一 、Hash
1.1 介绍
Redis中的字典采用哈希表作为底层实现,一个哈希表有多个节点,每个节点保存一个键值对。
在Redis源码文件中,字典的实现代码在dict.c和dict.h文件中。
Redis的数据库就是使用字典作为底层实现的,通过key和value的键值对形式,代表了数据库中全部数据。而且,所有对数据库的增、删、查、改的命令,都是建立在对字典的操作上。
同时,字典还是Redis中哈希键的底层实现,当一个哈希键包含的键值对比较多,或者键值对中的元素都是比较长的字符串时,Redis就会使用字典作为哈希键的底层实现。
当 hash 移除了最后一个元素之后,该数据结构自动被删除,内存被回收。
字典又称为符号表(symbol table)、关联数组(associative array)或映射(map),是一种用于保存键值对(key-value pair)的抽象数据结构。
1.2 命令的用法
- hset(key, field, value):向名称为key的hash中添加元素field<—>value
- hget(key, field):返回名称为key的hash中field对应的value
- hmget(key, field1, …,field N):返回名称为key的hash中field i对应的value
- hmset(key, field1, value1,…,field N, value N):向名称为key的hash中添加元素field i<—>value i
- hincrby(key, field, integer):将名称为key的hash中field的value增加integer
- hexists(key, field):名称为key的hash中是否存在键为field的域
- hdel(key, field):删除名称为key的hash中键为field的域
- hlen(key):返回名称为key的hash中元素个数
- hkeys(key):返回名称为key的hash中所有键
- hvals(key):返回名称为key的hash中所有键对应的value
- hgetall(key):返回名称为key的hash中所有的键(field)及其对应的value
1.3 源码分析
hash 结构的数据主要用到的是字典结构。
其实除了hash会使用到字典,整个 Redis 数据库的所有 key 和 value 也组成了一个全局字典,还有带过期时间的 key 集合也是一个字典。
//该结构体在server.h中定义
typedef struct redisDb {
dict *dict; /*整个数据库的字典 The keyspace for this DB */
dict *expires; /*有过期时间的字典 Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
} redisDb;zset 集合中存储 value 和 score 值的映射关系也是通过 dict 结构实现的。
//该结构体在server.h中定义
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;Redis定义了dictEntry(哈希表结点),dictType(字典类型函数),dictht(哈希表)和dict(字典)四个结构体来实现字典结构,下面来分别介绍这四个结构体。
//哈希表的table指向的数组存放这dictEntry类型的地址。定义在dict.h/dictEntryt中
typedef struct dictEntry {//字典的节点
void *key;
union {//使用的联合体
void *val;
uint64_t u64;//这两个参数很有用
int64_t s64;
} v;
struct dictEntry *next;//指向下一个hash节点,用来解决hash键冲突(collision)
} dictEntry;
//dictType类型保存着 操作字典不同类型key和value的方法 的指针
typedef struct dictType {
unsigned int (*hashFunction)(const void *key); //计算hash值的函数
void *(*keyDup)(void *privdata, const void *key); //复制key的函数
