scrapy无法使用xpath解析?特殊网页的信息提取(1) — 百度贴吧
1. 背景
- 最近在使用scrapy爬取百度贴吧帖子内容时,发现用xpath无法解析到页面元素。但是利用xpath helper这个插件,很明显可以看到xpath路径是没有问题的。
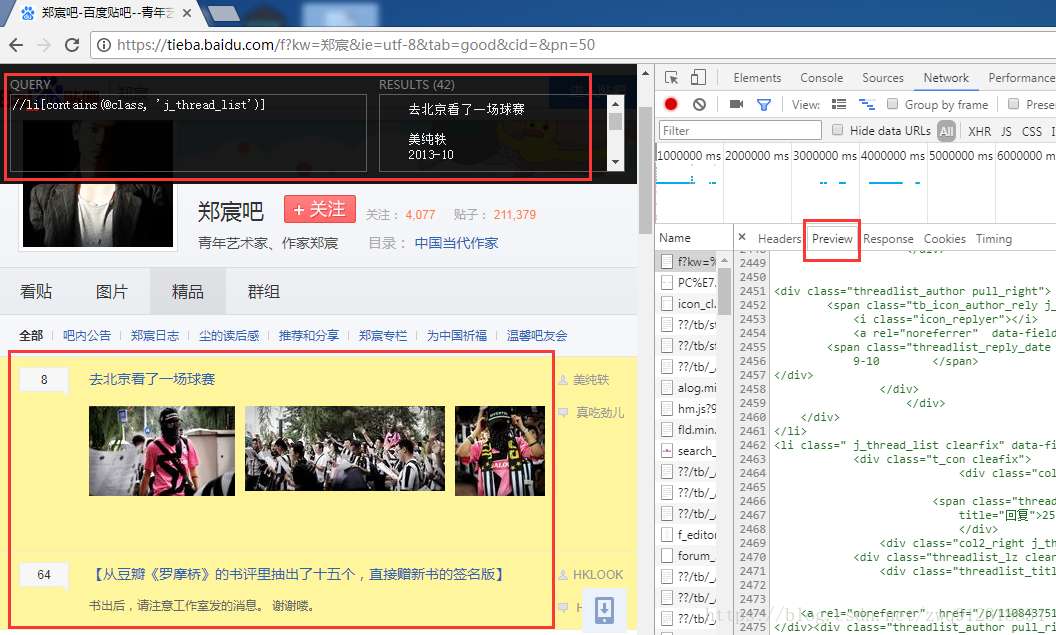
articleList = response.xpath("//li[contains(@class, 'j_thread_list')]")
print(f"articleList = {articleList}")
# 输出结果为:articleList = []- 之前的文章(https://blog.csdn.net/zwq912318834/article/details/78738362)也提到过审查元素看到的页面是渲染之后的页面,而scrapy真正抓下来的页面内容是在Preview这个栏位中。抱着好奇的想法,把这个内容打印了出来:
print(f"text = {response.text}")- 大致看了一下,发现页面内容和审查元素页面的内容基本上一致,不像是传统的页面框架+ js渲染模式,完全摸不着头脑到底是怎么回事,为什么xpath无法提取到相关的内容。
2. 环境
- python 3.6.1
- 系统:win7
- IDE:pycharm
- scrapy框架
3. 分析过程
- 试了很多次,各种重写xpath路径,还是不管用。然后我试着提取所有的div元素:
articleList = response.xpath("//div")
print(f"articleList = {articleList}")
# 输出结果为:articleList = [XXXXXX.........]- 发现,结果中提取出来的元素很少。但是能提取到元素,这也说明scrapy中的xpath是起作用的。问题应该是出在网页内容本身上,当时在想,原因可能有两个:
- 第一,xpath路径不对,网页内容有隐藏的陷阱,这在前篇文章中提到过一些。
- 第二,网页结构混乱,缺少一些标签,导致xpath无法识别。
- 仔细分析这个网页源码,终于被我发现了……要提取的这部分网页内容,显示的颜色是绿色的(字符串的颜色),而标签的颜色是紫色的。
- 最终发现,原来核心的网页内容是以字符串的形式,被包含在< code >这个标签中。非常非常的隐蔽!!!(我猜写这个页面的人一定是盗贼属性)
- 类似于这样子:
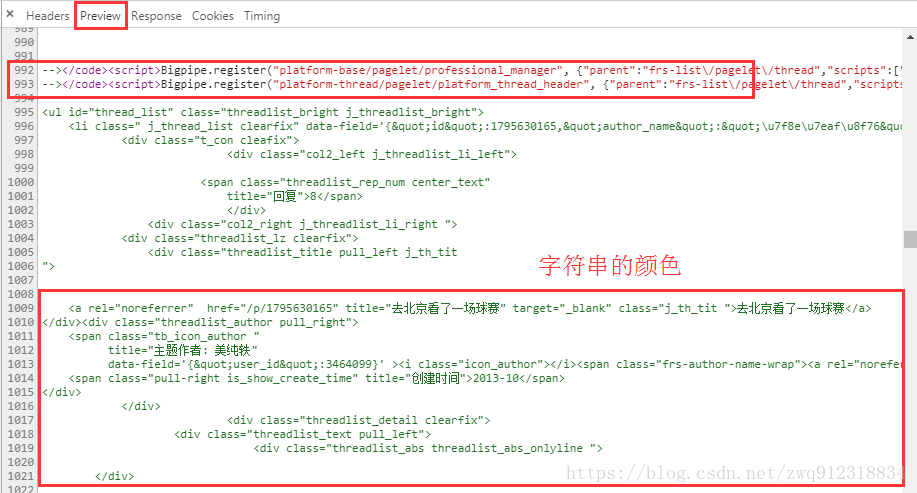

<code class="pagelet_html" id="pagelet_html_frs-list/pagelet/thread_list" style="display:none;">
<!--
<ul id="thread_list" class="threadlist_bright j_threadlist_bright">
<li class=" j_thread_list clearfix" data-field='{"id":1795630165,"author_name":"\u7f8e\u7eaf\u8f76","first_post_id":23158535830,"reply_num":8,"is_bakan":null,"vid":"","is_good":true,"is_top":null,"is_protal":null,"is_membertop":null,"is_multi_forum":null,"frs_tpoint":null}' >
<div class="t_con cleafix">
<div class="col2_left j_threadlist_li_left">
<span class="threadlist_rep_num center_text"
title="回复">8</span>
</div>
<div class="col2_right j_threadlist_li_right ">
<div class="threadlist_lz clearfix">
<div class="threadlist_title pull_left j_th_tit
">
<a rel="noreferrer" href="/p/1795630165" title="去北京看了一场球赛" target="_blank" class="j_th_tit ">去北京看了一场球赛</a>
</div><div class="threadlist_author pull_right">
<span class="tb_icon_author "
title="主题作者: 美纯轶"
data-field='{"user_id":3464099}' ><i class="icon_author"></i><span class="frs-author-name-wrap"><a rel="noreferrer" data-field='{"un":"\u7f8e\u7eaf\u8f76"}' class="frs-author-name j_user_card " href="/home/main/?un=%E7%BE%8E%E7%BA%AF%E8%BD%B6&ie=utf-8&fr=frs" target="_blank">美纯轶</a></span><span class="icon_wrap icon_wrap_theme1 frs_bright_icons "></span> </span>
