目录标题
1、数据导入
# 导入必备工具包
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
import re
import jieba.posseg as psg
import numpy as np
# 设置显示风格
plt.style.use('fivethirtyeight')
data = pd.read_csv("F:/data/bibi.csv",encoding='gbk')
data.head()
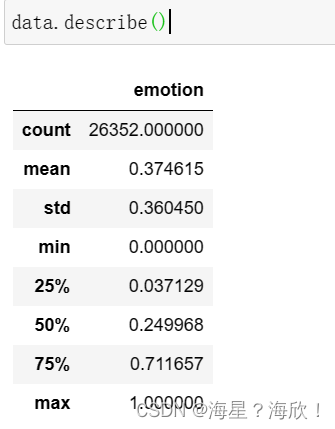
data.describe()
data.shape #(32703, 2)

2、数据预处理
删空值:
data.isnull().sum()
data = data.dropna()#直接删空值
data.isnull().sum()
data.shape #(32702, 2)
评论去重:
#统计重复数字
data[['content', 'title']].duplicated().sum()
#评论去重
data = data[[ 'title','content']].drop_duplicates()
data.shape (31539, 2)
去掉文本中数字字母以及“B站”“b站”
# 去掉评论中的数字、字母,以及“B站”“b站”
content = data['content']
# 编译匹配模式
pattern = re.compile('[a-zA-Z0-9]|B站|b站')
# re.sub用于替换字符串中的匹配项
content = content.apply(lambda x : pattern.sub('',x))
content

3、评论分词
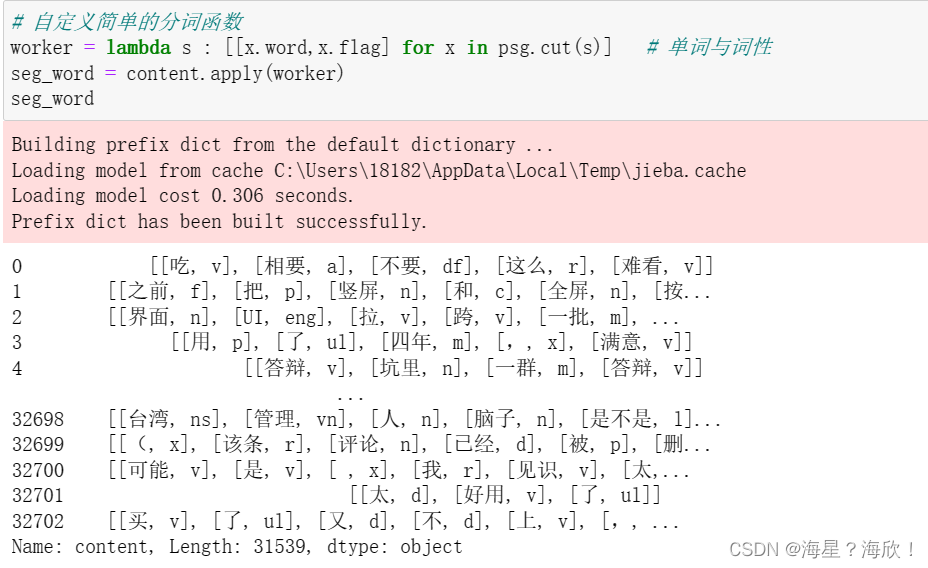
# 自定义简单的分词函数
worker = lambda s : [[x.word,x.flag] for x in psg.cut(s)] # 单词与词性
seg_word = content.apply(worker)
seg_word
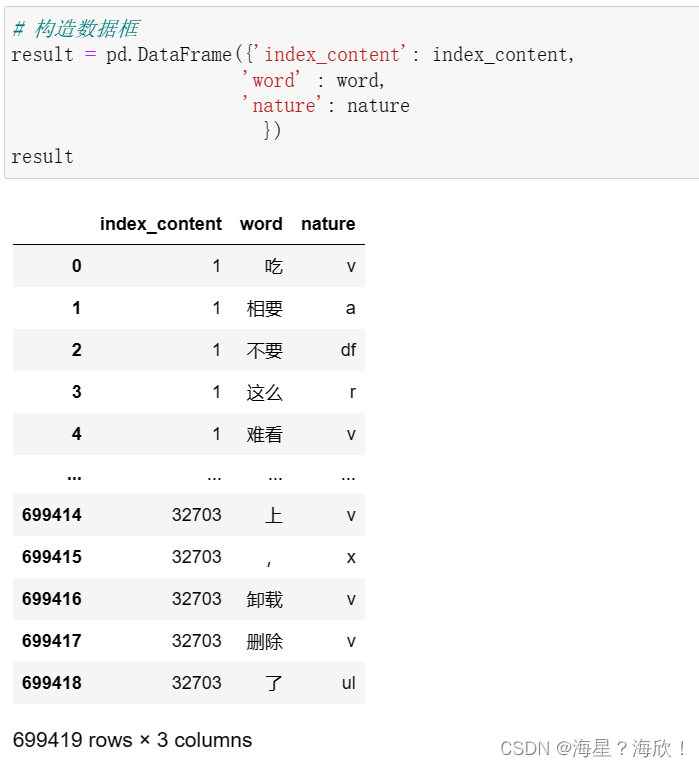
