前言
根据之前我写的 爬取及分析天猫商城冈本评论(一)数据获取 方法,爬取了冈本旗舰店的所有避孕套产品的公开评论,共计30824条。
这次对这3万多条评论去做数据分析前的预处理。
数据值处理
对于搜集到的评论数据,主要是针对三个字段去进行分析,就是“产品类型product_type”,“首次评论first_comment”,“评论日期comment_date”。所以数据的预处理主要针对这3个字段去进行。
(1)product_type
产品类型主要有两个问题:一是文本过长,二是有缺失值。
1、缺失值处理:

这个字段的缺失值有2997条。
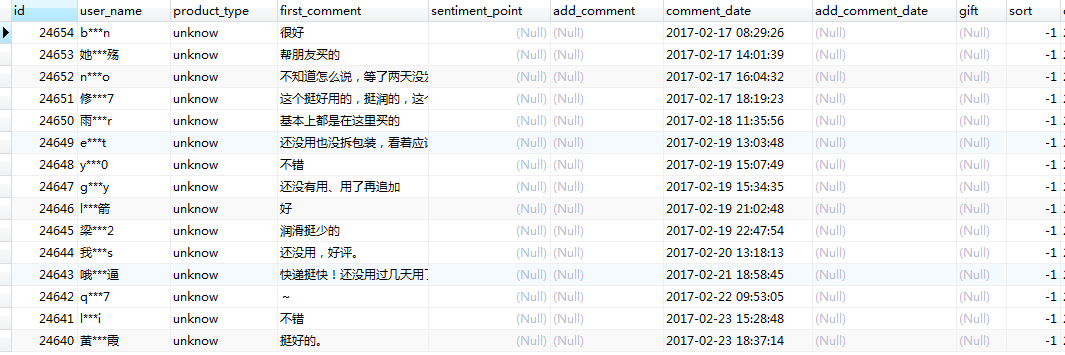
产品类型这个字段非常关键,没办法采用替代等方式去处理这些缺失值。暂时将这些缺失值的sort字段更新为-1,并在产品类型里面填入“unknown”。
UPDATE sp_okamoto_comment SET product_type='unknow',sort=-1 WHERE product_type='';
效果:

2、文本过长:

思路:分一个附表,用于记录具体的产品类型包含的产品。然后在主表中用附表的编码代替。
创建一个产品类型表:
CREATE TABLE `okamoto_product_type` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键ID自增', `product_type` varchar(100) DEFAULT NULL COMMENT '产品类型', `sort` int(11) NOT NULL COMMENT '序号', `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间', PRIMARY KEY (`id`), KEY `ky_sp_okamoto_comment_sort` (`sort`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='冈本产品类型表';
将产品类型插入表中:
INSERT INTO `okamoto_product_type`(`product_type`,sort) SELECT DISTINCT(product_type),1 FROM sp_okamoto_comment;
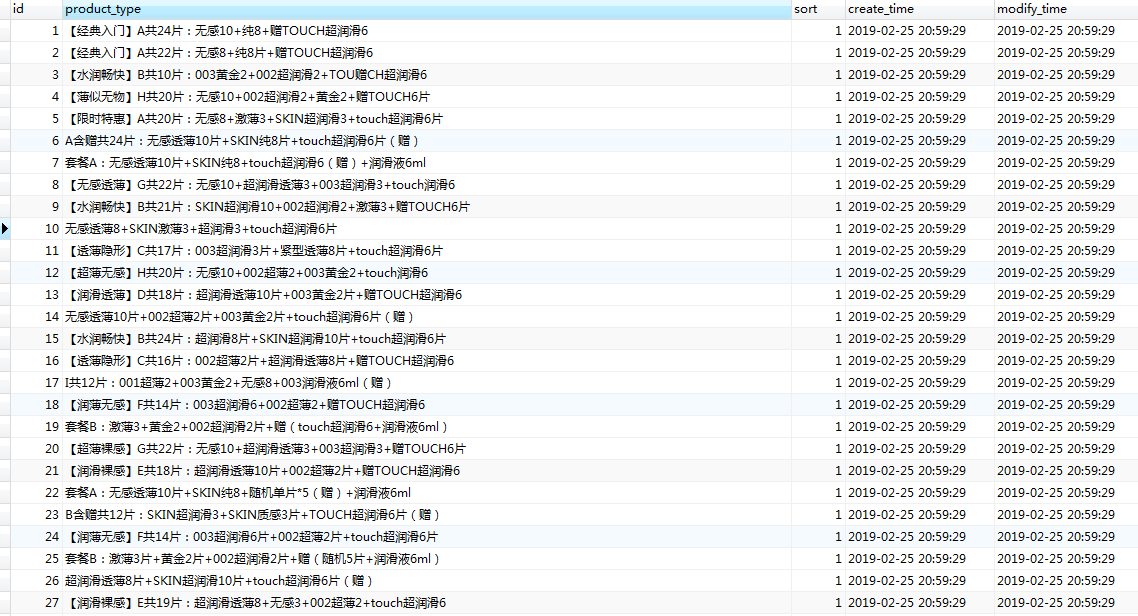
文本处理:删去没用的产品信息
UPDATE `okamoto_product_type` SET `product_type` = REPLACE(`product_type`, '颜色分类:', ''); UPDATE `okamoto_product_type` SET `product_type` = REPLACE(`product_type`, ';避孕套规格:其它规格;颜色:其它颜色 ', '');
产品类别表的效果图:
将主表的product_type也修改一下,并将它改为product_id
UPDATE sp_okamoto_comment s INNER JOIN okamoto_product_type o ON o.product_type=s.product_id SET s.product_id=o.id;
经过处理以后,一共有606个产品类别。因为有很多类别的销量很少,评论的样品量太少,所以暂定用销量在300以上的数据作为统计。这个是后话了。
SELECT COUNT(product_id) amount, product_id FROM sp_okamoto_comment GROUP BY product_id HAVING COUNT(product_id)>300 ORDER BY amount
(2)first_comment
缺失值和无用评论
评论的内容主要是:1,没有评论的,系统显示为:此用户没有填写评论!;2,无用评论,纯粹是凑字数的。第一类可以通过判断,在情感分析时跳开不管。第二类比较难通过文本判断,目前先不处理。
UPDATE sp_okamoto_comment SET `status`=-2 WHERE first_comment="此用户没有填写评论!";
受影响的行: 1223
时间: 0.066s
情感分析
通过pymysql对数据库内的评论进行读取,然后利用snowNLP进行情感分析,最后将分析出的结果,写入sentiment_point字段。
import pymysql from snownlp import SnowNLP def sql_snownlp(count_num): db = pymysql.connect(host="localhost",user="root",password="",db="python_data_sql",charset='utf8') cursor = db.cursor() for id_num in range(1,count_num): try: sql_select = "SELECT first_comment FROM sp_okamoto_comment WHERE id={id_num};".format_map(vars()) # 执行sql语句 cursor.execute(sql_select) res = cursor.fetchone() res = str(res).replace('(\'','').replace('\',)','')#查询出来的结果是一个带逗号的元组,例如('一直在这买的',),所以文本处理一下 s=SnowNLP(res) point=s.sentiments#情感分析,分数为0到1,1是最高分情感,0是最负面情感 sql_update = "UPDATE sp_okamoto_comment SET sentiment_point={point} WHERE id={id_num};".format_map(vars()) cursor.execute(sql_update) db.commit() except: print('第{id_num}条update失败'.format_map(vars())) # 发生错误时回滚 db.rollback() # 关闭数据库连接 db.close()
效果图:
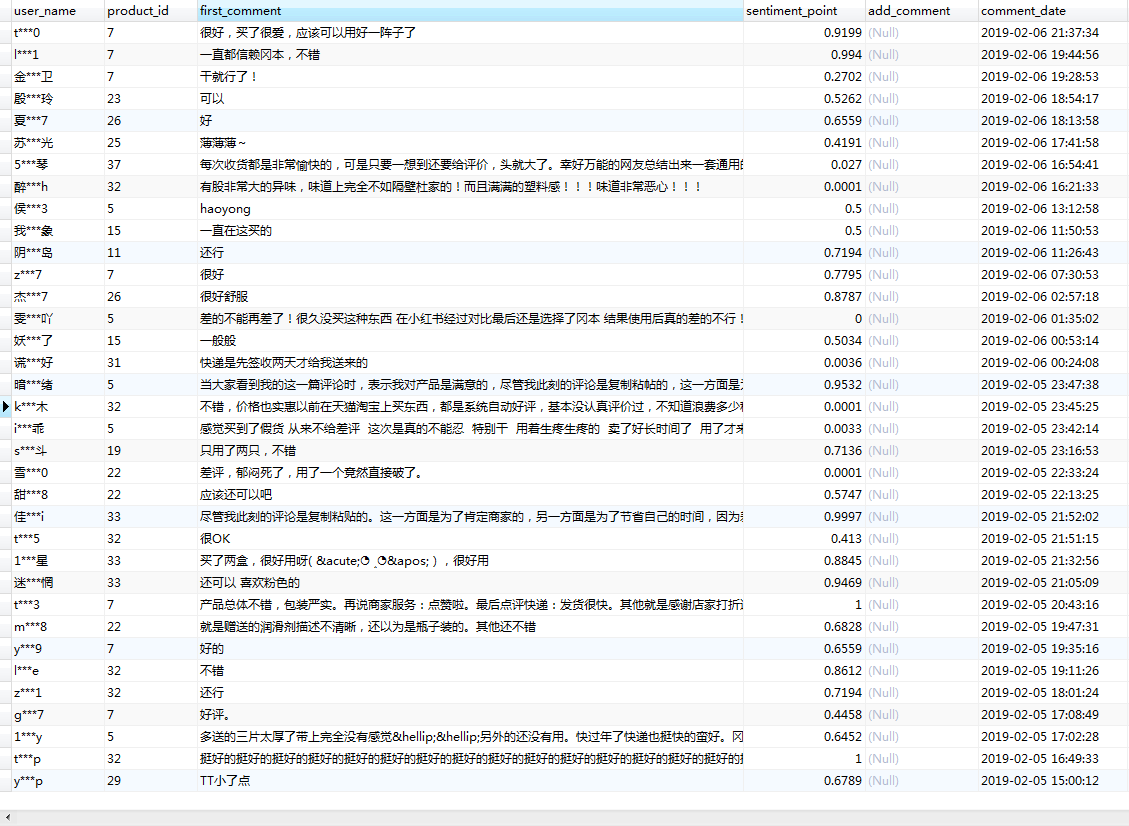
因为我在数据库里面设置了保留4位小数,所以会出现0的情况。再者就是snowNLP的准确率大概有8到9成,算是比较高的了,虽然有时候评分不准确。
(3)comment_date
对于评论的日期,一般不需要进行什么处理,爬下来的数据已经比较标准化了。
总结
数据处理的目的主要是将数据进行清洗,然后做标准化。对于评论的清洗,还是不太够。很对凑字数的评论暂时没有办法去处理它。再者就是snowNLP的情感分析,准确率没有办法达到100%。
但总体来说,数据处理的目的大致上还是达到了。下一步,我们就要对处理后的数据,进行分析,可视化,最后解读生成数据分析报告。