<span class="pull-right is_show_create_time" title="创建时间">2013-10</span>
</div>
</div>
<div class="threadlist_detail clearfix">
<div class="threadlist_text pull_left">
<div class="threadlist_abs threadlist_abs_onlyline ">
</div>
<div class="small_wrap j_small_wrap">
<a rel="noreferrer" href="#" onclick="return false;" class="small_btn_pre j_small_pic_pre" style="display:none"></a>
<a rel="noreferrer" href="#" onclick="return false;" class="small_btn_next j_small_pic_next" style="display:none"></a>
<div class="small_list j_small_list cleafix">
<div class="small_list_gallery">
<ul class="threadlist_media j_threadlist_media clearfix" id="fm1795630165"><li><a rel="noreferrer" class="thumbnail vpic_wrap"><img src="" attr="83809" data-original="https://imgsa.baidu.com/forum/wh%3D200%2C90%3B/sign=ad7d4d7f277f9e2f7060150a2f00c51d/d31b0ef41bd5ad6ed1329b7381cb39dbb7fd3c5b.jpg" bpic="https://imgsa.baidu.com/forum/w%3D580%3B/sign=152e7697b13533faf5b6932698e8ff1f/d31b0ef41bd5ad6ed1329b7381cb39dbb7fd3c5b.jpg" class="threadlist_pic j_m_pic " /></a><div class="threadlist_pic_highlight j_m_pic_light"></div></li><li><a rel="noreferrer" class="thumbnail vpic_wrap"><img src="" attr="69505" data-original="https://imgsa.baidu.com/forum/wh%3D200%2C90%3B/sign=65f79006a40f4bfb8c859656337f54c9/b03533fa828ba61e4f2637b64134970a314e595b.jpg" bpic="https://imgsa.baidu.com/forum/w%3D580%3B/sign=62c02f74e71190ef01fb92d7fe209f16/b03533fa828ba61e4f2637b64134970a314e595b.jpg" class="threadlist_pic j_m_pic " /></a><div class="threadlist_pic_highlight j_m_pic_light"></div></li><li><a rel="noreferrer" class="thumbnail vpic_wrap"><img src="" attr="77005" data-original="https://imgsa.baidu.com/forum/wh%3D200%2C90%3B/sign=8cd55494f8dcd100cdc9f02342bb6b29/7aec54e736d12f2e0e2a50f94fc2d56285356878.jpg" bpic="https://imgsa.baidu.com/forum/w%3D580%3B/sign=a2dcfd7ad539b6004dce0fbfd96b342a/7aec54e736d12f2e0e2a50f94fc2d56285356878.jpg" class="threadlist_pic j_m_pic " /></a><div class="threadlist_pic_highlight j_m_pic_light"></div></li></ul>
</div>
</div>
</div> </div>
<div class="threadlist_author pull_right">
<span class="tb_icon_author_rely j_replyer" title="最后回复人: 真吃劲儿">