# 将词语转化为数据框形式,一列是词,一列是词语所在的句子id,最后一列是词语在该句子中的位置
# 每一评论中词的个数
n_word = seg_word.apply(lambda x: len(x))
# 构造词语所在的句子id
n_content = [[x+1]*y for x,y in zip(list(seg_word.index), list(n_word))]
# 将嵌套的列表展开,作为词所在评论的id
index_content = sum(n_content, [])
seg_word = sum(seg_word,[])
# 词
word = [x[0] for x in seg_word]
# 词性
nature = [x[1] for x in seg_word]
# 构造数据框
result = pd.DataFrame({
'index_content': index_content,
'word' : word,
'nature': nature
})
result
删除标点符号
# 删除标点符号
data = data[result['nature'] != 'x']
data
删除停用词
# # 删除停用词
# # 加载停用词
# stop_path = open('data/stoplist.txt','r',encoding='utf-8')
# stop = [x.replace('\n','') for x in stop_path.readlines()]
# # 得到非停用词序列
# word = list(set(word) - set(stop))
# # 判断表格中的单词列是否在非停用词列中
# result = result[result['word'].isin(word)]
问题:停用词列表没找到
备份
#备份
data1 = data
句子长度
# 在数据中添加新的句子长度列, 每个元素的值都是对应的句子列的长度
data1["content_length"] = list(map(lambda x: len(x), data1["content"]))
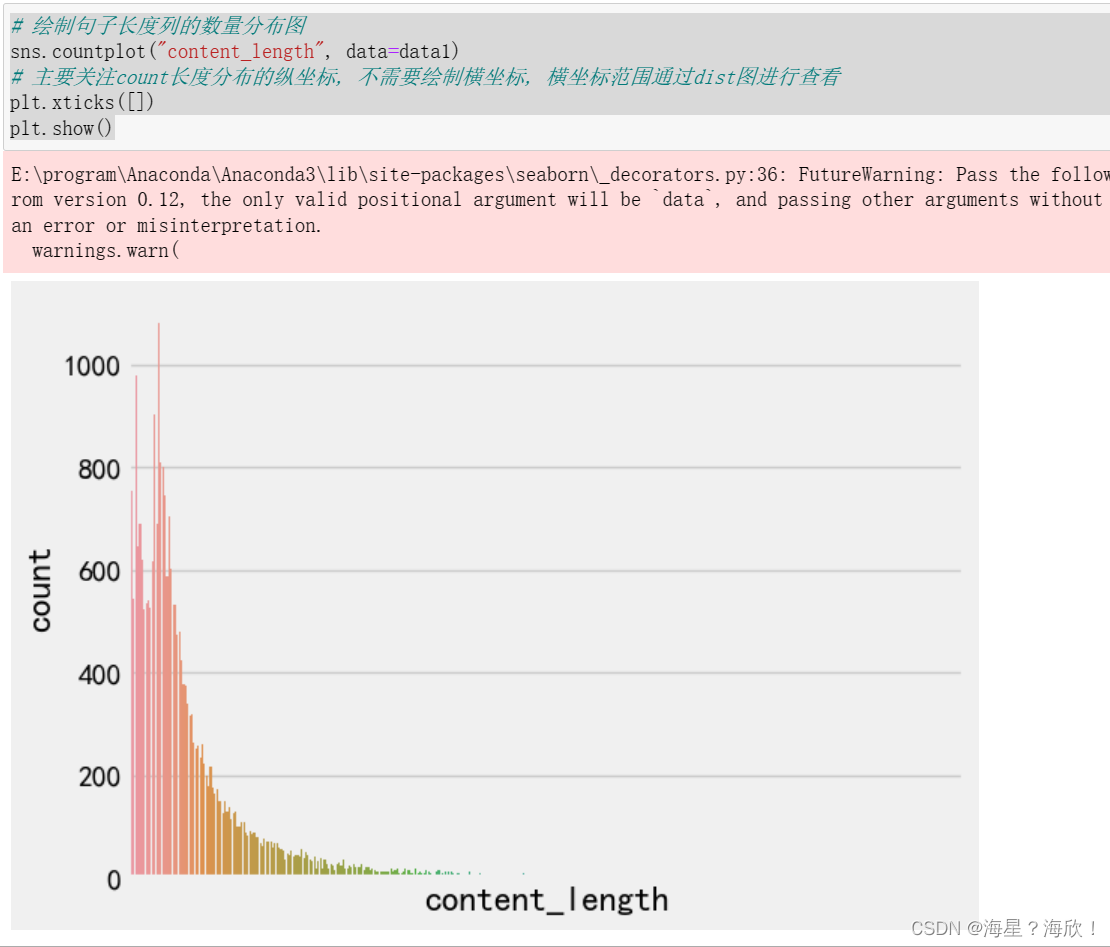
