NOSQL & SQL
区别:
1.
2.
String 的应用场景
重点:
- 热点数据的缓存
- 分布式session:在跨域名 跨服务时候 需要一个中间的服务实现session的共享
<!--spring session 与redis应用基本环境配置,需要开启redis后才可以使用,不然启动Spring boot会报错 -->
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
- set NX EX 分布式锁:SET key value [EX seconds] [PX milliseconds] [NX|XX]
NX :只在键不存在时,才对键进行设置操作。 SET key value NX 效果等同于 SETNX key value
XX :只在键已经存在时,才对键进行设置操作
使用分布式锁:SETNX key value EX max-lock-time 设置过期时间 防止死锁
另外:
a.不使用固定的字符串作为键的值,而是设置一个不可猜测(non-guessable)的长随机字符串,作为口令串(token)
b.不使用 DEL 命令来释放锁,而是发送一个 Lua 脚本,这个脚本只在客户端传入的值和键的口令串相匹配时,才对键进行删除
SET-REDIS命令参考- incr 全局ID:原子性操作
- incr 计数器:页面的访问次数
- incr 限流:高并发时候限制某个IP在一分钟内只能访问N次,IP 1min 6 times
- 位操作 统计:非常节省空间的一种存储方式 存储用户最后的活跃时间,另外的逻辑与非等操作
存表?HASH
思考: 怎么去存储?
首先很容易想到的是 序列化变成json字符串存储 但是这样增加序列化和反序列化的成本
比如:我们需要对某个字段进行修改 只能从Redis里面取出来 然后反序列化 进行修改 很麻烦 有没有其他的方式呢?
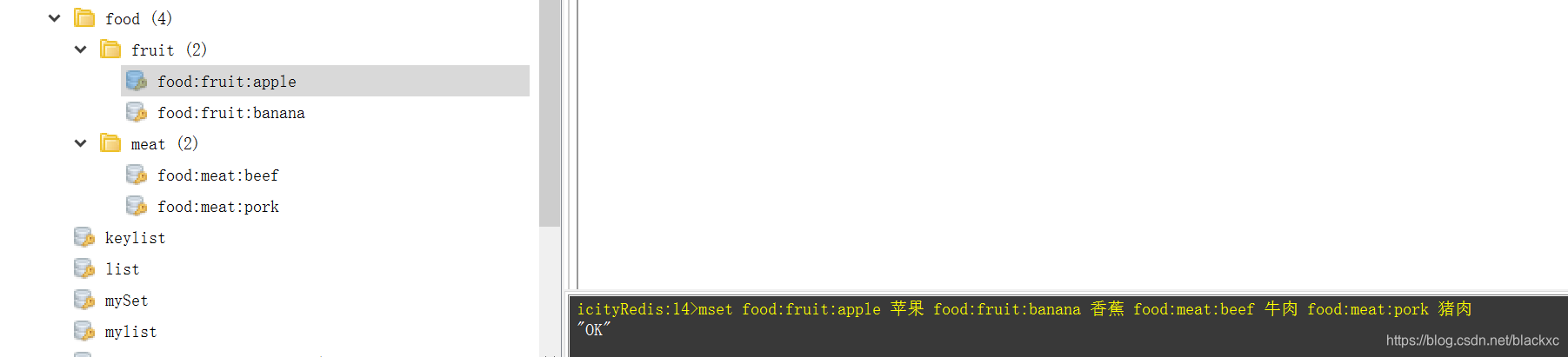
在Redis里面可以使用冒号:对key进行分层 例如:
MSET food:fruit:apple 苹果 food:fruit:banana 香蕉 food:meat:beef 牛肉 food:meat:pork 猪肉
可以使用通配符的方式 查keyicityRedis:14>keys food:meat:*
“food:meat:pork”
“food:meat:beef”
存表的话:mset table_name: id:column1_name value table_name: id:column2_name value…
不推荐这样存储方式 有没有另外一种方式?
HASH 哈希
思考:同样是存储字符串 hash和String直接存储有啥区别?
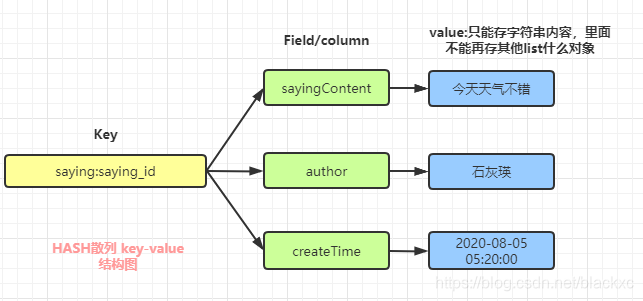
- 节省空间:把一行的所有字段 聚集到一个key里面
- 减少KEY的冲突:减少key命名冲突?