<i class="icon_replyer"></i>
<a rel="noreferrer" data-field='{"un":"\u771f\u5403\u52b2\u513f"}' class="frs-author-name j_user_card " href="/home/main/?un=%E7%9C%9F%E5%90%83%E5%8A%B2%E5%84%BF&ie=utf-8&fr=frs" target="_blank">真吃劲儿</a> </span>
<span class="threadlist_reply_date pull_right j_reply_data" title="最后回复时间">
10-5 </span>
</div>
</div>
</div>
</div>
</li>
<li class=" j_thread_list clearfix" data-field='{"id":1717449654,"author_name":"HKLOOK","first_post_id":21752844750,"reply_num":64,"is_bakan":null,"vid":"","is_good":true,"is_top":null,"is_protal":null,"is_membertop":null,"is_multi_forum":null,"frs_tpoint":null}' >
<div class="t_con cleafix">
<div class="col2_left j_threadlist_li_left">
<span class="threadlist_rep_num center_text"
title="回复">64</span>
</div>
<div class="col2_right j_threadlist_li_right ">
<div class="threadlist_lz clearfix">
<div class="threadlist_title pull_left j_th_tit ">
<a rel="noreferrer" href="/p/1717449654" title="【从豆瓣《罗摩桥》的书评里抽出了十五个,直接赠新书的签名版】" target="_blank" class="j_th_tit ">【从豆瓣《罗摩桥》的书评里抽出了十五个,直接赠新书的签名版】</a>
</div><div class="threadlist_author pull_right">
<span class="tb_icon_author "
title="主题作者: HKLOOK"
data-field='{"user_id":39475062}' ><i class="icon_author"></i><span class="frs-author-name-wrap"><a rel="noreferrer" data-field='{"un":"HKLOOK"}' class="frs-author-name j_user_card " href="/home/main/?un=HKLOOK&ie=utf-8&fr=frs" target="_blank">HKLOOK</a></span><span class="icon_wrap icon_wrap_theme1 frs_bright_icons "><a style="background: url(//tb1.bdstatic.com/tb/cms/com/icon/102_14.png?stamp=1522728608) no-repeat -800px 0;top:0px;left:0px" data-slot="1" data-name="shuangzi" data-field='{"name":"shuangzi","end_time":"1735660800","category_id":102,"slot_no":"1","title":"\u53cc\u5b50\u5ea7\u5370\u8bb0","intro":"\u83b7\u53d6\u89c4\u5219\uff1a\u5728\u661f\u5ea7\u52cb\u7ae0\u9986\u4e2d\u83b7\u5f97\u3002","intro_url":"https:\/\/tieba.baidu.com\/f?ie=utf-8&kw=%E8%9B%87%E5%A4%AB%E5%BA%A7&fr=search","price":0,"value":"1","sprite":{"1":"1522728608,16"}}' target="_blank" href="https://tieba.baidu.com/f?ie=utf-8&kw=%E8%9B%87%E5%A4%AB%E5%BA%A7&fr=search" class="j_icon_slot" title="双子座印记" locate="shuangzi_1#icon" style="top: 0px; left:0px"> <div class=" j_icon_slot_refresh"></div></a></span> </span>
