目录
1、登录天猫网站
2、搜索指定网页
3、进行第一次请求测试
4、进行第二次请求测试
5、怎么找到真正的true_url?
6、进行第三次请求测试
7、获取网页中的评论数据
8、翻页爬取(最终代码)
9、词云图的制作
1、登录天猫网站
对于有些网站,需要登陆后才有可能获取到网页中的数据。天猫网站就是其中的网站之一。
2、搜索指定网页
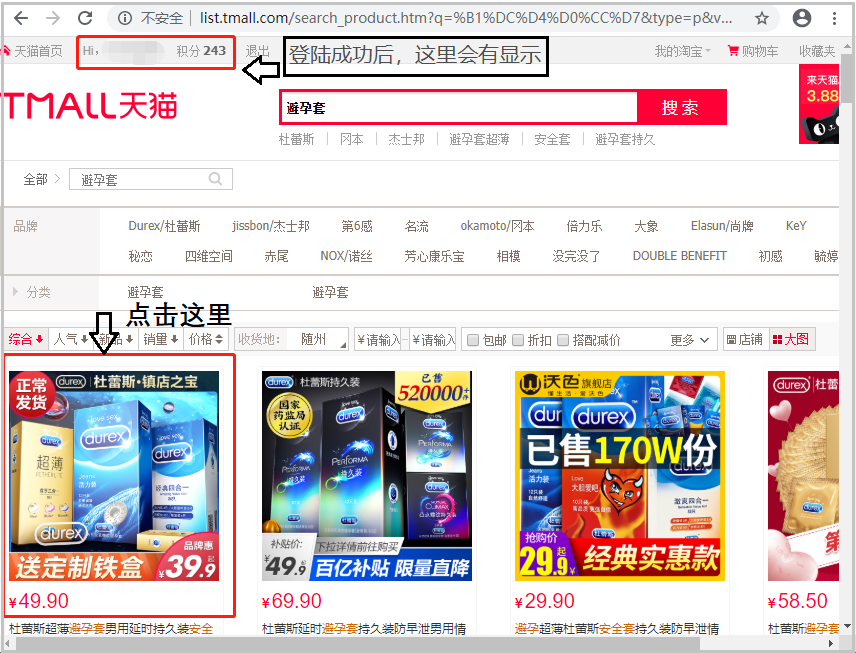
这里我想要爬取的是杜蕾斯。因此我们直接搜索“杜蕾斯”。由于“杜蕾斯”的卖家有很多,这里我们只选取页面的第一个图片,进行其中的“评论数据”的爬取。
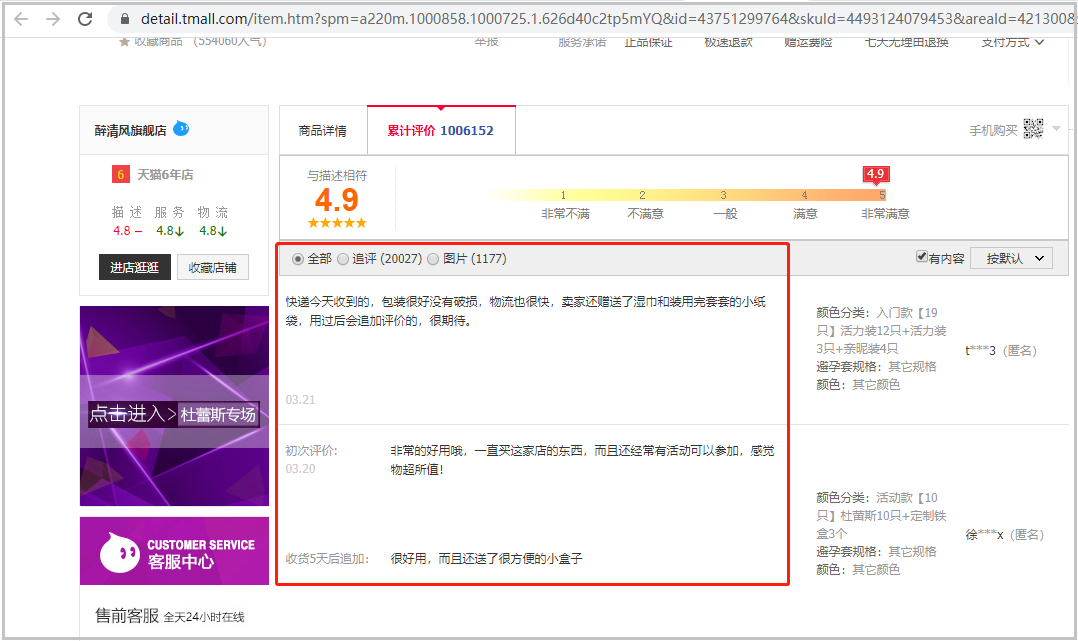
点击第一个图片,进入到我们最终想要爬取数据的网页。可以看到该页面有很多评论信息,这也是我们想要抓取的信息。
3、进行第一次请求测试
import pandas as pd
import requests
import re
import time
url = "https://detail.tmall.com/item.htm?spm=a220m.1000858.1000725.1.626d40c2tp5mYQ&id=43751299764&skuId=4493124079453&areaId=421300&user_id=2380958892&cat_id=2&is_b=1&rn=cc519a17bf9cefb59ac94f0351791648"
headers ={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
}
data = requests.get(url,headers=headers).text
data
结果如下:
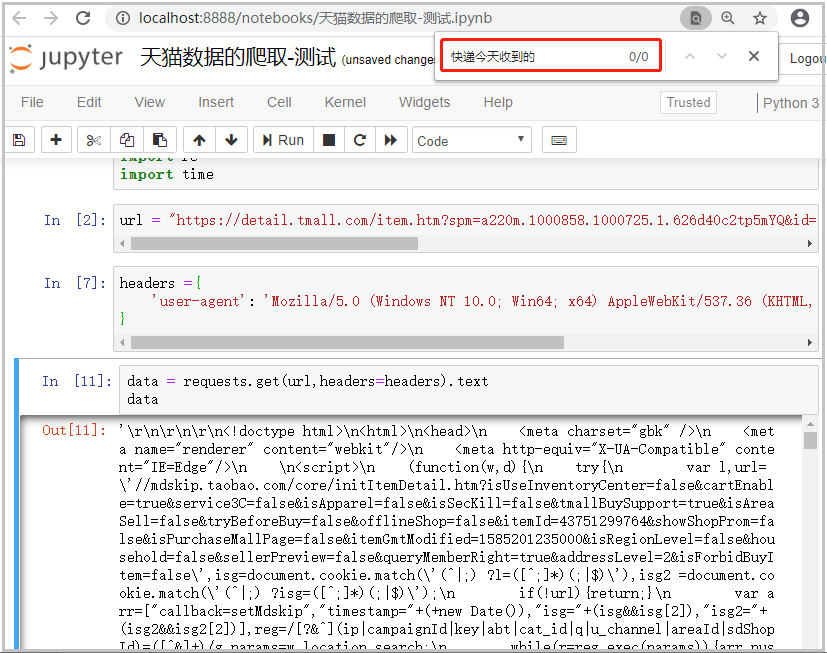
结果分析:明明评论信息就是在这个页面里面,我们这样请求,怎么得不到数据呢?难道是没有带着cokkies发送请求?我们接下来尝试带着cokkies发送请求。
4、进行第二次请求测试
import pandas as pd
import requests
import re