- 减少资源消耗:只需一个key取出一整行的数据
都是取决于 HASH散列的结构 一个key 对应 多个字段的value那说了这么多 HASH散列 有什么缺点吗?
- String里面 每个key可以设置过期时间 但是hash里面只能对整个进行过期时间设置
- hash里面没有对位的操作
- 如果每个column的value很大 使用不了Redis的cluster
总结就是 hash是一整行 一坨 不利于对每个字段key进行操作hash的基本命令
icityRedis:14>hmset icity.mamba.key name songlijun age 23 sex 0
“OK”
icityRedis:14>hmget icity.mamba.key name age sex
“shihuiying”
“23”
“0”
String能干的HASH也能干 有哪些应用场景呢?
String单个 HASH是一坨;购物车?key:用户id field:商品id value:商品数量 name:商品名称…
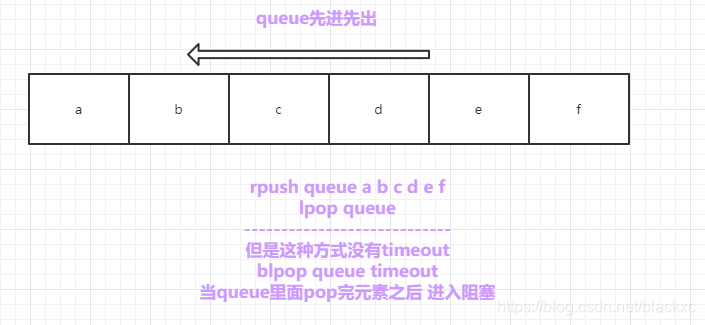
List
有序,左边是列表头,右边是列表尾,顺序从左到右
可以用来做队列queue 实现一个简单的消息队列FIFO
rpush and lpop命令实现
Set
基本操作命令:
sadd myset a d c d e f
smembers myset: 列出所有value
scard myset : value的数量
sismember myset c:返回0/1 是否存在
srem myset c:删除value
集合之间的操作:
差集:adiff set1 set2
交集:sinter
并集:sunion
Zset 有序set
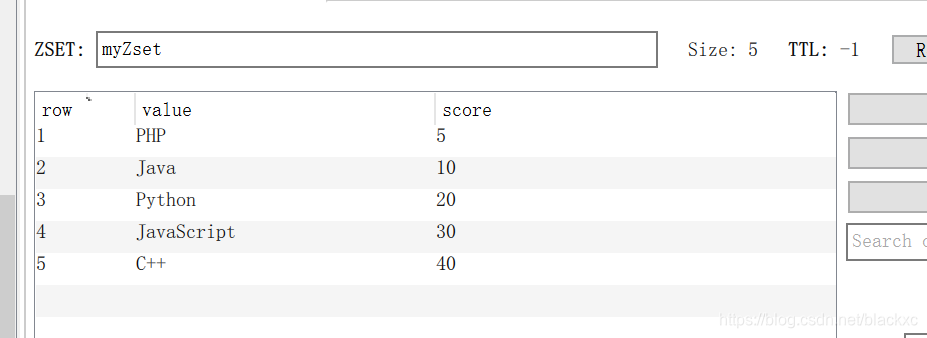
zadd setName 10 Java 20 Python …
zrange setName 0 -1 withscores
实际应用:排行榜 搜索热点
zincrby hotNews:20200806 1 newsId: newsId点击数加一
zrevrange hotNews:20200806 0 19 withscores:获取今天点击数自多的20条 并倒序从高到底
Geo Spatial
存储地理信息
geoadd myCity 121.48 31.22 shanghai 114.30 30.59 wuhan
geopos myCity wuhan: “114.30000096559524536” “30.58999969007286523”
geodist myCity shanghai wuhan km: 距离"688.6677"
georadius myCity Longitude latitude 5 km:基于某个经纬度从myCity里面找出范围内的地点
georadiusbymember myCity wuhan 10 km: 找出wuhan10km以内的所有的元素
Hyperloglogs
基于基数 计数的:可以用很少的内存计算很大基数元素
可以用来统计UV user view 在数据量很大 但是不需要很精确的时候