<span class="pull-right is_show_create_time" title="创建时间">2014-01</span>
</div>
</div>
<div class="threadlist_detail clearfix">
<div class="threadlist_text pull_left">
<div class="threadlist_abs threadlist_abs_onlyline ">
书出后,请注意工作室发的消息。 谢谢喽。
</div>
</div>
<div class="threadlist_author pull_right">
<span class="tb_icon_author_rely j_replyer" title="最后回复人: HKLOOK">
<i class="icon_replyer"></i>
<a rel="noreferrer" data-field='{"un":"HKLOOK"}' class="frs-author-name j_user_card " href="/home/main/?un=HKLOOK&ie=utf-8&fr=frs" target="_blank">HKLOOK</a> </span>
<span class="threadlist_reply_date pull_right j_reply_data" title="最后回复时间">
11-30 </span>
</div>
</div>
</div>
</div>
</li>
</ul>
<div class="thread_list_bottom clearfix">
<div id="frs_list_pager" class="pagination-default clearfix"><a href="//tieba.baidu.com/f?kw=%E9%83%91%E5%AE%B8&ie=utf-8&tab=good&cid=0&pn=0" class="first pagination-item " >首页</a>
<a href="//tieba.baidu.com/f?kw=%E9%83%91%E5%AE%B8&ie=utf-8&tab=good&cid=0&pn=0" class="pre pagination-item " ><上一页</a>
<a href="//tieba.baidu.com/f?kw=%E9%83%91%E5%AE%B8&ie=utf-8&tab=good&cid=0&pn=0" class=" pagination-item " >1</a>
<span class="pagination-current pagination-item ">2</span>
<a href="//tieba.baidu.com/f?kw=%E9%83%91%E5%AE%B8&ie=utf-8&tab=good&cid=0&pn=100" class=" pagination-item " >3</a>
<a href="//tieba.baidu.com/f?kw=%E9%83%91%E5%AE%B8&ie=utf-8&tab=good&cid=0&pn=150" class=" pagination-item " >4</a>
<a href="//tieba.baidu.com/f?kw=%E9%83%91%E5%AE%B8&ie=utf-8&tab=good&cid=0&pn=200" class=" pagination-item " >5</a>
<a href="//tieba.baidu.com/f?kw=%E9%83%91%E5%AE%B8&ie=utf-8&tab=good&cid=0&pn=250" class=" pagination-item " >6</a>
<a href="//tieba.baidu.com/f?kw=%E9%83%91%E5%AE%B8&ie=utf-8&tab=good&cid=0&pn=300" class=" pagination-item " >7</a>
<a href="//tieba.baidu.com/f?kw=%E9%83%91%E5%AE%B8&ie=utf-8&tab=good&cid=0&pn=350" class=" pagination-item " >8</a>
<a href="//tieba.baidu.com/f?kw=%E9%83%91%E5%AE%B8&ie=utf-8&tab=good&cid=0&pn=400" class=" pagination-item " >9</a>
<a href="//tieba.baidu.com/f?kw=%E9%83%91%E5%AE%B8&ie=utf-8&tab=good&cid=0&pn=450" class=" pagination-item " >10</a>
<a href="//tieba.baidu.com/f?kw=%E9%83%91%E5%AE%B8&ie=utf-8&tab=good&cid=0&pn=100" class="next pagination-item " >下一页></a>