import time
url = "https://detail.tmall.com/item.htm?spm=a220m.1000858.1000725.1.626d40c2tp5mYQ&id=43751299764&skuId=4493124079453&areaId=421300&user_id=2380958892&cat_id=2&is_b=1&rn=cc519a17bf9cefb59ac94f0351791648"
headers ={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
}
data = requests.get(url,headers=headers).text
data
结果如下:
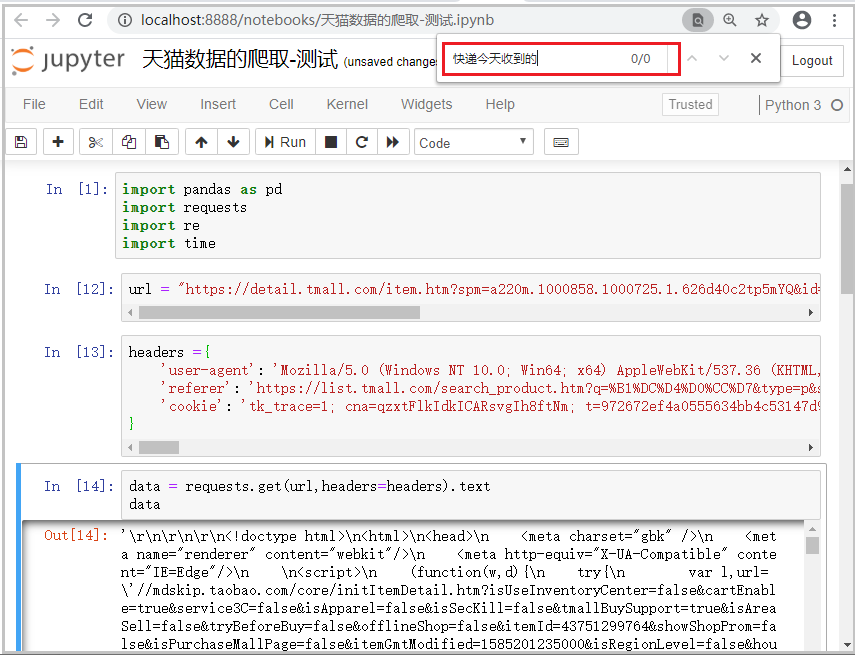
结果分析:不科学哈!这次我已经带着cokkies发送了请求呀,为什么还是获取不到我们想要的数据,会不会“评论数据”根本就不再这个url中呢?那么真正的true_url究竟在哪里呢?下面我们慢慢解密。
5、怎么找到真正的true_url?
1)点击【鼠标右键】–>点击【检查】
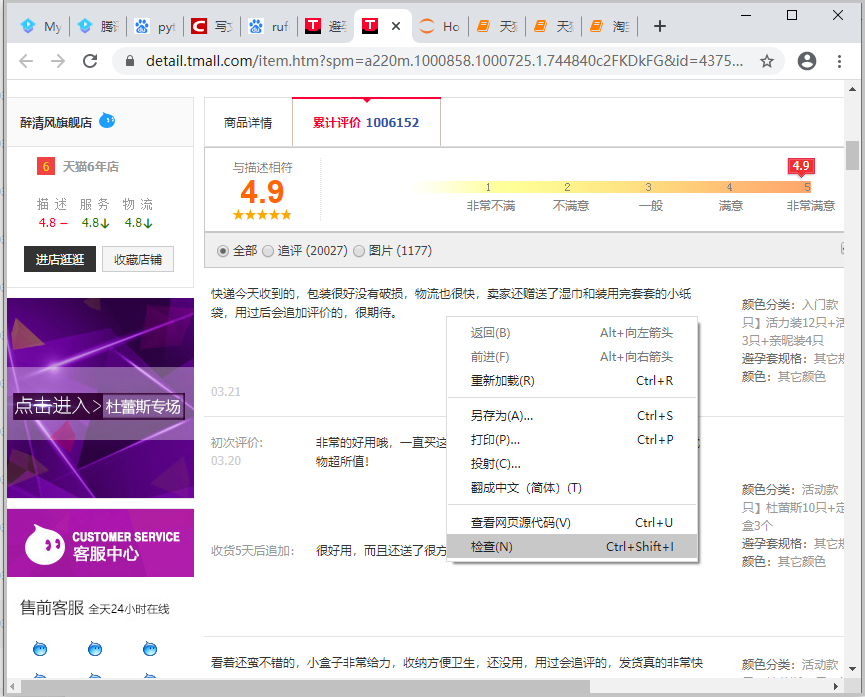
2)点击【Network】

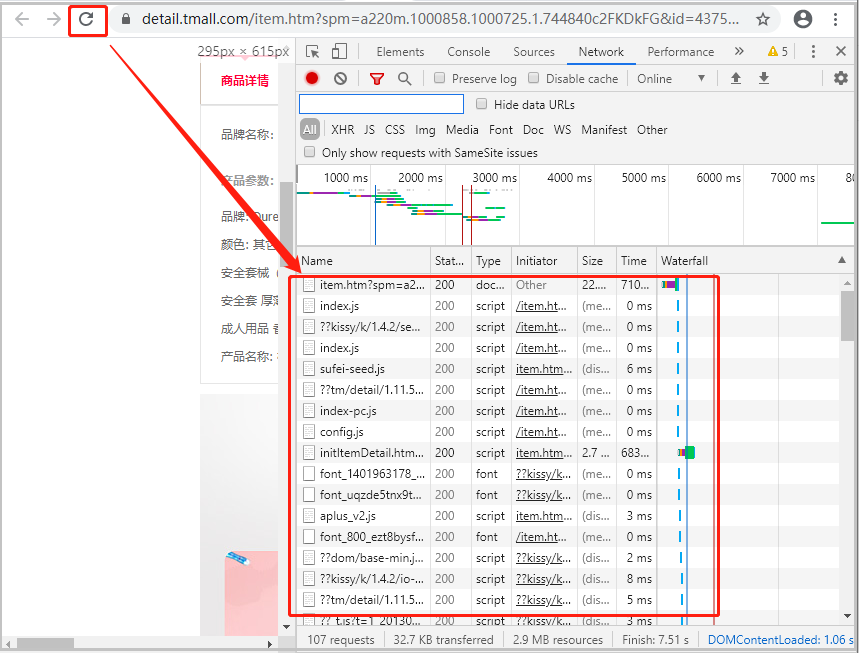
3)刷新网页
刷新网页以后,可以发现【红色方框】中,多了很多请求的url。
4)点击【搜索按钮】,进行评论数据搜索,寻找trul_url
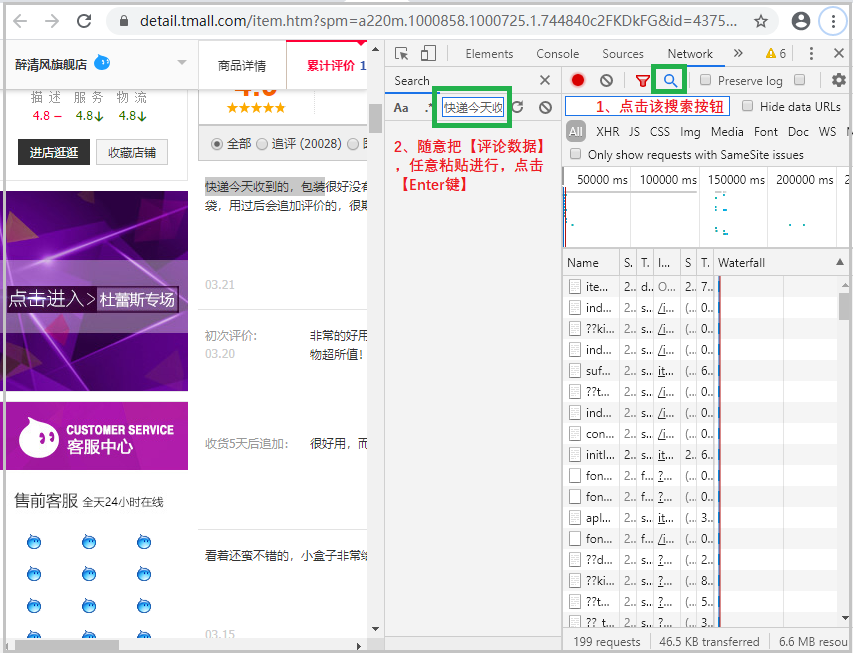
当出现如下界面后,按照如图所示操作即可。
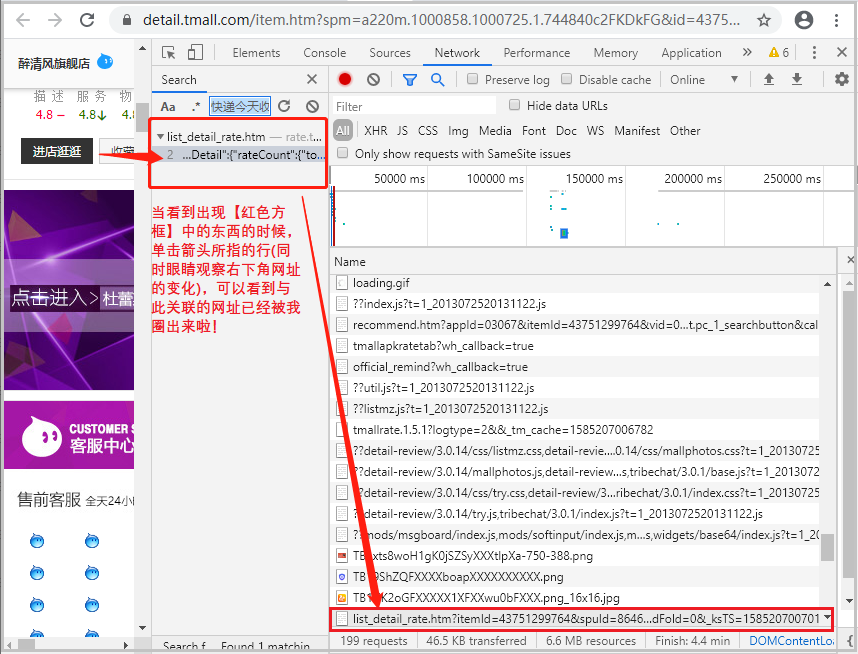
紧接着,查看该请求所对应的Request URL,就是我们最终要找的true_url。信不信吗?下面可以试试。
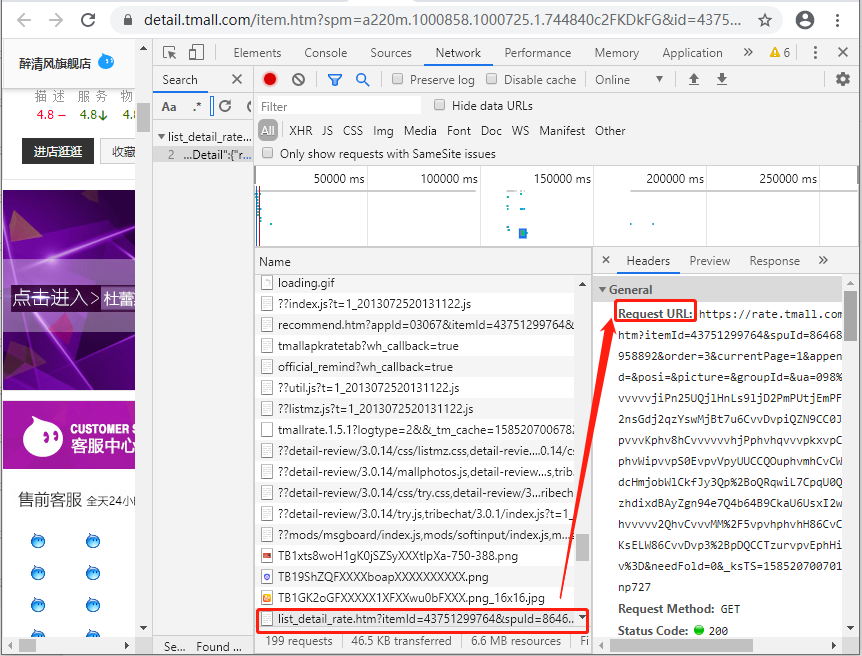
6、进行第三次请求测试
首先我们在上述图的基础上,顺着Request URL往下面找,获取Request Headers中user-agent、referer、cokie这3样东西。