# 绘制句子长度列的数量分布图
sns.countplot("content_length", data=data1)
# 主要关注count长度分布的纵坐标, 不需要绘制横坐标, 横坐标范围通过dist图进行查看
plt.xticks([])
plt.show()
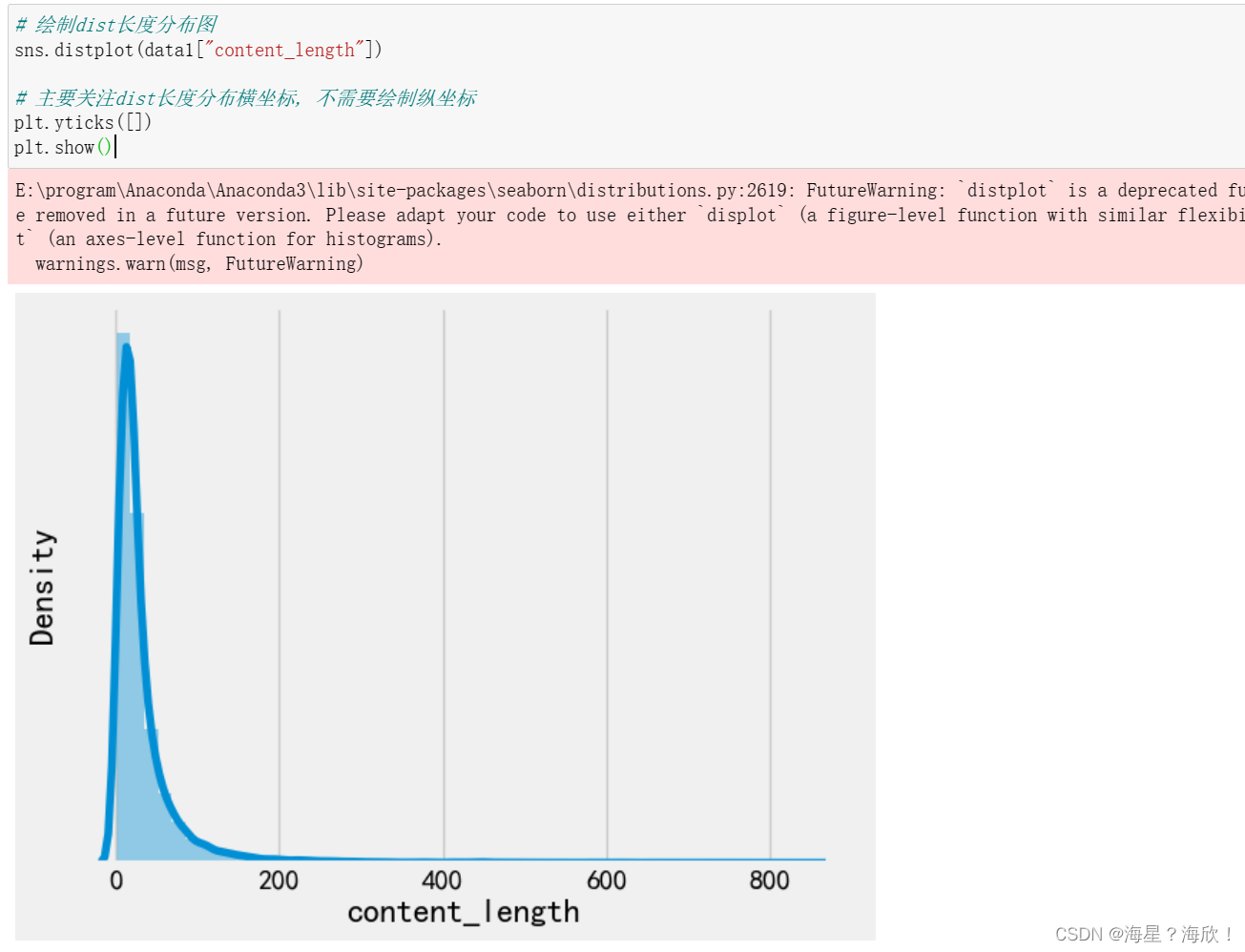
# 绘制dist长度分布图
sns.distplot(data1["content_length"])
# 主要关注dist长度分布横坐标, 不需要绘制纵坐标
plt.yticks([])
plt.show()
4、情感分
from snownlp import SnowNLP
data.isnull().sum() #一定要确保没有空值
data['emotion'] = data['content'].apply(lambda x:SnowNLP(x).sentiments)
data.describe()
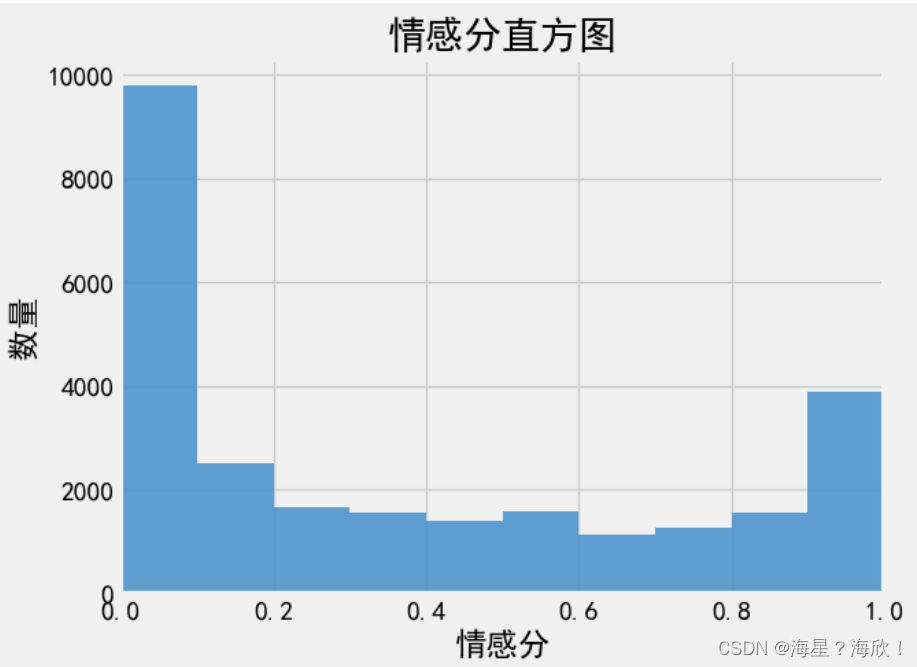
情感直方图
#情感分直方图
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
bins=np.arange(0,1.1,0.1)
plt.hist(data['emotion'],bins,color='#4F94CD',alpha=0.9)
plt.xlim(0,1)
plt.xlabel('情感分')
plt.ylabel('数量')
plt.title('情感分直方图')
plt.show()
关键词提取
#关键词top20
from jieba import analyse
key_words = jieba.analyse.extract_tags(sentence=text, topK=20, withWeight=True, allowPOS=())
key_words

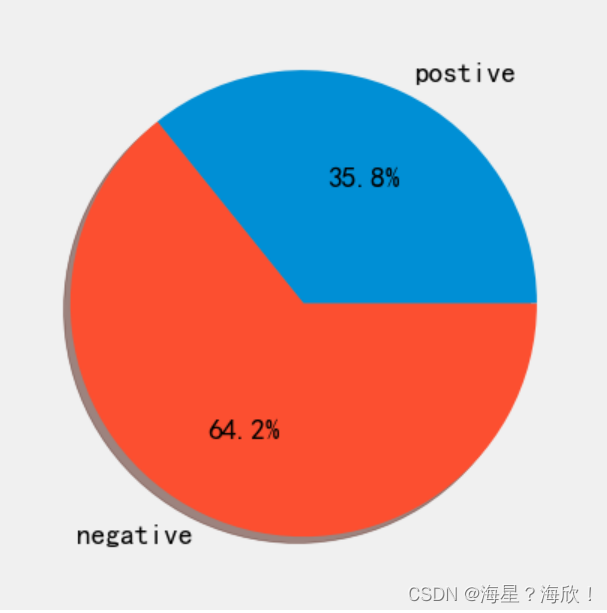
#计算积极评论与消极评论各自的数目
pos = 0
neg = 0
for i in data['emotion']:
if i >= 0.5:
pos += 1
else:
neg += 1
print('积极评论,消极评论数目分别为:')
