis
启动的时候 指定我们的配置文件 ./redis-server ./redis.conf
停止redis ./redis-cli shutdown
连接redis的命令
./reids-cli
远程连接
./redis-cli -h 127.0.0.1 -p 6379
其他命令说明
redis-server 启动服务
redis-cli 访问到redis的控制台
redis-benchmark 性能测试的工具
redis-check-aof aof文件进行检测的工具
redis-check-dump rdb文件检查工具
redis-sentinel sentinel服务器配置 哨兵
多数据库支持
默认支持16个数据库,可以理解为一个命名空间
redis.conf里的databases进行配置,默认连接的是索引为0的数据库。 可进行select dbid 命令进行切换数据库 select 0;每个数据库里面可以存在相同的key
跟关系型数据库不一样的点
- redis不支持自定义数据库名词
- 每个数据库不能单独设置权限
- 每个数据库之间并不是完全隔离的,可以通过flushall命令清空redis实例里所有数据库中的数据。
使用入门
全局简单操作
1.获得一个符合匹配规则的键名列表(name写清楚,如果数据很大,不写清楚会影响性能)
keys pattern [?(任意一个字符) *(任意多个字符) [] ]
查找 keys hobbies:fruit
2.判断一个键是否存在 exists key
3. type key 去获得这个key的数据结构类型
4. delete key 删除一个key
5. exists key 判断一个key是否存在
key的设计
对象类型:对象id:对象属性:对象子属性(不建议key的长度太长,数据量大内存消耗多)
建议对key进行分类,同步在wiki统一管理。
各种数据结构的使用
1.字符类型
一个字符类型的key默认存储的最大容量是512m
赋值和取值相关
GET key
SET key value [seconds] [millseconds]
原子递增数值类型
incr key incr age(不存在) 则为1
短信重发机制:sms:limit:mobile 188… expire
incrby age 5递增指定的整数
decr age 原子递减
decrby age 5
setnx 如果存在就不会执行返回0,如果不存在就赋值返回1 分布式锁
append key value 向指定的key追加字符串
strlen key 获得key长度
mget key1 key2…同时获得多个key的内容
mset key1 val1 key2 val2 … 同时设置多个key val
2.散列类型
散列类型
hash类型 不支持类型的嵌套(不允许hash里面有list等嵌套类型)
hset key field value
hget key field
hmset key field value [field value…]
hmget key field [field …]
hincrby
hsetnx
hdel key field [field…] 删除一个或者多个字段
业务场景:比较适合存储对象,复杂的优惠卷信息
3.列表类型
list 可以存储一个有序的字符串列表,可以向列表两端添加数据,内部采用双向链表来构造
添加数据
lpush (left push) key … 左边添加 rpush(right push) key … 右边添加
lpush/rpush number 7 . . . .
lpush/rpush number 6 . . . .
lpush/rpush number 5 . . .
5 6 7
弹出数据(删除+获得)
lpop/rpop: 获取数据
llen key 获得列表的长度
lrange key start stop 索引可以是负数 -1 表示是最反向边的第一个元素
lrem key count value 从左往右从key删除count个value
lset key index val 从左往右设置key在index位置为val
应用场景:可以结合使用 实现分布式队列。
4.集合类型
set跟list不一样的点。集合类型不能存储重复的数据,而且是无序的。
sadd key number number… 增加数据; 如果value已经存在,则会忽略存在的值,并且返回成功加入的元素的数量
srem key number number … 删除元素
smembers key 获取所有数据
sdiff key key … 对多个集合执行差集运算,和key的顺序有关系key1 - key2
sunion key key … 对多个集合执行并集操作,同时存在两个集合里的所有值。
业务场景:可能认识的人
5.有序集合
zadd key score member [score member] 有序集合添加数据
zadd topNews 50 xixi 60 haha 10 hehe (升序)
zrange key start stop [withscores] 去获得元素。 withscores是可以获得元素的分数
zrange topNews 0 -1 withscores
如果两个元素的score是相同的话,那么根据(0<9<A<Z<a<z)方式从小到大
业务场景:热搜
以前只是类型命令冰山一角
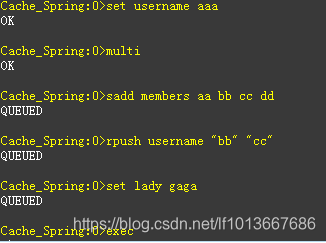
redis的事务处理
MULTI 去开启事务
一个个的命令加入队列
set userinfo:name spring
set userinfo:age 27
exec 去执行
有种情况是没办法回滚的,执行过程中才会报错的命令。
在加入队列过程中语句没有报错(不是语法错误),事务提交将不能回滚
错误的对键username 使用了列表键命令

过期时间
expire key seconds 设置过期时间
ttl key 获得当前key的时间 永久存在为-1
发布订阅
publish channel message
subscribe channel […]
subscribe queue1
publish queue1 hello
外网访问
redis是不允许外网访问的,一旦外网访问,别人可以直接通过端口来访问数据。
通过bind来设置,来解除限制为了,安全可以增加密码改变端口操作放置被它人挖矿消耗CPU。
vim redis.conf
#bind 127.0.0.1给注释掉
protected -mode no 默认是受保护模式,改为no
这样就可以通过外网访问了。
redis实现分布式锁
分布式架构来说,每个进程的同步锁是没有办法保证其他进程去访问某个资源的独占性,需要在分布式环境中引入分布式锁。
数据库可以做,activeMQ,缓存都能做
缓存-redis setnx
场景:全局id
秒杀
防止缓存击穿导致的问题
缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
解决方案:
接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
解决方案:
设置热点数据永远不过期。
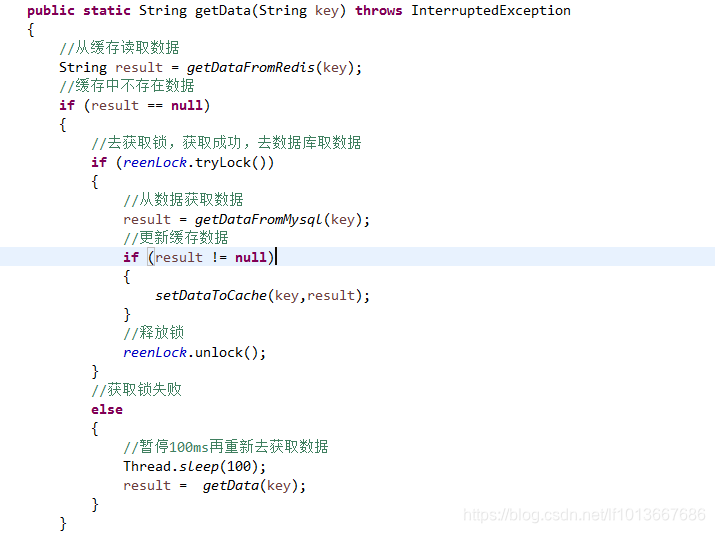
加互斥锁
说明:
1)缓存中有数据,直接走上述代码13行后就返回结果了
2)缓存中没有数据,第1个进入的线程,获取锁并从数据库去取数据,没释放锁之前,其他并行进入的线程会等待100ms,再重新去缓存取数据。这样就防止都去数据库重复取数据,重复往缓存中更新数据情况出现。
3)当然这是简化处理,理论上如果能根据key值加锁就更好了,就是线程A从数据库取key1的数据并不妨碍线程B取key2的数据,上面代码明显做不到这点。
缓存雪崩
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是, 缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
如果缓存数据库是分布式部署,将热点数据均匀分布在不同缓存数据库中。
设置热点数据永远不过期。
分布式锁请移步到下一篇