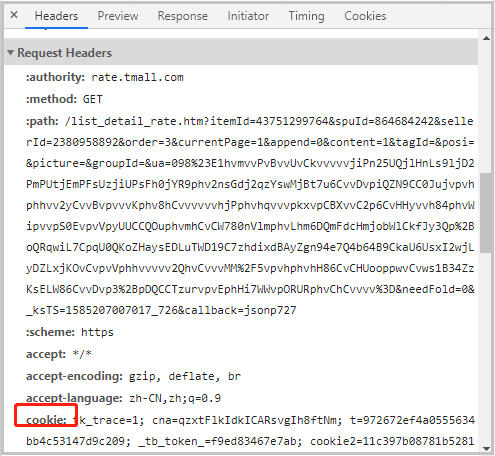
反正都在Request Headers中,我们将这3样东西,一一粘贴到headers中,形成一个字典格式的键值对。然后我们发起其三次请求。
true_url = "https://rate.tmall.com/list_detail_rate.htm?itemId=43751299764&spuId=864684242&sellerId=2380958892&order=3¤tPage=1&append=0&content=1&tagId=&posi=&picture=&groupId=&ua=098%23E1hvmvvPvBvvUvCkvvvvvjiPn25UQjlHnLs9ljD2PmPUtjEmPFsUzjiUPsFh0jYR9phv2nsGdj2qzYswMjBt7u6CvvDvpiQZN9CC0Jujvpvhphhvv2yCvvBvpvvvKphv8hCvvvvvvhjPphvhqvvvpkxvpCBXvvC2p6CvHHyvvh84phvWipvvpS0EvpvVpyUUCCQOuphvmhCvCW780nVlmphvLhm6DQmFdcHmjobWlCkfJy3Qp%2BoQRqwiL7CpqU0QKoZHaysEDLuTWD19C7zhdixdBAyZgn94e7Q4b64B9CkaU6UsxI2wjLyDZLxjKOvCvpvVphhvvvvv2QhvCvvvMM%2F5vpvhphvhH86CvCHUooppwvCvws1B34ZzKsELW86CvvDvp3%2BpDQCCTzurvpvEphHi7WWvpORURphvChCvvvv%3D&needFold=0&_ksTS=1585207007017_726&callback=jsonp727"
headers ={
# 用的哪个浏览器
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36',
