本次文章内容是爬取贴吧图片,希望对大家有所帮助
使用环境:我用的是python2.7.9
在Python 3以后的版本中,urllib2这个模块已经不单独存在(也就是说当你import urllib2时,系统提示你没这个模块),urllib2被合并到了urllib中。
- urllib2.urlopen()变成了urllib.request.urlopen()
- urllib2.Request()变成了urllib.request.Request()
如果有的用的是python3以后的版本,记得改一下哦
一、 获取要爬取的贴吧的网址
打开浏览器,找到我们想爬取的贴吧,获取其网址

二、 获取页面源代码
利用下面函数来获取源代码
def gethtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
三、匹配的图片地址
首先,我们打开第一步的网址,右击审查元素,在审查元素中找到图片的地址,观察其地址的格式
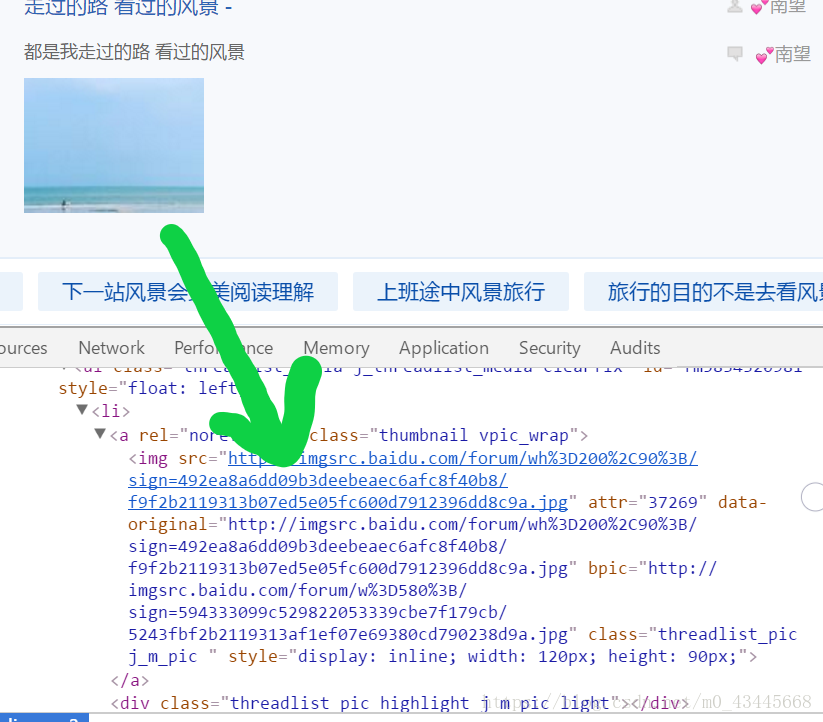
这里,我匹配的是bpic等于的那个网址,从这我们可以看到图片的地址是以.jpg结尾,利用正则进行匹配
reg = r'bpic="(.*?\.jpg).*?pic'
这里括号所括住的部分,正是我们所需要的地址
- (.*?)是进行最小匹配,是非贪婪模式
- \ 是转义字符
四、保存图片至本地
存入本地
urllib.urlretrieve(imgurl, '%s.jpg' % x)
或者可以存至自己新建的文件夹
f = open('tupian/'+str(x)+'.jpg', 'wb')
f.write((urllib2.urlopen(imgurl)).read())
f.close()
五、完整代码呈现
代码中有中文时,完整添加的是 # - * - coding:utf-8 - * -