void *(*valDup)(void *privdata, const void *obj); //复制value的函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2); //比较key的函数
void (*keyDestructor)(void *privdata, void *key); //销毁key的析构函数
void (*valDestructor)(void *privdata, void *obj); //销毁val的析构函数
} dictType;
//redis中哈希表定义dict.h/dictht
typedef struct dictht { //哈希表
dictEntry **table; //存放一个数组的地址,数组存放着哈希表节点dictEntry的地址。
unsigned long size; //哈希表table的大小,初始化大小为4
unsigned long sizemask; //用于将哈希值映射到table的位置索引。它的值总是等于(size-1)。
unsigned long used; //记录哈希表已有的节点(键值对)数量。
} dictht;
//字典结构定义在dict.h/dict
typedef struct dict {
dictType *type; //指向dictType结构,dictType结构中包含自定义的函数,这些函数使得key和value能够存储任何类型的数据。
void *privdata; //私有数据,保存着dictType结构中函数的参数。
dictht ht[2]; //两张哈希表。
long rehashidx; //rehash的标记,rehashidx==-1,表示没在进行rehash
int iterators; //正在迭代的迭代器数量
} dict;
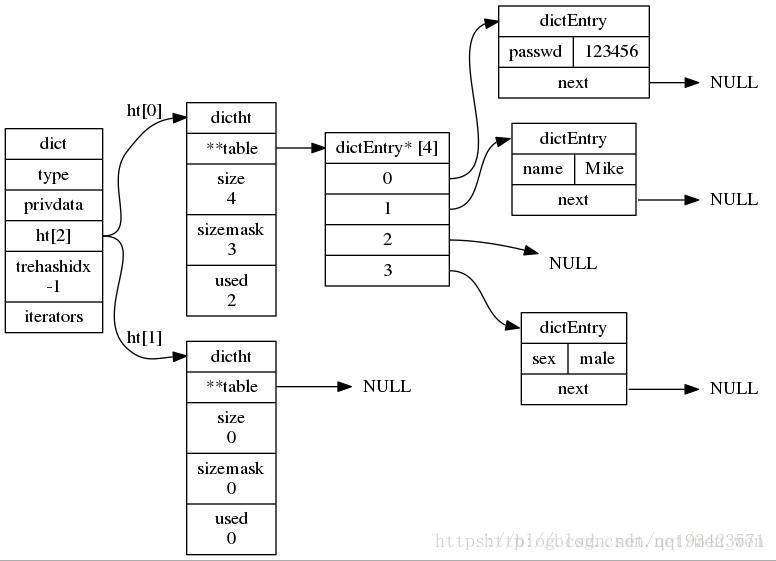
从源码中可以看出,dict 结构内部包含两个 hashtable,通常情况下只有一个 hashtable 是有值的。
但是在 dict 扩容缩容时,需要分配新的 hashtable,然后进行渐进式搬迁,这时候两个 hashtable 存储的分别是旧的 hashtable 和新的 hashtable。待搬迁结束后,旧的 hashtable 被删除,新的 hashtable 取而代之。
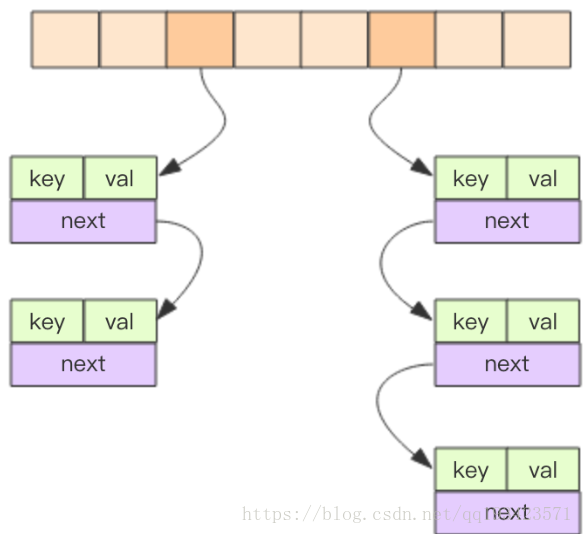
字典数据结构的精华就落在了dictht所表示的 hashtable 结构上了。hashtable 的结构和 Java 的 HashMap 几乎是一样的,都是通过分桶的方式解决 hash 冲突。第一维是数组,第二维是链表。数组中存储的是第二维链表的第一个元素的指针。
1.4 哈希算法
当往字典中添加键值对时,需要根据键的大小计算出哈希值和索引值,然后再根据索引值,将包含新键值对的哈希表节点放到哈希表数组的指定索引上面。
// 计算哈希值
h = dictHashKey(d, key);
// 调用哈希算法计算哈希值
#define dictHashKey(d, key) (d)->type->hashFunction(key)Redis提供了三种计算哈希值的函数,其分别是:
- Thomas Wang’s 32 bit Mix函数,对一个整数进行哈希,该方法在dictIntHashFunction中实现
unsigned int dictIntHashFunction(unsigned int key) //用于计算int整型哈希值的哈希函数
{
key += ~(key << 15);
key ^= (key >> 10);
key += (key << 3);
key ^= (key >> 6);
key += ~(key << 11);
key ^= (key >> 16);
return key;
}- 使用MurmurHash2哈希算法对字符串进行哈希,该方法在dictGenHashFunction中实现
unsigned int dictGenHashFunction(const void *key, int len) { //用于计算字符串的哈希值的哈希函数
/* 'm' and 'r' are mixing constants generated offline.