pos,neg

# 积极评论占比
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
pie_labels='postive','negative'
plt.pie([pos,neg],labels=pie_labels,autopct='%1.1f%%',shadow=True)
plt.show()
#获取消极评论数据
data2=data[data['emotion']<0.5]
data2.head(10)
#获取积极评论数据
data3=data[data['emotion']>=0.5]
data3.head(10)
#消极评论关键词top10
key_words = jieba.analyse.extract_tags(sentence=text2, topK=20, withWeight=True, allowPOS=())
key_words
#积极评论关键词top10
key_words = jieba.analyse.extract_tags(sentence=text3, topK=20, withWeight=True, allowPOS=())
key_words
不同词汇数据
# 导入jieba用于分词
# 导入chain方法用于扁平化列表
import jieba
from itertools import chain
# 进行训练集的句子进行分词, 并统计出不同词汇的总数
vocab = set(chain(*map(lambda x: jieba.lcut(x), data1["content"])))
print("训练集共包含不同词汇总数为:", len(vocab))
5、生成词云图
# 使用jieba中的词性标注功能
import jieba.posseg as pseg
def get_a_list(text):
"""用于获取形容词列表"""
# 使用jieba的词性标注方法切分文本,获得具有词性属性flag和词汇属性word的对象,
# 从而判断flag是否为形容词,来返回对应的词汇
r = []
for g in pseg.lcut(text):
if g.flag == "a":
r.append(g.word)
return r