#coding:utf8只是简写
此程序中,共用到三个库:
- import re
- import urllib
- import urllib2
#代码中有中文时,需加#coding:utf8
# coding:utf8
#导入需要的模块,这里需要re模块匹配正则,urllib模块获取网页源码,urllib2模块将获取的图片存入文件夹中
import re
import urllib
import urllib2
#获取网页源代码的函数
def gethtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
#获取图片的函数
def getimg(html):
#利用正则获取图片的网址
reg = r'bpic="(.*?\.jpg).*?pic'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
#此变量x用于下载图片时为图片命名
x=0
for imgurl in imglist:
#这个print可以用于检验匹配出的图片地址
print imgurl
#第一种:下载图片,保存到本地
#urllib.urlretrieve(imgurl, '%s.jpg' % x)
#第二种:将下载好的文件存入一个文件夹中.(wb存入时会删除此文件夹原有的图片)
f = open('tupian/'+str(x)+'.jpg', 'wb')
f.write((urllib2.urlopen(imgurl)).read())
f.close()
x+=1
html = gethtml("http://tieba.baidu.com/f?ie=utf-8&kw=风景")
getimg(html)
结果呈现
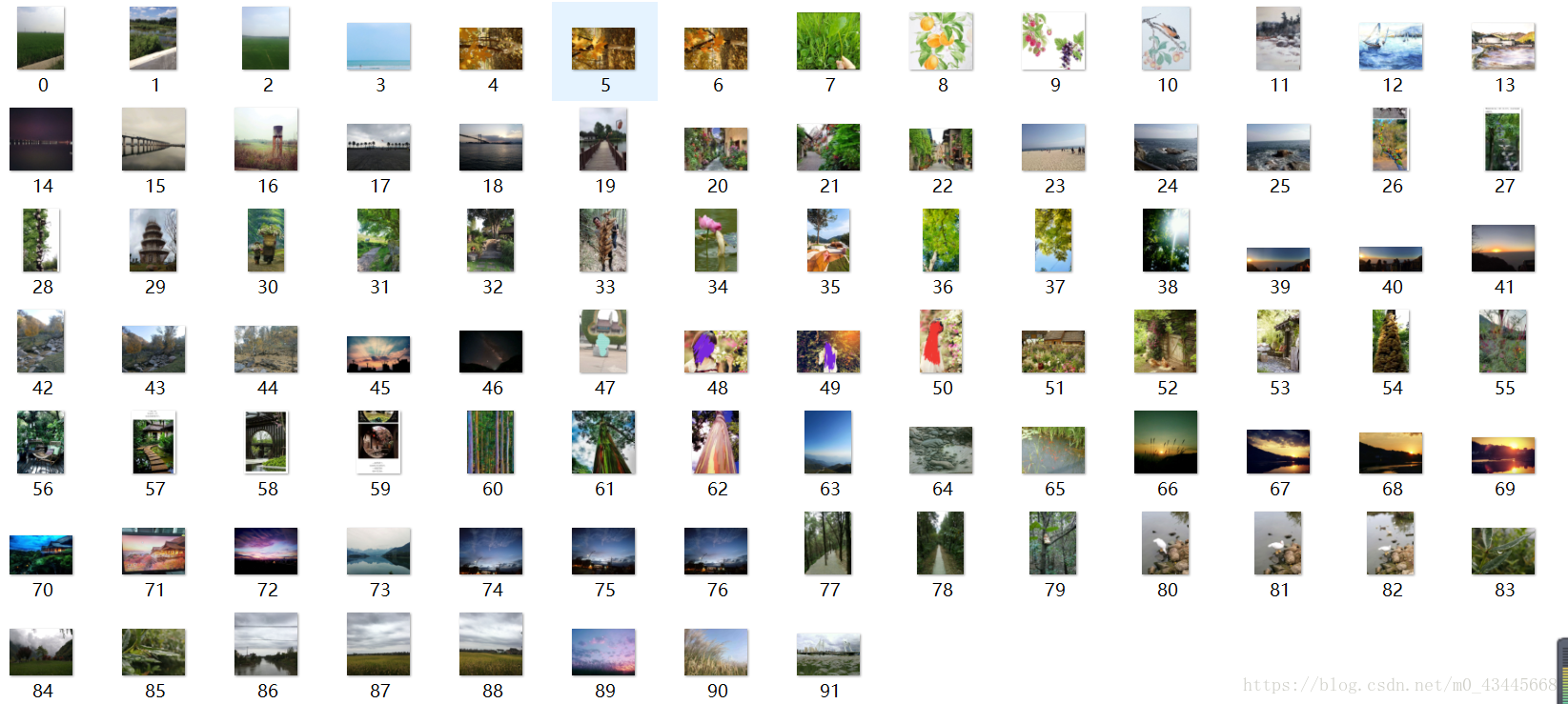
以上就是爬取贴吧图片的全部过程