# 从哪个页面发出的数据申请,每个网站可能略有不同
'referer': 'https://detail.tmall.com/item.htm?spm=a220m.1000858.1000725.1.744840c2FKDkFG&id=43751299764&skuId=4493124079453&areaId=421300&user_id=2380958892&cat_id=2&is_b=1&rn=388ceadeefb8d85e5bae2d83bd0b732a',
# 哪个用户想要看数据,是游客还是注册用户,建议使用登录后的cookie
'cookie': 'tk_trace=1; cna=qzxtFlkIdkICARsvgIh8ftNm; t=972672ef4a0555634bb4c53147d9c209; _tb_token_=f9ed83467e7ab; cookie2=11c397b08781b52815002215ea5d1ad4; dnk=huang%5Cu81F3%5Cu5C0A; tracknick=huang%5Cu81F3%5Cu5C0A; lid=huang%E8%87%B3%E5%B0%8A; lgc=huang%5Cu81F3%5Cu5C0A; uc1=cookie16=UIHiLt3xCS3yM2h4eKHS9lpEOw%3D%3D&pas=0&existShop=false&cookie15=UtASsssmOIJ0bQ%3D%3D&cookie14=UoTUP2D4F2IHjA%3D%3D&cookie21=VFC%2FuZ9aiKCaj7AzMHh1; uc3=id2=UU8BrRJJcs7Z0Q%3D%3D&lg2=VT5L2FSpMGV7TQ%3D%3D&vt3=F8dBxd9hhEzOWS%2BU9Dk%3D&nk2=CzhMCY1UcRnL; _l_g_=Ug%3D%3D; uc4=id4=0%40U22GV4QHIgHvC14BqrCleMrzYb3K&nk4=0%40CX8JzNJ900MInLAoQ2Z33x1zsSo%3D; unb=2791663324; cookie1=BxeNCqlvVZOUgnKrsmThRXrLiXfQF7m%2FKvrURubODpk%3D; login=true; cookie17=UU