<a href="//tieba.baidu.com/f?kw=%E9%83%91%E5%AE%B8&ie=utf-8&tab=good&cid=0&pn=1800" class="last pagination-item " >尾页</a>
</div> <div class="th_footer_bright">
<div class="th_footer_l">
共有精品数<span class="red_text">1816</span>个
</div>
</div>
</div>
-->
</code>- 问题找到,那思路就清晰了……
- 第一步:先用正则表达式把这一段网页内容提取出来。
- 第二步:看要不要对这个网页内容做处理(比如有的网页会在冒号、斜杠等处加入\,这样的话需要去掉)
- 第三步:利用lxml模块的xpath对这个页面进行信息提取。
4. 代码解析
- 还有个问题需要注意,就是有个元素属性是json数据,需要用json模块做提取:
# 文件mySpider.py中
import lxml.html
import lxml.etree
import json
# 用于分析帖子列表页
def parseListPage(self, response):
print(f"parseListPage: statusCode = {response.status}, url = {response.url}")
# text = response.text
# 第一步:先用正则表达式把这一段网页内容提取出来
articleBodyRe = re.search('<code class="pagelet_html" id="pagelet_html_frs-list/pagelet/thread_list" style="display:none;"><!--(.*?)--></code>', response.text, re.DOTALL)
articleBody = ''
if articleBodyRe:
articleBody = articleBodyRe.group(1)
# 第二步:打印出来,看要不要对这个网页内容做处理
print(f"articleBody = {articleBody}")
# articleBody = articleBody.replace("\\", "")
# print(f"articleBody = \n{articleBody}")
# 利用lxml模块来提取页面元素,不过xpath的使用和scrapy内置的xpath的使用方法有所不同...需要注意
resultTree = lxml.etree.HTML(articleBody)
articleList = resultTree.xpath("//li[contains(@class, 'j_thread_list')]")
for articleElem in articleList:
articleInfo = {}
data_field = articleElem.xpath("@data-field")[0]
# 原始数据: data-field='{"id":1585419463,"author_name":"treves","first_post_id":19660780309,"reply_num":31,"is_bakan":null,"vid":"","is_good":true,"is_top":null,"is_protal":null,"is_membertop":null,"is_multi_forum":null,"frs_tpoint":null}'
dataFieldJson = json.loads(data_field)
# dataFieldJson = {'id': 1093442738, 'author_name': '晴空CHEN', 'first_post_id': 12488659000, 'reply_num': 16, 'is_bakan': None, 'vid': '', 'is_good': True, 'is_top': None, 'is_protal': None, 'is_membertop': None, 'is_multi_forum': None, 'frs_tpoint': None}
# print(f"dataFieldJson = {dataFieldJson}")
articleInfo['id'] = dataFieldJson['id']
articleInfo['author'] = dataFieldJson['author_name']
# 这是lxml模块中xpath的使用方式
articleInfo['title'] = articleElem.xpath(".//div[@class='t_con cleafix']//a/@title")[0]
# 提取到的数据是:/p/1795630165
articleInfo['href'] = articleElem.xpath(".//div[@class='t_con cleafix']//a/@href")[0]
print(f"articleInfo = {articleInfo}")
# 提取到的文章链接是:/p/1795630165, 而且目前我只抓“只看楼主”的内容,所以用到response.follow
yield response.follow(