They're not really 'magic', they just happen to work well. */
//m和r这两个值用于计算哈希值,只是因为效果好。
uint32_t seed = dict_hash_function_seed;
const uint32_t m = 0x5bd1e995;
const int r = 24;
/* Initialize the hash to a 'random' value */
uint32_t h = seed ^ len; //初始化
/* Mix 4 bytes at a time into the hash */
const unsigned char *data = (const unsigned char *)key;
//将字符串key每四个一组看成uint32_t类型,进行运算的到h
while(len >= 4) {
uint32_t k = *(uint32_t*)data;
k *= m;
k ^= k >> r;
k *= m;
h *= m;
h ^= k;
data += 4;
len -= 4;
}
/* Handle the last few bytes of the input array */
switch(len) {
case 3: h ^= data[2] << 16;
case 2: h ^= data[1] << 8;
case 1: h ^= data[0]; h *= m;
};
/* Do a few final mixes of the hash to ensure the last few
* bytes are well-incorporated. */
h ^= h >> 13;
h *= m;
h ^= h >> 15;
return (unsigned int)h;
}- 使用基于djb哈希的一种简单的哈希算法,该方法在dictGenCaseHashFunction中实现。
unsigned int dictGenCaseHashFunction(const unsigned char *buf, int len) { //用于计算字符串的哈希值的哈希函数
unsigned int hash = (unsigned int)dict_hash_function_seed;
while (len--)
hash = ((hash << 5) + hash) + (tolower(*buf++)); /* hash * 33 + c */
return hash;
}计算出哈希值之后,需要计算其索引。Redis采用下列算式来计算索引值。
// 举例:h为5,哈希表的大小初始化为4,sizemask则为size-1,
// 于是h&sizemask = 2,
// 所以该键值对就存放在索引为2的位置
idx = h & d->ht[table].sizemask;1.4 rehash
当哈希表的大小不能满足需求,就可能会有两个或者以上数量的键被分配到了哈希表数组上的同一个索引上,于是就发生冲突(collision).
在Redis中解决冲突的办法是链接法(separate chaining)。但是需要尽可能避免冲突,希望哈希表的负载因子(load factor),维持在一个合理的范围之内,就需要对哈希表进行扩展或收缩。
扩容:当 hash 表中元素的个数等于第一维数组的长度时,就会开始扩容,扩容的新数组是原数组大小的 2 倍。不过如果 Redis 正在做 bgsave,为了减少内存页的过多分离 (Copy On Write),Redis 尽量不去扩容 (dict_can_resize),但是如果 hash 表已经非常满了,元素的个数已经达到了第一维数组长度的 5 倍 (dict_force_resize_ratio),说明 hash 表已经过于拥挤了,这个时候就会强制扩容。
缩容:当 hash 表因为元素的逐渐删除变得越来越稀疏时,,Redis 会对 hash 表进行缩容来减少 hash 表的第一维数组空间占用。缩容的条件是元素个数低于数组长度的 10%。缩容不会考虑 Redis 是否正在做 bgsave。
大字典的扩容是比较耗时间的,需要重新申请新的数组,然后将旧字典所有链表中的元素重新挂接到新的数组下面,这是一个O(n)级别的操作.