8BrRJJcs7Z0Q%3D%3D; _nk_=huang%5Cu81F3%5Cu5C0A; sgcookie=E53NoUsJWtrYT7Pyx14Px; sg=%E5%B0%8A41; csg=8d6d2aae; enc=VZMEO%2BOI3U59DBFwyF9LE3kQNM84gfIKeZFLokEQSzC5TubpmVCJlS8olhYmgHiBe15Rvd8rsOeqeC1Em9GfWA%3D%3D; l=dBLKMV6rQcVJihfaBOfgSVrsTkQ9UIRb8sPrQGutMICP9ZCwNsyFWZ4Kb-8eCnGVHsMvR3oGfmN0BDTHXyIVokb4d_BkdlkmndC..; isg=BK2tcrfNj3CNMWubo5GaxlajvEknCuHcPbxLgO-yO8QhZswYt1ujrPVwUDqAZvmU'
}
data = requests.get(true_url,headers=headers).text
data
结果如下:
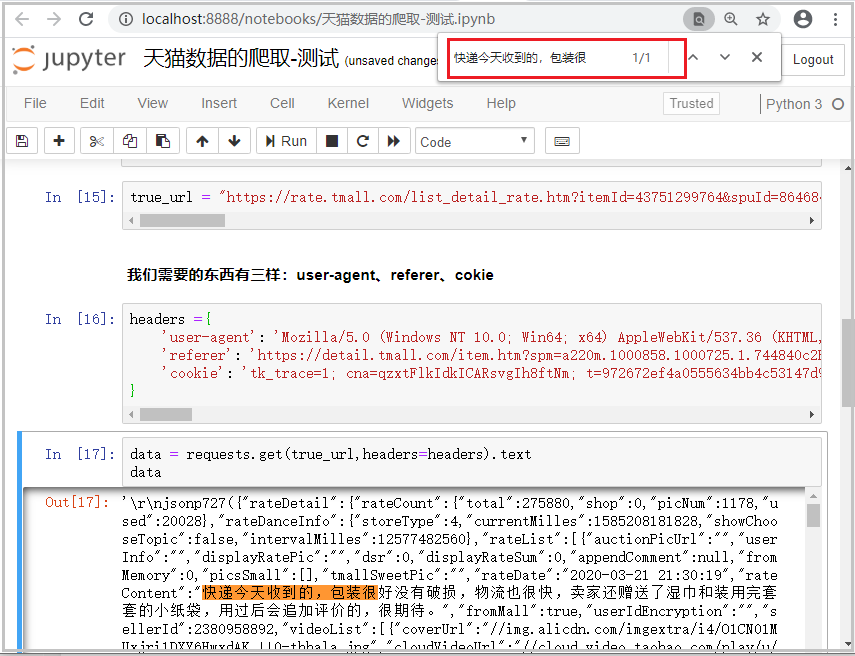
结果分析:经过一番波折,我们最终找到了我们想要获取的数据,接下来的话,就是我们进行页面解析的工作了。其实在真实的爬虫环境中,可能会遇到更多的反爬措施,真正难得不是解析网页,而是分析网页和反爬。
7、获取网页中的评论数据
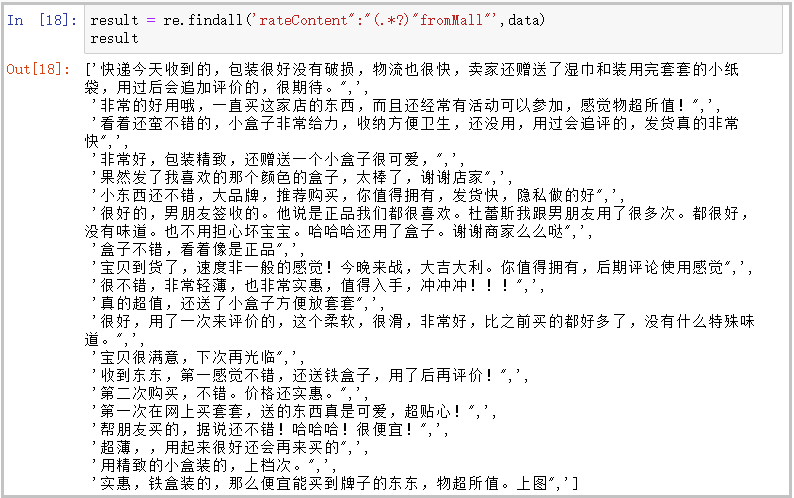
result = re.findall('rateContent":"(.*?)"fromMall"',data)
result
结果如下:
8、翻页爬取(最终代码)
我们的目的肯定不只是爬取一个页面的评论数据,而是进行翻页爬取,我们需要仔细观察true_url中,有一个【currentPage=1】参数,当这个数字变化的时候,对应的页面也就发生的变化,基于此,我们将完整的爬虫代码写在下面。
import pandas as pd
import requests
import re
import time
data_list = []
for i in range(1,300,1):