# 导入绘制词云的工具包
from wordcloud import WordCloud
def get_word_cloud(keywords_list):
# 实例化绘制词云的类, 其中参数font_path是字体路径, 为了能够显示中文,
# max_words指词云图像最多显示多少个词, background_color为背景颜色
wordcloud = WordCloud(font_path="F:/data/SimHei.ttf",max_words=100, background_color="white")
# 将传入的列表转化成词云生成器需要的字符串形式
keywords_string = " ".join(keywords_list)
# 生成词云
wordcloud.generate(keywords_string)
# 绘制图像并显示
plt.figure()
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
积极评论词云图
###积极评论词云图
p_data = data3["content"]
# 对正样本的每个句子的形容词
p_a_vocab = chain(*map(lambda x: get_a_list(x), p_data))
#print(train_p_n_vocab)
# 调用绘制词云函数
get_word_cloud(p_a_vocab)

消极评论词云图
n_data = data2["content"]
# 对正样本的每个句子的形容词
n_a_vocab = chain(*map(lambda x: get_a_list(x), p_data))
#print(train_p_n_vocab)
# 调用绘制词云函数
get_word_cloud(n_a_vocab)

总评论数据的词云图
data1.head()
all_data = data1["content"]
# 对正样本的每个句子的形容词
n_a_vocab = chain(*map(lambda x: get_a_list(x), p_data))
#print(train_p_n_vocab)
# 调用绘制词云函数
get_word_cloud(n_a_vocab)