扩容操作具体源码:
static int _dictExpandIfNeeded(dict *d) //扩展d字典,并初始化
{
if (dictIsRehashing(d)) return DICT_OK; //正在进行rehash,直接返回
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE); //如果字典(的 0 号哈希表)为空,那么创建并返回初始化大小的 0 号哈希表
//1. 字典的总元素个数和字典的数组大小之间的比率接近 1:1
//2. 能够扩展的标志为真
//3. 已使用节点数和字典大小之间的比率超过 dict_force_resize_ratio
if (d->ht[0].used >= d->ht[0].size && (dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2); //扩展为节点个数的2倍
}
return DICT_OK;
}收缩操作具体源码:
int dictResize(dict *d) //缩小字典d
{
int minimal;
//如果dict_can_resize被设置成0,表示不能进行rehash,或正在进行rehash,返回出错标志DICT_ERR
if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;
minimal = d->ht[0].used; //获得已经有的节点数量作为最小限度minimal
if (minimal < DICT_HT_INITIAL_SIZE)//但是minimal不能小于最低值DICT_HT_INITIAL_SIZE(4)
minimal = DICT_HT_INITIAL_SIZE;
return dictExpand(d, minimal); //用minimal调整字典d的大小
}扩展和收缩操作都调用了dictExpand()函数,该函数通过计算传入的第二个大小参数进行计算,算出一个最接近2n的realsize,然后进行扩展或收缩,dictExpand()函数源码如下:
int dictExpand(dict *d, unsigned long size) //根据size调整或创建字典d的哈希表
{
dictht n;
unsigned long realsize = _dictNextPower(size); //获得一个最接近2^n的realsize
if (dictIsRehashing(d) || d->ht[0].used > size) //正在rehash或size不够大返回出错标志
return DICT_ERR;
if (realsize == d->ht[0].size) return DICT_ERR; //如果新的realsize和原本的size一样则返回出错标志
/* Allocate the new hash table and initialize all pointers to NULL */
//初始化新的哈希表的成员
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
if (d->ht[0].table == NULL) { //如果ht[0]哈希表为空,则将新的哈希表n设置为ht[0]
d->ht[0] = n;
return DICT_OK;
}
d->ht[1] = n; //如果ht[0]非空,则需要rehash
d->rehashidx = 0; //设置rehash标志位为0,开始渐进式rehash(incremental rehashing)
return DICT_OK;
}收缩或者扩展哈希表需要将ht[0]表中的所有键全部rehash到ht[1]中,但是rehash操作不是一次性、集中式完成的,而是分多次,渐进式,断续进行的,这样才不会对服务器性能造成影响。
1.5 渐进式rehash(incremental rehashing)
渐进式rehash的关键:
- 字典结构dict中的一个成员rehashidx,当rehashidx为-1时表示不进行rehash,当rehashidx值为0时,表示开始进行rehash。
- 在rehash期间,每次对字典的添加、删除、查找、或更新操作时,都会判断是否正在进行rehash操作,如果是,则顺带进行单步rehash,并将rehashidx+1。
- 当rehash时进行完成时,将rehashidx置为-1,表示完成rehash。
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing) {
long index;
dictEntry *entry;
dictht *ht;
// 这里进行小步搬迁
if (dictIsRehashing(d)) _dictRehashStep(d);
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1) return NULL; // 如果字典处于搬迁过程中,要将新的元素挂接到新的数组下面
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
dictSetKey(d, entry, key);
return entry;
}搬迁操作埋伏在当前字典的后续指令中(来自客户端的hset/hdel指令等),但是有可能客户端闲下来了,没有了后续指令来触发这个搬迁,那么Redis还会在定时任务中对字典进行主动搬迁。
// 服务器定时任务
void databaseCron() {
...