print("正在爬取第" + str(i) + "页")
url = first + str(i) + last
headers ={
# 用的哪个浏览器
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36',
# 从哪个页面发出的数据申请,每个网站可能略有不同
'referer': 'https://detail.tmall.com/item.htm?spm=a220m.1000858.1000725.1.744840c2FKDkFG&id=43751299764&skuId=4493124079453&areaId=421300&user_id=2380958892&cat_id=2&is_b=1&rn=388ceadeefb8d85e5bae2d83bd0b732a',
# 哪个用户想要看数据,是游客还是注册用户,建议使用登录后的cookie
'cookie': 'tk_trace=1; cna=qzxtFlkIdkICARsvgIh8ftNm; t=972672ef4a0555634bb4c53147d9c209; _tb_token_=f9ed83467e7ab; cookie2=11c397b08781b52815002215ea5d1ad4; dnk=huang%5Cu81F3%5Cu5C0A; tracknick=huang%5Cu81F3%5Cu5C0A; lid=huang%E8%87%B3%E5%B0%8A; lgc=huang%5Cu81F3%5Cu5C0A; uc1=cookie16=UIHiLt3xCS3yM2h4eKHS9lpEOw%3D%3D&pas=0&existShop=false&cookie15=UtASsssmOIJ0bQ%3D%3D&cookie14=UoTUP2D4F2IHjA%3D%3D&cookie21=VFC%2FuZ9aiKCaj7AzMHh1; uc3=id2=UU8BrRJJcs7Z0Q%3D%3D&lg2=VT5L2FSpMGV7TQ%3D%3D&vt3=F8dBxd9hhEzOWS%2BU9Dk%3D&nk2=CzhMCY1UcRnL; _l_g_=Ug%3D%3D; uc