url = articleInfo['href'] + "?see_lz=1",
meta = {'dont_redirect': True, 'articleInfo': articleInfo},
callback = self.parseArticleDetail,
errback = self.errorHandle
)
# 用于分析帖子的详细内容
# 这个网页的内容,就显得很常规,正常提取就好
def parseArticleDetail(self, response):
print(f"parseArticleDetail: statusCode = {response.status}, url = {response.url}")
contentLst = response.xpath("//div[contains(@id, 'post_content')]//text()").extract()
imgHrefLst = response.xpath("//div[contains(@id, 'post_content')]//img/@src").extract()
dateLst = response.xpath("//div[contains(@class, 'post_content_firstfloor')]//span[@class='tail-info']/text()").extract()
content = ''
for contentElem in contentLst:
content += contentElem.replace('\n', ',').replace(" ", '').strip()
content += ', '
print(f"content = {content}")
print(f"imgHrefLst = {imgHrefLst}")
articleInfo = response.meta['articleInfo']
articleItem = ArticleInfoItem()
articleItem['item_type'] = 'articleDetail'
articleItem['_id'] = articleInfo['id']
articleItem['title'] = articleInfo['title']
articleItem['author'] = articleInfo['author']
articleItem['content'] = content
articleItem['fromUrl'] = response.url
articleItem['picHrefLst'] = imgHrefLst
articleItem['date'] = dateLst[1]
yield articleItem
# 请求错误处理:可以打印,写文件,或者写到数据库中
def errorHandle(self, failure):
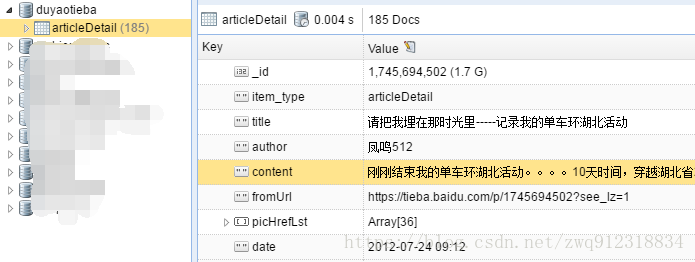
print(f"request error: {failure.value.response}")放两张爬取结果图(有了这个模版 ,以后就可以玩转贴吧了):
总结:分析网页时一定要仔细,不要轻易怀疑模块本身的问题,多实战,总结经验。
5. 导出帖子内容到文本文件中
import pymongo
# 初始化数据库
mongo_url = "127.0.0.1:27017"
DATABASE = "duyaotieba"
TABLE = "articleDetail"
client = pymongo.MongoClient(mongo_url)
db_des = client[DATABASE]
db_des_table = db_des[TABLE]
# 将数据写入到txt文件中
# 如果直接从mongod booster导出, 一旦有部分出现字段缺失,那么会出现结果错位的问题
# newline='' 的作用是防止结果数据中出现空行,专属于python3
with open(f"{DATABASE}_{TABLE}.txt", "w", newline='', encoding='utf-8') as fileWriter:
allRecordRes = db_des_table.find().sort('author', pymongo.DESCENDING)
# 写入多行数据
for record in allRecordRes:
print(f"record = {record}")
fileWriter.write(record['title'] + " " + record['date'] + " " + record['author'])
fileWriter.write("\n")
fileWriter.write(record['fromUrl'].replace("?see_lz=1", ''))
fileWriter.write("\n")
fileWriter.write(" " + record['content'])
fileWriter.write("\n")
fileWriter.write("\n")
fileWriter.write("\n")