if (server.activerehashing) {
for (j = 0; j < dbs_per_call; j++) {
int work_done = incrementallyRehash(rehash_db);
if (work_done) {
break;
} else {
rehash_db++;
rehash_db %= server.dbnum;
}
}
}
}static void _dictRehashStep(dict *d) { //单步rehash
if (d->iterators == 0) dictRehash(d,1); //当迭代器数量不为0,才能进行1步rehash
}
int dictRehash(dict *d, int n) { //n步进行rehash
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0; //只有rehashidx不等于-1时,才表示正在进行rehash,否则返回0
while(n-- && d->ht[0].used != 0) { //分n步,而且ht[0]上还有没有移动的节点
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
//确保rehashidx没有越界,因为rehashidx是从-1开始,0表示已经移动1个节点,它总是小于hash表的size的
assert(d->ht[0].size > (unsigned long)d->rehashidx);
//第一个循环用来更新 rehashidx 的值,因为有些桶为空,所以 rehashidx并非每次都比原来前进一个位置,而是有可能前进几个位置,但最多不超过 10。
//将rehashidx移动到ht[0]有节点的下标,也就是table[d->rehashidx]非空
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx]; //ht[0]下标为rehashidx有节点,得到该节点的地址
/* Move all the keys in this bucket from the old to the new hash HT */
//第二个循环用来将ht[0]表中每次找到的非空桶中的链表(或者就是单个节点)拷贝到ht[1]中
while(de) {
unsigned int h;
nextde = de->next; //备份下一个节点的地址
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask; //获得计算哈希值并得到哈希表中的下标h
//将该节点插入到下标为h的位置
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
//更新两个表节点数目计数器
d->ht[0].used--;
d->ht[1].used++;
//将de指向以一个处理的节点
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL; //迁移过后将该下标的指针置为空
d->rehashidx++; //更新rehashidx
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) { //ht[0]上已经没有节点了,说明已经迁移完成
zfree(d->ht[0].table); //释放hash表内存
d->ht[0] = d->ht[1]; //将迁移过的1号哈希表设置为0号哈希表
_dictReset(&d->ht[1]); //重置ht[1]哈希表
d->rehashidx = -1; //rehash标志关闭
return 0; //表示前已完成
}
/* More to rehash... */
return 1; //表示还有节点等待迁移
}1.6 hash总结
- 结构:一个字典对象代表了一个dict的实例,一个dict中包含了两个dictht组成的哈希表素组和一个指向dicType的指针。定义两个dictht的作用主要是为了扩容过程中,能够保证读取数据的一致性,dicType中定于了一系列的函数指针。每个dictht中,存在一个dicEntry变量,可以看做是字典数组,也就是俗称中的bucket桶,存放数据的主要容器。每个dictEntry中,除了包括key和value的键值对以外,还包括指向下一个dictEntry对象的指针。
- 哈希算法:redis主要提供了三种Hash算法
- rehash:rehash发生在扩容或缩容阶段,扩容是发生在元素的个数等于哈希表数组的长度时,进行2倍的扩容;缩容发生在当元素个数为数组长度的10%时,进行缩容。
- 渐进式rehash:
二 、set
2.1 介绍
Redis 的set集合类似于 Java 语言里面的 HashSet,它内部的键值对是无序的唯一的。它的内部实现相当于一个特殊的字典,字典中所有的 value 都是一个值NULL。
当集合中最后一个元素移除之后,数据结构自动删除,内存被回收。
set结构是字典的衍生结构,而且它具有去重的功能,能够保证每个key只出现一次。
2.2 使用
- sadd(key, member):向名称为key的set中添 加元素member
- srem(key, member) :删除名称为key的set中的元素member
- spop(key) :随机返回并删除名称为key的set中一个元素
- smove(srckey, dstkey, member) :将member元素从名称为srckey的集合移到名称为dstkey的集合
- scard(key) :返回名称为key的set的基数
sismember(key, member) :测试member是否是名称为key的set的元素 - sinter(key1, key2,…key N) :求交集
- sinterstore(dstkey, key1, key2,…key N) :求交集并将交集保存到dstkey的集合
- sunion(key1, key2,…key N) :求并集
- sunionstore(dstkey, key1, key2,…key N) :求并集并将并集保存到dstkey的集合
- sdiff(key1, key2,…key N) :求差集
- sdiffstore(dstkey, key1, key2,…key N) :求差集并将差集保存到dstkey的集合
- smembers(key) :返回名称为key的set的所有元素
- srandmember(key) :随机返回名称为key的set的一个元素
hash和set的基本介绍就到此就告一段落了。