4=id4=0%40U22GV4QHIgHvC14BqrCleMrzYb3K&nk4=0%40CX8JzNJ900MInLAoQ2Z33x1zsSo%3D; unb=2791663324; cookie1=BxeNCqlvVZOUgnKrsmThRXrLiXfQF7m%2FKvrURubODpk%3D; login=true; cookie17=UU8BrRJJcs7Z0Q%3D%3D; _nk_=huang%5Cu81F3%5Cu5C0A; sgcookie=E53NoUsJWtrYT7Pyx14Px; sg=%E5%B0%8A41; csg=8d6d2aae; enc=VZMEO%2BOI3U59DBFwyF9LE3kQNM84gfIKeZFLokEQSzC5TubpmVCJlS8olhYmgHiBe15Rvd8rsOeqeC1Em9GfWA%3D%3D; l=dBLKMV6rQcVJihfaBOfgSVrsTkQ9UIRb8sPrQGutMICP9ZCwNsyFWZ4Kb-8eCnGVHsMvR3oGfmN0BDTHXyIVokb4d_BkdlkmndC..; isg=BK2tcrfNj3CNMWubo5GaxlajvEknCuHcPbxLgO-yO8QhZswYt1ujrPVwUDqAZvmU'
}
try:
data = requests.get(url,headers = headers).text
time.sleep(10)
result = re.findall('rateContent":"(.*?)"fromMall"',data)
data_list.extend(result)
except:
print("本页爬取失败")
df = pd.DataFrame()
df["评论"] = data_list
df.to_excel("评论_汇总.xlsx")
结果如下:

9、词云图的制作
import numpy as np
import pandas as pd
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from imageio import imread
import warnings
