00
上篇爬取了前程无忧网站相关的招聘信息,本篇继续爬取百度百聘的动态招聘信息,同样保存到Mysql数据库。
百度百聘是动态页面,其分页通过JS实现,如下图:
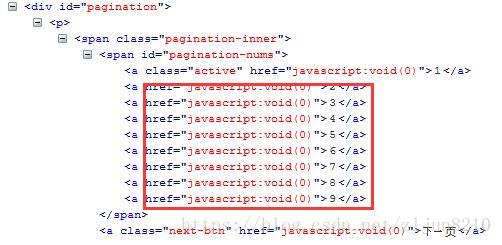
01 实现过程
创建项目、设置Settings、Piplines等,与上篇相同。
1. Spider实现
网上针对此类页面,解决方案有借助Selenium操作实现的,研究实验了一番,发现无法翻页,其Request的Url都是相同的。
后在Chrome浏览器上点击 多页 查看,发现在Network下,不同的页面,XHR下会有不同的请求URL,通过分析,得出规律,得以实现(注意:XHR请求的URL,是API实现的,页面请求需要改部分URL,"api/quanzhiasync?" 改为 “quanzhi?tid=4139&ie=utf8&oe=utf8&”)
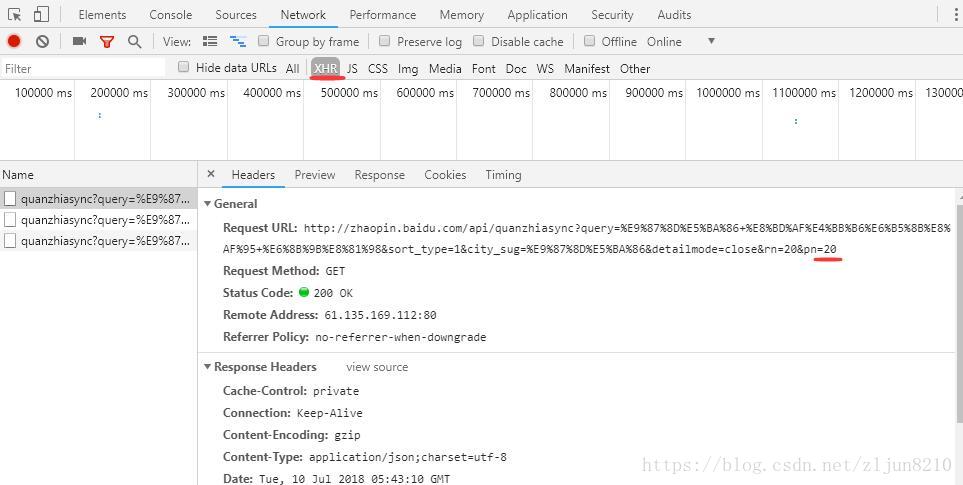
2. 代码:
# -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver
from scrapy.http import Request
from baiduRecruit.items import BaidurecruitItem
from scrapy.selector import Selector
class RecruitsumSpider(scrapy.Spider):
name = 'recruitSum'
global pn
start_urls = [
'http://zhaopin.baidu.com/quanzhi?tid=4139&ie=utf8&oe=utf8&query=%E9%87%8D%E5%BA%86+%E8%BD%AF%E4%BB%B6%E6%B5%8B'
'%E8%AF%95+%E6%8B%9B%E8%81%98&city_sug=%E9%87%8D%E5%BA%86']
def parse(self, response):
baseurl = "http://zhaopin.baidu.com/quanzhi?tid=4139&ie=utf8&oe=utf8&query=%E9%87%8D%E5%BA%86+%E8%BD%AF%E4%BB" \
"%B6%E6%B5%8B%E8%AF%95+%E6%8B%9B%E8%81%98&sort_type=1&city_sug=%E9%87%8D%E5%BA%86"
global pn
pn = 0
yield Request(baseurl + "&detailmode=close&rn=20&pn=0", callback=self.parseContent, method="GET")
def parseContent(self, response):
baseurl = "http://zhaopin.baidu.com/quanzhi?tid=4139&ie=utf8&oe=utf8&query=%E9%87%8D%E5%BA%86+%E8%BD%AF%E4%BB" \
"%B6%E6%B5%8B%E8%AF%95+%E6%8B%9B%E8%81%98&sort_type=1&city_sug=%E9%87%8D%E5%BA%86"
global pn
item = BaidurecruitItem()
contents = response.xpath('//div[@id="feed-list"]//a').extract()
# print(" \n Contents : \n %s" % contents)
for content in contents:
# print("\n Content : \n %s" % content)
content = Selector(text=content) # 强制转换Content内容
titles = content.xpath('//div[@class="left content-left"]/div/span/text()').extract()[0]
print(" tites: %s" % titles)
ld = content.xpath('//p[@class="area line-clamp1"]/text()').extract()[0]
local = ld.split('|')[0] # 分割字符串,并取第一部分
print("\n Location is : %s" % local)
compan = ld.split('|')[1] # 分割字符串,并取第二部分
print("\n Company is: %s" % compan)
xs = content.xpath('//p[@class="salary"]/text()').extract()[0]
df = content.xpath("//div[@class='right time']/p[2]/text()").extract()[0]
print("\n Salary is: %s" % xs)
dat = df.split('|')[0]
fro = df.split('|')[1]
print("\n Date is: %s" % dat)
print("\n Data Source is: %s" % fro)
item['title'] = titles
item['location'] = local
item['company'] = compan
item['salary'] = xs
item['date'] = dat
item['datasource'] = fro
yield item
result_num = response.xpath('//div[@class="result-num"]/b/text()').extract()[0]
result_num = int(result_num)
while pn < result_num:
pn = pn + 20
yield Request(baseurl + "&detailmode=close&rn=20&pn=" + str(pn), callback=self.parseContent)最后,爬取到的数据与页面上的相同。