warnings.filterwarnings("ignore")
# 读取数据
df = pd.read_excel("评论_汇总.xlsx")
df.head()
# 利用jieba进行分析操作
df["评论"] = df["评论"].apply(jieba.lcut)
df.head()
# 去除停用词操作
with open("stopword.txt","r",encoding="gbk") as f:
stop = f.read() # 返回的是一个字符串
stop = stop.split() # 这里得到的是一个列表.split()会将空格,\n,\t进行切分,因此我们可以将这些加到停用词当中
stop = stop + [" ","\n","\t"]
df_after = df["评论"].apply(lambda x: [i for i in x if i not in stop])
df_after.head()
# 词频统计
all_words = []
for i in df_after:
all_words.extend(i)
word_count = pd.Series(all_words).value_counts()
word_count[:10]
# 绘制词云图
# 1、读取背景图片
back_picture = imread(r"G:\6Tipdm\wordcloud\alice_color.png")
# 2、设置词云参数
wc = WordCloud(font_path="G:\\6Tipdm\\wordcloud\\simhei.ttf",
background_color="white",
max_words=2000,
mask=back_picture,
max_font_size=200,
random_state=42
)
wc2 = wc.fit_words(word_count)
# 3、绘制词云图
plt.figure(figsize=(16,8))
plt.imshow(wc2)
plt.axis("off")
plt.show()
wc.to_file("ciyun.png")
结果如下:

